2025-12-09
This commit is contained in:
+1
-1
@@ -1,5 +1,5 @@
|
||||
{
|
||||
"last_check": "2025-11-26 10:56:41.294043",
|
||||
"last_check": "2025-12-03 12:31:05.644123",
|
||||
"backup_date": "",
|
||||
"update_ready": false,
|
||||
"ignore": false,
|
||||
|
||||
@@ -1,674 +0,0 @@
|
||||
GNU GENERAL PUBLIC LICENSE
|
||||
Version 3, 29 June 2007
|
||||
|
||||
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
||||
Everyone is permitted to copy and distribute verbatim copies
|
||||
of this license document, but changing it is not allowed.
|
||||
|
||||
Preamble
|
||||
|
||||
The GNU General Public License is a free, copyleft license for
|
||||
software and other kinds of works.
|
||||
|
||||
The licenses for most software and other practical works are designed
|
||||
to take away your freedom to share and change the works. By contrast,
|
||||
the GNU General Public License is intended to guarantee your freedom to
|
||||
share and change all versions of a program--to make sure it remains free
|
||||
software for all its users. We, the Free Software Foundation, use the
|
||||
GNU General Public License for most of our software; it applies also to
|
||||
any other work released this way by its authors. You can apply it to
|
||||
your programs, too.
|
||||
|
||||
When we speak of free software, we are referring to freedom, not
|
||||
price. Our General Public Licenses are designed to make sure that you
|
||||
have the freedom to distribute copies of free software (and charge for
|
||||
them if you wish), that you receive source code or can get it if you
|
||||
want it, that you can change the software or use pieces of it in new
|
||||
free programs, and that you know you can do these things.
|
||||
|
||||
To protect your rights, we need to prevent others from denying you
|
||||
these rights or asking you to surrender the rights. Therefore, you have
|
||||
certain responsibilities if you distribute copies of the software, or if
|
||||
you modify it: responsibilities to respect the freedom of others.
|
||||
|
||||
For example, if you distribute copies of such a program, whether
|
||||
gratis or for a fee, you must pass on to the recipients the same
|
||||
freedoms that you received. You must make sure that they, too, receive
|
||||
or can get the source code. And you must show them these terms so they
|
||||
know their rights.
|
||||
|
||||
Developers that use the GNU GPL protect your rights with two steps:
|
||||
(1) assert copyright on the software, and (2) offer you this License
|
||||
giving you legal permission to copy, distribute and/or modify it.
|
||||
|
||||
For the developers' and authors' protection, the GPL clearly explains
|
||||
that there is no warranty for this free software. For both users' and
|
||||
authors' sake, the GPL requires that modified versions be marked as
|
||||
changed, so that their problems will not be attributed erroneously to
|
||||
authors of previous versions.
|
||||
|
||||
Some devices are designed to deny users access to install or run
|
||||
modified versions of the software inside them, although the manufacturer
|
||||
can do so. This is fundamentally incompatible with the aim of
|
||||
protecting users' freedom to change the software. The systematic
|
||||
pattern of such abuse occurs in the area of products for individuals to
|
||||
use, which is precisely where it is most unacceptable. Therefore, we
|
||||
have designed this version of the GPL to prohibit the practice for those
|
||||
products. If such problems arise substantially in other domains, we
|
||||
stand ready to extend this provision to those domains in future versions
|
||||
of the GPL, as needed to protect the freedom of users.
|
||||
|
||||
Finally, every program is threatened constantly by software patents.
|
||||
States should not allow patents to restrict development and use of
|
||||
software on general-purpose computers, but in those that do, we wish to
|
||||
avoid the special danger that patents applied to a free program could
|
||||
make it effectively proprietary. To prevent this, the GPL assures that
|
||||
patents cannot be used to render the program non-free.
|
||||
|
||||
The precise terms and conditions for copying, distribution and
|
||||
modification follow.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
"This License" refers to version 3 of the GNU General Public License.
|
||||
|
||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
"The Program" refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as "you". "Licensees" and
|
||||
"recipients" may be individuals or organizations.
|
||||
|
||||
To "modify" a work means to copy from or adapt all or part of the work
|
||||
in a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a "modified version" of the
|
||||
earlier work or a work "based on" the earlier work.
|
||||
|
||||
A "covered work" means either the unmodified Program or a work based
|
||||
on the Program.
|
||||
|
||||
To "propagate" a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To "convey" a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through
|
||||
a computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays "Appropriate Legal Notices"
|
||||
to the extent that it includes a convenient and prominently visible
|
||||
feature that (1) displays an appropriate copyright notice, and (2)
|
||||
tells the user that there is no warranty for the work (except to the
|
||||
extent that warranties are provided), that licensees may convey the
|
||||
work under this License, and how to view a copy of this License. If
|
||||
the interface presents a list of user commands or options, such as a
|
||||
menu, a prominent item in the list meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The "source code" for a work means the preferred form of the work
|
||||
for making modifications to it. "Object code" means any non-source
|
||||
form of a work.
|
||||
|
||||
A "Standard Interface" means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that
|
||||
is widely used among developers working in that language.
|
||||
|
||||
The "System Libraries" of an executable work include anything, other
|
||||
than the work as a whole, that (a) is included in the normal form of
|
||||
packaging a Major Component, but which is not part of that Major
|
||||
Component, and (b) serves only to enable use of the work with that
|
||||
Major Component, or to implement a Standard Interface for which an
|
||||
implementation is available to the public in source code form. A
|
||||
"Major Component", in this context, means a major essential component
|
||||
(kernel, window system, and so on) of the specific operating system
|
||||
(if any) on which the executable work runs, or a compiler used to
|
||||
produce the work, or an object code interpreter used to run it.
|
||||
|
||||
The "Corresponding Source" for a work in object code form means all
|
||||
the source code needed to generate, install, and (for an executable
|
||||
work) run the object code and to modify the work, including scripts to
|
||||
control those activities. However, it does not include the work's
|
||||
System Libraries, or general-purpose tools or generally available free
|
||||
programs which are used unmodified in performing those activities but
|
||||
which are not part of the work. For example, Corresponding Source
|
||||
includes interface definition files associated with source files for
|
||||
the work, and the source code for shared libraries and dynamically
|
||||
linked subprograms that the work is specifically designed to require,
|
||||
such as by intimate data communication or control flow between those
|
||||
subprograms and other parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users
|
||||
can regenerate automatically from other parts of the Corresponding
|
||||
Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that
|
||||
same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program. The output from running a
|
||||
covered work is covered by this License only if the output, given its
|
||||
content, constitutes a covered work. This License acknowledges your
|
||||
rights of fair use or other equivalent, as provided by copyright law.
|
||||
|
||||
You may make, run and propagate covered works that you do not
|
||||
convey, without conditions so long as your license otherwise remains
|
||||
in force. You may convey covered works to others for the sole purpose
|
||||
of having them make modifications exclusively for you, or provide you
|
||||
with facilities for running those works, provided that you comply with
|
||||
the terms of this License in conveying all material for which you do
|
||||
not control copyright. Those thus making or running the covered works
|
||||
for you must do so exclusively on your behalf, under your direction
|
||||
and control, on terms that prohibit them from making any copies of
|
||||
your copyrighted material outside their relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under
|
||||
the conditions stated below. Sublicensing is not allowed; section 10
|
||||
makes it unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article
|
||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||
similar laws prohibiting or restricting circumvention of such
|
||||
measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention
|
||||
is effected by exercising rights under this License with respect to
|
||||
the covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's
|
||||
users, your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice;
|
||||
keep intact all notices stating that this License and any
|
||||
non-permissive terms added in accord with section 7 apply to the code;
|
||||
keep intact all notices of the absence of any warranty; and give all
|
||||
recipients a copy of this License along with the Program.
|
||||
|
||||
You may charge any price or no price for each copy that you convey,
|
||||
and you may offer support or warranty protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the
|
||||
terms of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified
|
||||
it, and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is
|
||||
released under this License and any conditions added under section
|
||||
7. This requirement modifies the requirement in section 4 to
|
||||
"keep intact all notices".
|
||||
|
||||
c) You must license the entire work, as a whole, under this
|
||||
License to anyone who comes into possession of a copy. This
|
||||
License will therefore apply, along with any applicable section 7
|
||||
additional terms, to the whole of the work, and all its parts,
|
||||
regardless of how they are packaged. This License gives no
|
||||
permission to license the work in any other way, but it does not
|
||||
invalidate such permission if you have separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your
|
||||
work need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work,
|
||||
and which are not combined with it such as to form a larger program,
|
||||
in or on a volume of a storage or distribution medium, is called an
|
||||
"aggregate" if the compilation and its resulting copyright are not
|
||||
used to limit the access or legal rights of the compilation's users
|
||||
beyond what the individual works permit. Inclusion of a covered work
|
||||
in an aggregate does not cause this License to apply to the other
|
||||
parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms
|
||||
of sections 4 and 5, provided that you also convey the
|
||||
machine-readable Corresponding Source under the terms of this License,
|
||||
in one of these ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium
|
||||
customarily used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a
|
||||
written offer, valid for at least three years and valid for as
|
||||
long as you offer spare parts or customer support for that product
|
||||
model, to give anyone who possesses the object code either (1) a
|
||||
copy of the Corresponding Source for all the software in the
|
||||
product that is covered by this License, on a durable physical
|
||||
medium customarily used for software interchange, for a price no
|
||||
more than your reasonable cost of physically performing this
|
||||
conveying of source, or (2) access to copy the
|
||||
Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This
|
||||
alternative is allowed only occasionally and noncommercially, and
|
||||
only if you received the object code with such an offer, in accord
|
||||
with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated
|
||||
place (gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to
|
||||
copy the object code is a network server, the Corresponding Source
|
||||
may be on a different server (operated by you or a third party)
|
||||
that supports equivalent copying facilities, provided you maintain
|
||||
clear directions next to the object code saying where to find the
|
||||
Corresponding Source. Regardless of what server hosts the
|
||||
Corresponding Source, you remain obligated to ensure that it is
|
||||
available for as long as needed to satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided
|
||||
you inform other peers where the object code and Corresponding
|
||||
Source of the work are being offered to the general public at no
|
||||
charge under subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be
|
||||
included in conveying the object code work.
|
||||
|
||||
A "User Product" is either (1) a "consumer product", which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, "normally used" refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
"Installation Information" for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as
|
||||
part of a transaction in which the right of possession and use of the
|
||||
User Product is transferred to the recipient in perpetuity or for a
|
||||
fixed term (regardless of how the transaction is characterized), the
|
||||
Corresponding Source conveyed under this section must be accompanied
|
||||
by the Installation Information. But this requirement does not apply
|
||||
if neither you nor any third party retains the ability to install
|
||||
modified object code on the User Product (for example, the work has
|
||||
been installed in ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access to a
|
||||
network may be denied when the modification itself materially and
|
||||
adversely affects the operation of the network or violates the rules and
|
||||
protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided,
|
||||
in accord with this section must be in a format that is publicly
|
||||
documented (and with an implementation available to the public in
|
||||
source code form), and must require no special password or key for
|
||||
unpacking, reading or copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
"Additional permissions" are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall
|
||||
be treated as though they were included in this License, to the extent
|
||||
that they are valid under applicable law. If additional permissions
|
||||
apply only to part of the Program, that part may be used separately
|
||||
under those permissions, but the entire Program remains governed by
|
||||
this License without regard to the additional permissions.
|
||||
|
||||
When you convey a copy of a covered work, you may at your option
|
||||
remove any additional permissions from that copy, or from any part of
|
||||
it. (Additional permissions may be written to require their own
|
||||
removal in certain cases when you modify the work.) You may place
|
||||
additional permissions on material, added by you to a covered work,
|
||||
for which you have or can give appropriate copyright permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you
|
||||
add to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some
|
||||
trade names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that
|
||||
material by anyone who conveys the material (or modified versions of
|
||||
it) with contractual assumptions of liability to the recipient, for
|
||||
any liability that these contractual assumptions directly impose on
|
||||
those licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered "further
|
||||
restrictions" within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further
|
||||
restriction, you may remove that term. If a license document contains
|
||||
a further restriction but permits relicensing or conveying under this
|
||||
License, you may add to a covered work material governed by the terms
|
||||
of that license document, provided that the further restriction does
|
||||
not survive such relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you
|
||||
must place, in the relevant source files, a statement of the
|
||||
additional terms that apply to those files, or a notice indicating
|
||||
where to find the applicable terms.
|
||||
|
||||
Additional terms, permissive or non-permissive, may be stated in the
|
||||
form of a separately written license, or stated as exceptions;
|
||||
the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or
|
||||
modify it is void, and will automatically terminate your rights under
|
||||
this License (including any patent licenses granted under the third
|
||||
paragraph of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your
|
||||
license from a particular copyright holder is reinstated (a)
|
||||
provisionally, unless and until the copyright holder explicitly and
|
||||
finally terminates your license, and (b) permanently, if the copyright
|
||||
holder fails to notify you of the violation by some reasonable means
|
||||
prior to 60 days after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is
|
||||
reinstated permanently if the copyright holder notifies you of the
|
||||
violation by some reasonable means, this is the first time you have
|
||||
received notice of violation of this License (for any work) from that
|
||||
copyright holder, and you cure the violation prior to 30 days after
|
||||
your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or
|
||||
run a copy of the Program. Ancillary propagation of a covered work
|
||||
occurring solely as a consequence of using peer-to-peer transmission
|
||||
to receive a copy likewise does not require acceptance. However,
|
||||
nothing other than this License grants you permission to propagate or
|
||||
modify any covered work. These actions infringe copyright if you do
|
||||
not accept this License. Therefore, by modifying or propagating a
|
||||
covered work, you indicate your acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically
|
||||
receives a license from the original licensors, to run, modify and
|
||||
propagate that work, subject to this License. You are not responsible
|
||||
for enforcing compliance by third parties with this License.
|
||||
|
||||
An "entity transaction" is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered
|
||||
work results from an entity transaction, each party to that
|
||||
transaction who receives a copy of the work also receives whatever
|
||||
licenses to the work the party's predecessor in interest had or could
|
||||
give under the previous paragraph, plus a right to possession of the
|
||||
Corresponding Source of the work from the predecessor in interest, if
|
||||
the predecessor has it or can get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the
|
||||
rights granted or affirmed under this License. For example, you may
|
||||
not impose a license fee, royalty, or other charge for exercise of
|
||||
rights granted under this License, and you may not initiate litigation
|
||||
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||
any patent claim is infringed by making, using, selling, offering for
|
||||
sale, or importing the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A "contributor" is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The
|
||||
work thus licensed is called the contributor's "contributor version".
|
||||
|
||||
A contributor's "essential patent claims" are all patent claims
|
||||
owned or controlled by the contributor, whether already acquired or
|
||||
hereafter acquired, that would be infringed by some manner, permitted
|
||||
by this License, of making, using, or selling its contributor version,
|
||||
but do not include claims that would be infringed only as a
|
||||
consequence of further modification of the contributor version. For
|
||||
purposes of this definition, "control" includes the right to grant
|
||||
patent sublicenses in a manner consistent with the requirements of
|
||||
this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to
|
||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||
propagate the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a "patent license" is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To "grant" such a patent license to a
|
||||
party means to make such an agreement or commitment not to enforce a
|
||||
patent against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license,
|
||||
and the Corresponding Source of the work is not available for anyone
|
||||
to copy, free of charge and under the terms of this License, through a
|
||||
publicly available network server or other readily accessible means,
|
||||
then you must either (1) cause the Corresponding Source to be so
|
||||
available, or (2) arrange to deprive yourself of the benefit of the
|
||||
patent license for this particular work, or (3) arrange, in a manner
|
||||
consistent with the requirements of this License, to extend the patent
|
||||
license to downstream recipients. "Knowingly relying" means you have
|
||||
actual knowledge that, but for the patent license, your conveying the
|
||||
covered work in a country, or your recipient's use of the covered work
|
||||
in a country, would infringe one or more identifiable patents in that
|
||||
country that you have reason to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties
|
||||
receiving the covered work authorizing them to use, propagate, modify
|
||||
or convey a specific copy of the covered work, then the patent license
|
||||
you grant is automatically extended to all recipients of the covered
|
||||
work and works based on it.
|
||||
|
||||
A patent license is "discriminatory" if it does not include within
|
||||
the scope of its coverage, prohibits the exercise of, or is
|
||||
conditioned on the non-exercise of one or more of the rights that are
|
||||
specifically granted under this License. You may not convey a covered
|
||||
work if you are a party to an arrangement with a third party that is
|
||||
in the business of distributing software, under which you make payment
|
||||
to the third party based on the extent of your activity of conveying
|
||||
the work, and under which the third party grants, to any of the
|
||||
parties who would receive the covered work from you, a discriminatory
|
||||
patent license (a) in connection with copies of the covered work
|
||||
conveyed by you (or copies made from those copies), or (b) primarily
|
||||
for and in connection with specific products or compilations that
|
||||
contain the covered work, unless you entered into that arrangement,
|
||||
or that patent license was granted, prior to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting
|
||||
any implied license or other defenses to infringement that may
|
||||
otherwise be available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot convey a
|
||||
covered work so as to satisfy simultaneously your obligations under this
|
||||
License and any other pertinent obligations, then as a consequence you may
|
||||
not convey it at all. For example, if you agree to terms that obligate you
|
||||
to collect a royalty for further conveying from those to whom you convey
|
||||
the Program, the only way you could satisfy both those terms and this
|
||||
License would be to refrain entirely from conveying the Program.
|
||||
|
||||
13. Use with the GNU Affero General Public License.
|
||||
|
||||
Notwithstanding any other provision of this License, you have
|
||||
permission to link or combine any covered work with a work licensed
|
||||
under version 3 of the GNU Affero General Public License into a single
|
||||
combined work, and to convey the resulting work. The terms of this
|
||||
License will continue to apply to the part which is the covered work,
|
||||
but the special requirements of the GNU Affero General Public License,
|
||||
section 13, concerning interaction through a network will apply to the
|
||||
combination as such.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
The Free Software Foundation may publish revised and/or new versions of
|
||||
the GNU General Public License from time to time. Such new versions will
|
||||
be similar in spirit to the present version, but may differ in detail to
|
||||
address new problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the
|
||||
Program specifies that a certain numbered version of the GNU General
|
||||
Public License "or any later version" applies to it, you have the
|
||||
option of following the terms and conditions either of that numbered
|
||||
version or of any later version published by the Free Software
|
||||
Foundation. If the Program does not specify a version number of the
|
||||
GNU General Public License, you may choose any version ever published
|
||||
by the Free Software Foundation.
|
||||
|
||||
If the Program specifies that a proxy can decide which future
|
||||
versions of the GNU General Public License can be used, that proxy's
|
||||
public statement of acceptance of a version permanently authorizes you
|
||||
to choose that version for the Program.
|
||||
|
||||
Later license versions may give you additional or different
|
||||
permissions. However, no additional obligations are imposed on any
|
||||
author or copyright holder as a result of your choosing to follow a
|
||||
later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||
SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided
|
||||
above cannot be given local legal effect according to their terms,
|
||||
reviewing courts shall apply local law that most closely approximates
|
||||
an absolute waiver of all civil liability in connection with the
|
||||
Program, unless a warranty or assumption of liability accompanies a
|
||||
copy of the Program in return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
How to Apply These Terms to Your New Programs
|
||||
|
||||
If you develop a new program, and you want it to be of the greatest
|
||||
possible use to the public, the best way to achieve this is to make it
|
||||
free software which everyone can redistribute and change under these terms.
|
||||
|
||||
To do so, attach the following notices to the program. It is safest
|
||||
to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
<one line to give the program's name and a brief idea of what it does.>
|
||||
Copyright (C) <year> <name of author>
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU General Public License as published by
|
||||
the Free Software Foundation, either version 3 of the License, or
|
||||
(at your option) any later version.
|
||||
|
||||
This program is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
GNU General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License
|
||||
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
Also add information on how to contact you by electronic and paper mail.
|
||||
|
||||
If the program does terminal interaction, make it output a short
|
||||
notice like this when it starts in an interactive mode:
|
||||
|
||||
<program> Copyright (C) <year> <name of author>
|
||||
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
||||
This is free software, and you are welcome to redistribute it
|
||||
under certain conditions; type `show c' for details.
|
||||
|
||||
The hypothetical commands `show w' and `show c' should show the appropriate
|
||||
parts of the General Public License. Of course, your program's commands
|
||||
might be different; for a GUI interface, you would use an "about box".
|
||||
|
||||
You should also get your employer (if you work as a programmer) or school,
|
||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||
For more information on this, and how to apply and follow the GNU GPL, see
|
||||
<https://www.gnu.org/licenses/>.
|
||||
|
||||
The GNU General Public License does not permit incorporating your program
|
||||
into proprietary programs. If your program is a subroutine library, you
|
||||
may consider it more useful to permit linking proprietary applications with
|
||||
the library. If this is what you want to do, use the GNU Lesser General
|
||||
Public License instead of this License. But first, please read
|
||||
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
||||
@@ -1,46 +0,0 @@
|
||||
[](https://remington.pro/software/blender/atomic)
|
||||
|
||||
[**Learn More About Atomic Data Manager on its Official Product Page**](https://remington.pro/software/blender/atomic)
|
||||
|
||||
|
||||
## ENJOY A CLEANER PROJECT
|
||||
Atomic Data Manager offers Blender artists an intelligent data management solution. This feature-packed add-on provides artists with every tool they need to keep unwanted and unused data out of their Blender files. Even better, Atomic's real-time data analysis and automated data removal tools allow its users to clean their projects in a flash.
|
||||
|
||||
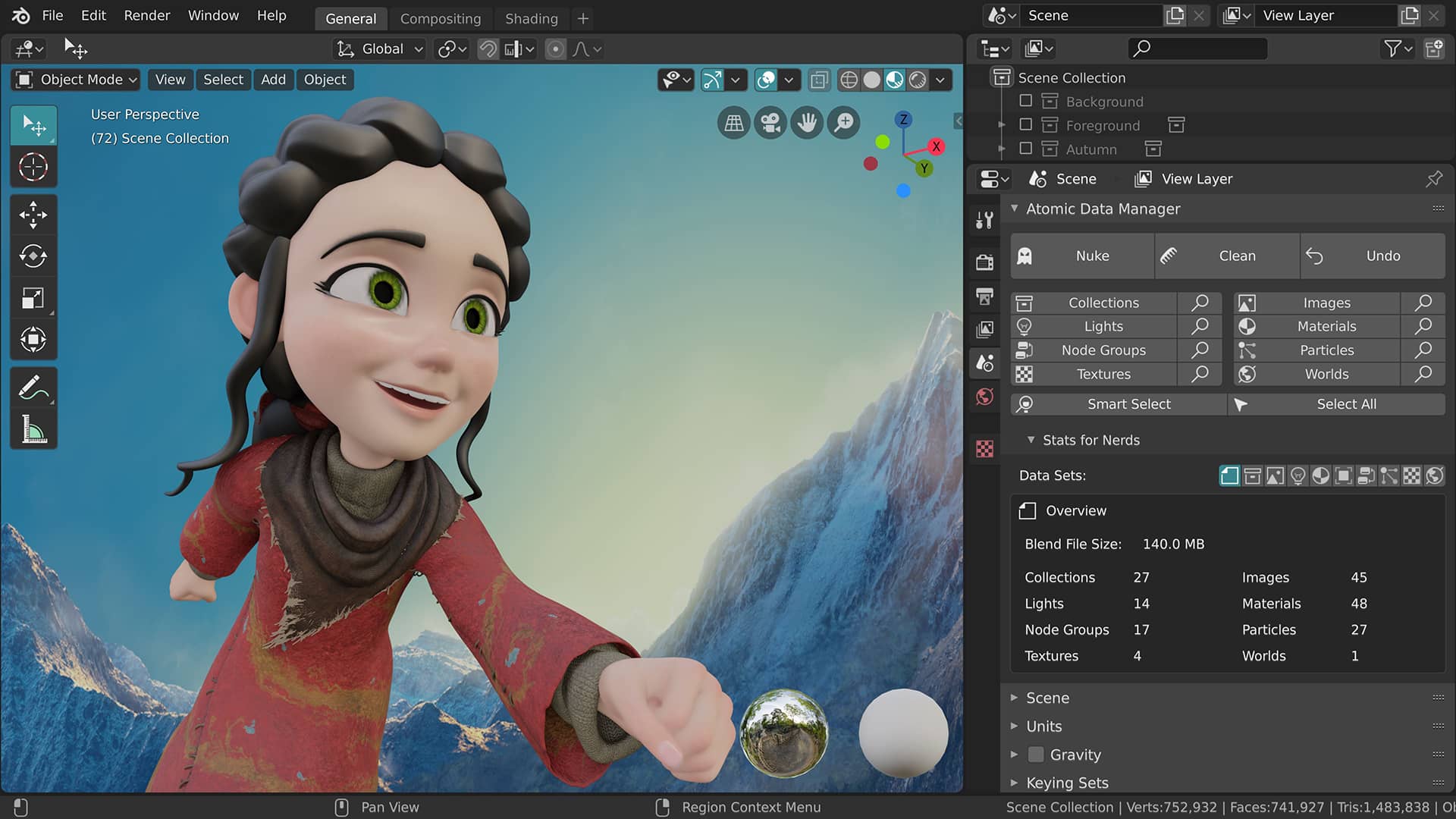
|
||||
|
||||
|
||||
## UNMATCHED FEATURE SET
|
||||
|
||||
| Rapid Cleaning | Missing File Detection |
|
||||
|--|--|
|
||||
| With Atomic, you can clean your project files in a snap. Simply select a category and click the clean button. | Stop those pink textures! Atomic helps you restore missing project files before you even realize they're gone. |
|
||||
|
||||
| Inspection Tools | Data Security |
|
||||
|--|--|
|
||||
| Find out where and how data-blocks are being used, so you can make manual adjustments on the fly. | Know what you're removing before its gone. Atomic offers reliable data security features to keep your projects safe. |
|
||||
|
||||
| Rich Statistics | Compact Design |
|
||||
|--|--|
|
||||
| Get a detailed breakdown of the data being used in your Blender projects. Surprisingly interesting and useful! | Atomic's sleek user interface packs numerous powerful features into a convenient and easily accessible space.|
|
||||
|
||||
#### Additional Features:
|
||||
Pie Menu Controls, Advanced Fake User Options, Mass Delete Categories, Undo Accidental Deletions, Save Data-Blocks, Delete Data-Blocks, Replace Data-Blocks, Rename Data-Blocks, Reload Missing Files, Remove Missing Files, Replace Missing Files, and Search for Missing Files.
|
||||
|
||||
|
||||
## TAKE A VIDEO TOUR
|
||||
[](https://remington.pro/software/blender/atomic/#tour)
|
||||
|
||||
| Keep Your Projects Clean | Reduce File Sizes | Optimize for Render Farms |
|
||||
|--|--|--|
|
||||
| Everyone appreciates a clean project. Use Atomic's intelligent toolset to keep your projects looking spiffy. | Atomic reduces file sizes by removing unused data from your projects. That way, there's more space for other stuff! | Render farms prioritize smaller projects. Atomic can optimize your files so they render sooner! |
|
||||
|
||||
|
||||
## GET ATOMIC
|
||||
|
||||
**Download:** [https://remington.pro/software/blender/atomic/](https://remington.pro/software/blender/atomic)
|
||||
|
||||
**Older Versions:** [https://github.com/grantwilk/atomic-data-manager/releases](https://github.com/grantwilk/atomic-data-manager/releases)
|
||||
|
||||
|
||||
|
||||
**Like the Add-on?** [Consider Supporting Remington Creative](https://remington.pro/support/)!
|
||||
@@ -1,240 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains Atomic's global properties and handles the
|
||||
registration for all packages within the add-on.
|
||||
|
||||
"""
|
||||
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager import ops
|
||||
from atomic_data_manager import ui
|
||||
from atomic_data_manager.ui import inspect_ui
|
||||
from atomic_data_manager.updater import addon_updater_ops
|
||||
|
||||
bl_info = {
|
||||
"name": "Atomic Data Manager",
|
||||
"author": "Remington Creative",
|
||||
"blender": (2, 80, 0),
|
||||
"version": (1, 0, 3),
|
||||
"location": "Properties > Scene",
|
||||
"category": "Remington Creative",
|
||||
"description": "An Intelligent Data Manager for Blender.",
|
||||
"wiki_url":
|
||||
"https://remington.pro/software/blender/atomic",
|
||||
"tracker_url":
|
||||
"https://github.com/grantwilk/atomic-data-manager/issues"
|
||||
}
|
||||
|
||||
|
||||
# Atomic Data Manager Properties
|
||||
class ATOMIC_PG_main(bpy.types.PropertyGroup):
|
||||
# main panel toggle buttons
|
||||
collections: bpy.props.BoolProperty(default=False)
|
||||
images: bpy.props.BoolProperty(default=False)
|
||||
lights: bpy.props.BoolProperty(default=False)
|
||||
materials: bpy.props.BoolProperty(default=False)
|
||||
node_groups: bpy.props.BoolProperty(default=False)
|
||||
particles: bpy.props.BoolProperty(default=False)
|
||||
textures: bpy.props.BoolProperty(default=False)
|
||||
worlds: bpy.props.BoolProperty(default=False)
|
||||
|
||||
# inspect data-block search fields
|
||||
collections_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
images_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
lights_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
materials_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
node_groups_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
particles_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
textures_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
worlds_field: bpy.props.StringProperty(
|
||||
update=inspect_ui.update_inspection)
|
||||
|
||||
# enum for the inspection mode that is currently active
|
||||
active_inspection: bpy.props.EnumProperty(
|
||||
items=[
|
||||
(
|
||||
'COLLECTIONS',
|
||||
'Collections',
|
||||
'Collections'
|
||||
),
|
||||
(
|
||||
'IMAGES',
|
||||
'Images',
|
||||
'Images'
|
||||
),
|
||||
(
|
||||
'LIGHTS',
|
||||
'Lights',
|
||||
'Lights'
|
||||
),
|
||||
(
|
||||
'MATERIALS',
|
||||
'Materials',
|
||||
'Materials'
|
||||
),
|
||||
(
|
||||
'NODE_GROUPS',
|
||||
'Node Groups',
|
||||
'Node Groups'
|
||||
),
|
||||
(
|
||||
'PARTICLES',
|
||||
'Particles',
|
||||
'Particles'
|
||||
),
|
||||
(
|
||||
'TEXTURES',
|
||||
'Textures',
|
||||
'Textures'
|
||||
),
|
||||
(
|
||||
'WORLDS',
|
||||
'Worlds',
|
||||
'Worlds'
|
||||
)
|
||||
],
|
||||
default='COLLECTIONS'
|
||||
)
|
||||
|
||||
# enum for the type of data being shown in the stats panel
|
||||
stats_mode: bpy.props.EnumProperty(
|
||||
items=[
|
||||
(
|
||||
'OVERVIEW', # identifier
|
||||
'Overview', # title
|
||||
'Overview', # description
|
||||
'FILE', # icon
|
||||
0 # number / id
|
||||
),
|
||||
(
|
||||
'COLLECTIONS',
|
||||
'Collections',
|
||||
'Collections',
|
||||
'GROUP',
|
||||
1
|
||||
),
|
||||
(
|
||||
'IMAGES',
|
||||
'Images',
|
||||
'Images',
|
||||
'IMAGE_DATA',
|
||||
2
|
||||
),
|
||||
(
|
||||
'LIGHTS',
|
||||
'Lights',
|
||||
'Lights',
|
||||
'LIGHT',
|
||||
3
|
||||
),
|
||||
(
|
||||
'MATERIALS',
|
||||
'Materials',
|
||||
'Materials',
|
||||
'MATERIAL',
|
||||
4
|
||||
),
|
||||
(
|
||||
'OBJECTS',
|
||||
'Objects',
|
||||
'Objects',
|
||||
'OBJECT_DATA',
|
||||
5
|
||||
),
|
||||
(
|
||||
'NODE_GROUPS',
|
||||
'Node Groups',
|
||||
'Node Groups',
|
||||
'NODETREE',
|
||||
6
|
||||
),
|
||||
(
|
||||
'PARTICLES',
|
||||
'Particle Systems',
|
||||
'Particle Systems',
|
||||
'PARTICLES',
|
||||
7
|
||||
),
|
||||
(
|
||||
'TEXTURES',
|
||||
'Textures',
|
||||
'Textures',
|
||||
'TEXTURE',
|
||||
8
|
||||
),
|
||||
(
|
||||
'WORLDS',
|
||||
'Worlds',
|
||||
'Worlds',
|
||||
'WORLD',
|
||||
9
|
||||
)
|
||||
],
|
||||
default='OVERVIEW'
|
||||
)
|
||||
|
||||
# text field for the inspect rename operator
|
||||
rename_field: bpy.props.StringProperty()
|
||||
|
||||
# search field for the inspect replace operator
|
||||
replace_field: bpy.props.StringProperty()
|
||||
|
||||
|
||||
def register():
|
||||
# add-on updater registration
|
||||
addon_updater_ops.register(bl_info)
|
||||
|
||||
register_class(ATOMIC_PG_main)
|
||||
bpy.types.Scene.atomic = bpy.props.PointerProperty(type=ATOMIC_PG_main)
|
||||
|
||||
# atomic package registration
|
||||
ui.register()
|
||||
ops.register()
|
||||
|
||||
|
||||
def unregister():
|
||||
|
||||
# add-on updated unregistration
|
||||
addon_updater_ops.unregister()
|
||||
|
||||
# atomic package unregistration
|
||||
ui.unregister()
|
||||
ops.unregister()
|
||||
|
||||
unregister_class(ATOMIC_PG_main)
|
||||
del bpy.types.Scene.atomic
|
||||
@@ -1,44 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains global copies of Atomic's preferences so that they
|
||||
can be easily access throughout the add-on.
|
||||
|
||||
NOTE:
|
||||
Changing the values of these variables will NOT change the values in the
|
||||
Atomic's preferences. If you want to change a setting, change it in
|
||||
Blender, not in here.
|
||||
|
||||
"""
|
||||
|
||||
# visible atomic preferences
|
||||
enable_missing_file_warning = True
|
||||
enable_support_me_popup = True
|
||||
include_fake_users = False
|
||||
enable_pie_menu_ui = True
|
||||
|
||||
# hidden atomic preferences
|
||||
pie_menu_type = "D"
|
||||
pie_menu_alt = False
|
||||
pie_menu_any = False
|
||||
pie_menu_ctrl = False
|
||||
pie_menu_oskey = False
|
||||
pie_menu_shift = False
|
||||
last_popup_day = 0
|
||||
@@ -1,45 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file handles the registration of the atomic_data_manager.ops package
|
||||
|
||||
"""
|
||||
|
||||
from atomic_data_manager.ops import main_ops
|
||||
from atomic_data_manager.ops import inspect_ops
|
||||
from atomic_data_manager.ops import direct_use_ops
|
||||
from atomic_data_manager.ops import missing_file_ops
|
||||
from atomic_data_manager.ops import support_me_ops
|
||||
|
||||
|
||||
def register():
|
||||
main_ops.register()
|
||||
inspect_ops.register()
|
||||
direct_use_ops.register()
|
||||
missing_file_ops.register()
|
||||
support_me_ops.register()
|
||||
|
||||
|
||||
def unregister():
|
||||
main_ops.unregister()
|
||||
inspect_ops.unregister()
|
||||
direct_use_ops.unregister()
|
||||
missing_file_ops.unregister()
|
||||
support_me_ops.unregister()
|
||||
@@ -1,793 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the direct use operators, intended to be used with
|
||||
Atomic's pie menu interface. However, they can be implemented anywhere
|
||||
if they need to be.
|
||||
|
||||
These operators basically wrap the functions from ops.utils.nuke.py and
|
||||
ops.utils.clean.py into operators so they can be easily called by other
|
||||
intefaces in Blender.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager import config
|
||||
from atomic_data_manager.stats import unused
|
||||
from atomic_data_manager.ops.utils import nuke
|
||||
from atomic_data_manager.ops.utils import clean
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
class ATOMIC_OT_invoke_pie_menu_ui(bpy.types.Operator):
|
||||
"""Invokes Atomic's pie menu UI if the \"Enable Pie Menu UI\"
|
||||
preference is enabled in Atomic's preferences panel"""
|
||||
bl_idname = "atomic.invoke_pie_menu_ui"
|
||||
bl_label = "Invoke Pie Menu UI"
|
||||
|
||||
def execute(self, context):
|
||||
if config.enable_pie_menu_ui:
|
||||
bpy.ops.wm.call_menu_pie(name="ATOMIC_MT_main_pie")
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke All Operator
|
||||
class ATOMIC_OT_nuke_all(bpy.types.Operator):
|
||||
"""Remove all data-blocks from the selected categories"""
|
||||
bl_idname = "atomic.nuke_all"
|
||||
bl_label = "CAUTION!"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
col = layout.column()
|
||||
col.label(text="Remove the following data-blocks?")
|
||||
|
||||
collections = sorted(bpy.data.collections.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Collections",
|
||||
items=collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
images = sorted(bpy.data.images.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Images",
|
||||
items=images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
lights = sorted(bpy.data.lights.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Lights",
|
||||
items=lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
materials = sorted(bpy.data.materials.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
node_groups = sorted(bpy.data.node_groups.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
particles = sorted(bpy.data.particles.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Particle Systems",
|
||||
items=particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
textures = sorted(bpy.data.textures.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
worlds = sorted(bpy.data.worlds.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra spacing
|
||||
|
||||
def execute(self, context):
|
||||
|
||||
nuke.collections()
|
||||
nuke.images()
|
||||
nuke.lights()
|
||||
nuke.materials()
|
||||
nuke.node_groups()
|
||||
nuke.particles()
|
||||
nuke.textures()
|
||||
nuke.worlds()
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean All Operator
|
||||
class ATOMIC_OT_clean_all(bpy.types.Operator):
|
||||
"""Remove all unused data-blocks from the selected categories"""
|
||||
bl_idname = "atomic.clean_all"
|
||||
bl_label = "Clean All"
|
||||
|
||||
unused_collections = []
|
||||
unused_images = []
|
||||
unused_lights = []
|
||||
unused_materials = []
|
||||
unused_node_groups = []
|
||||
unused_particles = []
|
||||
unused_textures = []
|
||||
unused_worlds = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
col = layout.column()
|
||||
col.label(text="Remove the following data-blocks?")
|
||||
|
||||
collections = sorted(unused.collections_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Collections",
|
||||
items=collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
images = sorted(unused.images_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Images",
|
||||
items=images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
lights = sorted(unused.lights_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Lights",
|
||||
items=lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
materials = sorted(unused.materials_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
node_groups = sorted(unused.node_groups_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
particles = sorted(unused.particles_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Particle Systems",
|
||||
items=particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
textures = sorted(unused.textures_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
worlds = sorted(unused.worlds())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra spacing
|
||||
|
||||
def execute(self, context):
|
||||
|
||||
clean.collections()
|
||||
clean.images()
|
||||
clean.lights()
|
||||
clean.materials()
|
||||
clean.node_groups()
|
||||
clean.particles()
|
||||
clean.textures()
|
||||
clean.worlds()
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
|
||||
self.unused_collections = unused.collections_deep()
|
||||
self.unused_images = unused.images_deep()
|
||||
self.unused_lights = unused.lights_deep()
|
||||
self.unused_materials = unused.materials_deep()
|
||||
self.unused_node_groups = unused.node_groups_deep()
|
||||
self.unused_particles = unused.particles_deep()
|
||||
self.unused_textures = unused.textures_deep()
|
||||
self.unused_worlds = unused.worlds()
|
||||
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Collections Operator
|
||||
class ATOMIC_OT_nuke_collections(bpy.types.Operator):
|
||||
"""Remove all collections from this project"""
|
||||
bl_idname = "atomic.nuke_collections"
|
||||
bl_label = "Nuke Collections"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
collections = bpy.data.collections.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.collections()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Images Operator
|
||||
class ATOMIC_OT_nuke_images(bpy.types.Operator):
|
||||
"""Remove all images from this project"""
|
||||
bl_idname = "atomic.nuke_images"
|
||||
bl_label = "Nuke Images"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
images = bpy.data.images.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.images()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Lights Operator
|
||||
class ATOMIC_OT_nuke_lights(bpy.types.Operator):
|
||||
"""Remove all lights from this project"""
|
||||
bl_idname = "atomic.nuke_lights"
|
||||
bl_label = "Nuke Lights"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
lights = bpy.data.lights.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.lights()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Materials Operator
|
||||
class ATOMIC_OT_nuke_materials(bpy.types.Operator):
|
||||
"""Remove all materials from this project"""
|
||||
bl_idname = "atomic.nuke_materials"
|
||||
bl_label = "Nuke Materials"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
materials = bpy.data.materials.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.materials()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Node Groups Operator
|
||||
class ATOMIC_OT_nuke_node_groups(bpy.types.Operator):
|
||||
"""Remove all node groups from this project"""
|
||||
bl_idname = "atomic.nuke_node_groups"
|
||||
bl_label = "Nuke Node Groups"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
node_groups = bpy.data.node_groups.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.node_groups()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Particles Operator
|
||||
class ATOMIC_OT_nuke_particles(bpy.types.Operator):
|
||||
"""Remove all particle systems from this project"""
|
||||
bl_idname = "atomic.nuke_particles"
|
||||
bl_label = "Nuke Particles"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
particles = bpy.data.particles.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.particles()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Textures Operator
|
||||
class ATOMIC_OT_nuke_textures(bpy.types.Operator):
|
||||
"""Remove all textures from this project"""
|
||||
bl_idname = "atomic.nuke_textures"
|
||||
bl_label = "Nuke Textures"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
textures = bpy.data.textures.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.textures()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Worlds Operator
|
||||
class ATOMIC_OT_nuke_worlds(bpy.types.Operator):
|
||||
"""Remove all worlds from this project"""
|
||||
bl_idname = "atomic.nuke_worlds"
|
||||
bl_label = "Nuke Worlds"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
worlds = bpy.data.worlds.keys()
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
nuke.worlds()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Collections Operator
|
||||
class ATOMIC_OT_clean_collections(bpy.types.Operator):
|
||||
"""Remove all unused collections from this project"""
|
||||
bl_idname = "atomic.clean_collections"
|
||||
bl_label = "Clean Collections"
|
||||
|
||||
unused_collections = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.collections()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_collections = unused.collections_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Images Operator
|
||||
class ATOMIC_OT_clean_images(bpy.types.Operator):
|
||||
"""Remove all unused images from this project"""
|
||||
bl_idname = "atomic.clean_images"
|
||||
bl_label = "Clean Images"
|
||||
|
||||
unused_images = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.images()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_images =unused.images_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Lights Operator
|
||||
class ATOMIC_OT_clean_lights(bpy.types.Operator):
|
||||
"""Remove all unused lights from this project"""
|
||||
bl_idname = "atomic.clean_lights"
|
||||
bl_label = "Clean Lights"
|
||||
|
||||
unused_lights = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.lights()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_lights = unused.lights_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Materials Operator
|
||||
class ATOMIC_OT_clean_materials(bpy.types.Operator):
|
||||
"""Remove all unused materials from this project"""
|
||||
bl_idname = "atomic.clean_materials"
|
||||
bl_label = "Clean Materials"
|
||||
|
||||
unused_materials = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.materials()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_materials = unused.materials_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Node Groups Operator
|
||||
class ATOMIC_OT_clean_node_groups(bpy.types.Operator):
|
||||
"""Remove all unused node groups from this project"""
|
||||
bl_idname = "atomic.clean_node_groups"
|
||||
bl_label = "Clean Node Groups"
|
||||
|
||||
unused_node_groups = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.node_groups()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_node_groups = unused.node_groups_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Particles Operator
|
||||
class ATOMIC_OT_clean_particles(bpy.types.Operator):
|
||||
"""Remove all unused particle systems from this project"""
|
||||
bl_idname = "atomic.clean_particles"
|
||||
bl_label = "Clean Particles"
|
||||
|
||||
unused_particles = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.particles()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_particles = unused.particles_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Textures Operator
|
||||
class ATOMIC_OT_clean_textures(bpy.types.Operator):
|
||||
"""Remove all unused textures from this project"""
|
||||
bl_idname = "atomic.clean_textures"
|
||||
bl_label = "Clean Textures"
|
||||
|
||||
unused_textures = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.textures()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_textures = unused.textures_deep()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Worlds Operator
|
||||
class ATOMIC_OT_clean_worlds(bpy.types.Operator):
|
||||
"""Remove all unused worlds from this project"""
|
||||
bl_idname = "atomic.clean_worlds"
|
||||
bl_label = "Clean Worlds"
|
||||
|
||||
unused_worlds = []
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=self.unused_worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
clean.worlds()
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
self.unused_worlds = unused.worlds()
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_OT_invoke_pie_menu_ui,
|
||||
|
||||
ATOMIC_OT_nuke_all,
|
||||
ATOMIC_OT_clean_all,
|
||||
|
||||
ATOMIC_OT_nuke_collections,
|
||||
ATOMIC_OT_nuke_images,
|
||||
ATOMIC_OT_nuke_lights,
|
||||
ATOMIC_OT_nuke_materials,
|
||||
ATOMIC_OT_nuke_node_groups,
|
||||
ATOMIC_OT_nuke_particles,
|
||||
ATOMIC_OT_nuke_textures,
|
||||
ATOMIC_OT_nuke_worlds,
|
||||
|
||||
ATOMIC_OT_clean_collections,
|
||||
ATOMIC_OT_clean_images,
|
||||
ATOMIC_OT_clean_lights,
|
||||
ATOMIC_OT_clean_materials,
|
||||
ATOMIC_OT_clean_node_groups,
|
||||
ATOMIC_OT_clean_particles,
|
||||
ATOMIC_OT_clean_textures,
|
||||
ATOMIC_OT_clean_worlds
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for item in reg_list:
|
||||
register_class(item)
|
||||
|
||||
|
||||
def unregister():
|
||||
for item in reg_list:
|
||||
unregister_class(item)
|
||||
@@ -1,440 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the operators used in the inspection UI's header.
|
||||
This includes the rename, replace, toggle fake user, delete, and duplicate
|
||||
operators.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.ops.utils import delete
|
||||
from atomic_data_manager.ops.utils import duplicate
|
||||
|
||||
|
||||
# Atomic Data Manager Inspection Rename Operator
|
||||
class ATOMIC_OT_inspection_rename(bpy.types.Operator):
|
||||
"""Give this data-block a new name"""
|
||||
bl_idname = "atomic.rename"
|
||||
bl_label = "Rename Data-Block"
|
||||
|
||||
def draw(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
row = layout.row()
|
||||
row.prop(atom, "rename_field", text="", icon="GREASEPENCIL")
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
name = atom.rename_field
|
||||
|
||||
if inspection == 'COLLECTIONS':
|
||||
bpy.data.collections[atom.collections_field].name = name
|
||||
atom.collections_field = name
|
||||
|
||||
if inspection == 'IMAGES':
|
||||
bpy.data.images[atom.images_field].name = name
|
||||
atom.images_field = name
|
||||
|
||||
if inspection == 'LIGHTS':
|
||||
bpy.data.lights[atom.lights_field].name = name
|
||||
atom.lights_field = name
|
||||
|
||||
if inspection == 'MATERIALS':
|
||||
bpy.data.materials[atom.materials_field].name = name
|
||||
atom.materials_field = name
|
||||
|
||||
if inspection == 'NODE_GROUPS':
|
||||
bpy.data.node_groups[atom.node_groups_field].name = name
|
||||
atom.node_groups_field = name
|
||||
|
||||
if inspection == 'PARTICLES':
|
||||
bpy.data.particles[atom.particles_field].name = name
|
||||
atom.particles_field = name
|
||||
|
||||
if inspection == 'TEXTURES':
|
||||
bpy.data.textures[atom.textures_field].name = name
|
||||
atom.textures_field = name
|
||||
|
||||
if inspection == 'WORLDS':
|
||||
bpy.data.worlds[atom.worlds_field].name = name
|
||||
atom.worlds_field = name
|
||||
|
||||
atom.rename_field = ""
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self, width=200)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspection Replaces Operator
|
||||
class ATOMIC_OT_inspection_replace(bpy.types.Operator):
|
||||
"""Replace all instances of this data-block with another data-block"""
|
||||
bl_idname = "atomic.replace"
|
||||
bl_label = "Replace Data-Block"
|
||||
|
||||
def draw(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
layout = self.layout
|
||||
row = layout.row()
|
||||
|
||||
if inspection == 'IMAGES':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"images",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'LIGHTS':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"lights",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'MATERIALS':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"materials",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'NODE_GROUPS':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"node_groups",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'PARTICLES':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"particles",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'TEXTURES':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"textures",
|
||||
text=""
|
||||
)
|
||||
|
||||
if inspection == 'WORLDS':
|
||||
row.prop_search(
|
||||
atom,
|
||||
"replace_field",
|
||||
bpy.data,
|
||||
"worlds",
|
||||
text=""
|
||||
)
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
if inspection == 'IMAGES' and \
|
||||
atom.replace_field in bpy.data.images.keys():
|
||||
bpy.data.images[atom.images_field].user_remap(
|
||||
bpy.data.images[atom.replace_field])
|
||||
atom.images_field = atom.replace_field
|
||||
|
||||
if inspection == 'LIGHTS' and \
|
||||
atom.replace_field in bpy.data.lights.keys():
|
||||
bpy.data.lights[atom.lights_field].user_remap(
|
||||
bpy.data.lights[atom.replace_field])
|
||||
atom.lights_field = atom.replace_field
|
||||
|
||||
if inspection == 'MATERIALS' and \
|
||||
atom.replace_field in bpy.data.materials.keys():
|
||||
bpy.data.materials[atom.materials_field].user_remap(
|
||||
bpy.data.materials[atom.replace_field])
|
||||
atom.materials_field = atom.replace_field
|
||||
|
||||
if inspection == 'NODE_GROUPS' and \
|
||||
atom.replace_field in bpy.data.node_groups.keys():
|
||||
bpy.data.node_groups[atom.node_groups_field].user_remap(
|
||||
bpy.data.node_groups[atom.replace_field])
|
||||
atom.node_groups_field = atom.replace_field
|
||||
|
||||
if inspection == 'PARTICLES' and \
|
||||
atom.replace_field in bpy.data.particles.keys():
|
||||
bpy.data.particles[atom.particles_field].user_remap(
|
||||
bpy.data.particles[atom.replace_field])
|
||||
atom.particles_field = atom.replace_field
|
||||
|
||||
if inspection == 'TEXTURES' and \
|
||||
atom.replace_field in bpy.data.textures.keys():
|
||||
bpy.data.textures[atom.textures_field].user_remap(
|
||||
bpy.data.textures[atom.replace_field])
|
||||
atom.textures_field = atom.replace_field
|
||||
|
||||
if inspection == 'WORLDS' and \
|
||||
atom.replace_field in bpy.data.worlds.keys():
|
||||
bpy.data.worlds[atom.worlds_field].user_remap(
|
||||
bpy.data.worlds[atom.replace_field])
|
||||
atom.worlds_field = atom.replace_field
|
||||
|
||||
atom.replace_field = ""
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self, width=200)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspection Toggle Fake User Operator
|
||||
class ATOMIC_OT_inspection_toggle_fake_user(bpy.types.Operator):
|
||||
"""Save this data-block even if it has no users"""
|
||||
bl_idname = "atomic.toggle_fake_user"
|
||||
bl_label = "Toggle Fake User"
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
if inspection == 'IMAGES':
|
||||
image = bpy.data.images[atom.images_field]
|
||||
bpy.data.images[atom.images_field].use_fake_user = \
|
||||
not image.use_fake_user
|
||||
|
||||
if inspection == 'LIGHTS':
|
||||
light = bpy.data.lights[atom.lights_field]
|
||||
bpy.data.lights[atom.lights_field].use_fake_user = \
|
||||
not light.use_fake_user
|
||||
|
||||
if inspection == 'MATERIALS':
|
||||
material = bpy.data.materials[atom.materials_field]
|
||||
bpy.data.materials[atom.materials_field].use_fake_user = \
|
||||
not material.use_fake_user
|
||||
|
||||
if inspection == 'NODE_GROUPS':
|
||||
node_group = bpy.data.node_groups[atom.node_groups_field]
|
||||
bpy.data.node_groups[atom.node_groups_field].use_fake_user = \
|
||||
not node_group.use_fake_user
|
||||
|
||||
if inspection == 'PARTICLES':
|
||||
particle = bpy.data.particles[atom.particles_field]
|
||||
bpy.data.particles[atom.particles_field].use_fake_user = \
|
||||
not particle.use_fake_user
|
||||
|
||||
if inspection == 'TEXTURES':
|
||||
texture = bpy.data.textures[atom.textures_field]
|
||||
bpy.data.textures[atom.textures_field].use_fake_user = \
|
||||
not texture.use_fake_user
|
||||
|
||||
if inspection == 'WORLDS':
|
||||
world = bpy.data.worlds[atom.worlds_field]
|
||||
bpy.data.worlds[atom.worlds_field].use_fake_user = \
|
||||
not world.use_fake_user
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Inspection Duplicate Operator
|
||||
class ATOMIC_OT_inspection_duplicate(bpy.types.Operator):
|
||||
"""Make an exact copy of this data-block"""
|
||||
bl_idname = "atomic.inspection_duplicate"
|
||||
bl_label = "Duplicate Data-Block"
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
if inspection == 'COLLECTIONS':
|
||||
key = atom.collections_field
|
||||
collections = bpy.data.collections
|
||||
|
||||
if key in collections.keys():
|
||||
copy_key = duplicate.collection(key)
|
||||
atom.collections_field = copy_key
|
||||
|
||||
elif inspection == 'IMAGES':
|
||||
key = atom.images_field
|
||||
images = bpy.data.images
|
||||
|
||||
if key in images.keys():
|
||||
copy_key = duplicate.image(key)
|
||||
atom.images_field = copy_key
|
||||
|
||||
elif inspection == 'LIGHTS':
|
||||
key = atom.lights_field
|
||||
lights = bpy.data.lights
|
||||
|
||||
if key in lights.keys():
|
||||
copy_key = duplicate.light(key)
|
||||
atom.lights_field = copy_key
|
||||
|
||||
elif inspection == 'MATERIALS':
|
||||
key = atom.materials_field
|
||||
materials = bpy.data.materials
|
||||
|
||||
if key in materials.keys():
|
||||
copy_key = duplicate.material(key)
|
||||
atom.materials_field = copy_key
|
||||
|
||||
elif inspection == 'NODE_GROUPS':
|
||||
key = atom.node_groups_field
|
||||
node_groups = bpy.data.node_groups
|
||||
|
||||
if key in node_groups.keys():
|
||||
copy_key = duplicate.node_group(key)
|
||||
atom.node_groups_field = copy_key
|
||||
|
||||
elif inspection == 'PARTICLES':
|
||||
key = atom.particles_field
|
||||
particles = bpy.data.particles
|
||||
|
||||
if key in particles.keys():
|
||||
copy_key = duplicate.particle(key)
|
||||
atom.particles_field = copy_key
|
||||
|
||||
elif inspection == 'TEXTURES':
|
||||
key = atom.textures_field
|
||||
textures = bpy.data.textures
|
||||
|
||||
if key in textures.keys():
|
||||
copy_key = duplicate.texture(key)
|
||||
atom.textures_field = copy_key
|
||||
|
||||
elif inspection == 'WORLDS':
|
||||
key = atom.worlds_field
|
||||
worlds = bpy.data.worlds
|
||||
|
||||
if key in worlds.keys():
|
||||
copy_key = duplicate.world(key)
|
||||
atom.worlds_field = copy_key
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Inspection Delete Operator
|
||||
class ATOMIC_OT_inspection_delete(bpy.types.Operator):
|
||||
"""Forcibly remove this data-block from the project"""
|
||||
bl_idname = "atomic.inspection_delete"
|
||||
bl_label = "Delete Data-Block"
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
inspection = atom.active_inspection
|
||||
|
||||
if inspection == 'COLLECTIONS':
|
||||
key = atom.collections_field
|
||||
collections = bpy.data.collections
|
||||
|
||||
if key in collections.keys():
|
||||
delete.collection(key)
|
||||
atom.collections_field = ""
|
||||
|
||||
elif inspection == 'IMAGES':
|
||||
key = atom.images_field
|
||||
images = bpy.data.images
|
||||
|
||||
if key in images.keys():
|
||||
delete.image(key)
|
||||
atom.images_field = ""
|
||||
|
||||
elif inspection == 'LIGHTS':
|
||||
key = atom.lights_field
|
||||
lights = bpy.data.lights
|
||||
|
||||
if key in lights.keys():
|
||||
delete.light(key)
|
||||
atom.lights_field = ""
|
||||
|
||||
elif inspection == 'MATERIALS':
|
||||
key = atom.materials_field
|
||||
materials = bpy.data.materials
|
||||
|
||||
if key in materials.keys():
|
||||
delete.material(key)
|
||||
atom.materials_field = ""
|
||||
|
||||
elif inspection == 'NODE_GROUPS':
|
||||
key = atom.node_groups_field
|
||||
node_groups = bpy.data.node_groups
|
||||
|
||||
if key in node_groups.keys():
|
||||
delete.node_group(key)
|
||||
atom.node_groups_field = ""
|
||||
|
||||
elif inspection == 'PARTICLES':
|
||||
key = atom.particles_field
|
||||
particles = bpy.data.particles
|
||||
if key in particles.keys():
|
||||
delete.particle(key)
|
||||
atom.particles_field = ""
|
||||
|
||||
elif inspection == 'TEXTURES':
|
||||
key = atom.textures_field
|
||||
textures = bpy.data.textures
|
||||
|
||||
if key in textures.keys():
|
||||
delete.texture(key)
|
||||
atom.textures_field = ""
|
||||
|
||||
elif inspection == 'WORLDS':
|
||||
key = atom.worlds_field
|
||||
worlds = bpy.data.worlds
|
||||
|
||||
if key in worlds.keys():
|
||||
delete.world(key)
|
||||
atom.worlds_field = ""
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_OT_inspection_rename,
|
||||
ATOMIC_OT_inspection_replace,
|
||||
ATOMIC_OT_inspection_toggle_fake_user,
|
||||
ATOMIC_OT_inspection_duplicate,
|
||||
ATOMIC_OT_inspection_delete
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for item in reg_list:
|
||||
register_class(item)
|
||||
|
||||
|
||||
def unregister():
|
||||
for item in reg_list:
|
||||
unregister_class(item)
|
||||
@@ -1,444 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the main operators found in the main panel of the
|
||||
Atomic Data Manager interface. This includes nuke, clean, undo, and the
|
||||
various selection operations.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.stats import unused
|
||||
from atomic_data_manager.ops.utils import clean
|
||||
from atomic_data_manager.ops.utils import nuke
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Operator
|
||||
class ATOMIC_OT_nuke(bpy.types.Operator):
|
||||
"""Remove all data-blocks from the selected categories"""
|
||||
bl_idname = "atomic.nuke"
|
||||
bl_label = "CAUTION!"
|
||||
|
||||
def draw(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
layout = self.layout
|
||||
|
||||
col = layout.column()
|
||||
col.label(text="Remove the following data-blocks?")
|
||||
|
||||
# No Data Section
|
||||
if not (atom.collections or atom.images or atom.lights or
|
||||
atom.materials or atom.node_groups or atom.particles or
|
||||
atom.textures or atom.worlds):
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
)
|
||||
|
||||
# display when the main panel collections property is toggled
|
||||
if atom.collections:
|
||||
collections = sorted(bpy.data.collections.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Collections",
|
||||
items=collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
# display when the main panel images property is toggled
|
||||
if atom.images:
|
||||
images = sorted(bpy.data.images.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Images",
|
||||
items=images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
# display when the main panel lights property is toggled
|
||||
if atom.lights:
|
||||
lights = sorted(bpy.data.lights.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Lights",
|
||||
items=lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
# display when the main panel materials property is toggled
|
||||
if atom.materials:
|
||||
materials = sorted(bpy.data.materials.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
# display when the main panel node groups property is toggled
|
||||
if atom.node_groups:
|
||||
node_groups = sorted(bpy.data.node_groups.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
# display when the main panel particle systems property is toggled
|
||||
if atom.particles:
|
||||
particles = sorted(bpy.data.particles.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Particle Systems",
|
||||
items=particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
# display when the main panel textures property is toggled
|
||||
if atom.textures:
|
||||
textures = sorted(bpy.data.textures.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
# display when the main panel worlds property is toggled
|
||||
if atom.worlds:
|
||||
worlds = sorted(bpy.data.worlds.keys())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra spacing
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
if atom.collections:
|
||||
nuke.collections()
|
||||
|
||||
if atom.images:
|
||||
nuke.images()
|
||||
|
||||
if atom.lights:
|
||||
nuke.lights()
|
||||
|
||||
if atom.materials:
|
||||
nuke.materials()
|
||||
|
||||
if atom.node_groups:
|
||||
nuke.node_groups()
|
||||
|
||||
if atom.particles:
|
||||
nuke.particles()
|
||||
|
||||
if atom.textures:
|
||||
nuke.textures()
|
||||
|
||||
if atom.worlds:
|
||||
nuke.worlds()
|
||||
|
||||
bpy.ops.atomic.deselect_all()
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Operator
|
||||
class ATOMIC_OT_clean(bpy.types.Operator):
|
||||
"""Remove all unused data-blocks from the selected categories"""
|
||||
bl_idname = "atomic.clean"
|
||||
bl_label = "Clean"
|
||||
|
||||
unused_collections = []
|
||||
unused_images = []
|
||||
unused_lights = []
|
||||
unused_materials = []
|
||||
unused_node_groups = []
|
||||
unused_particles = []
|
||||
unused_textures = []
|
||||
unused_worlds = []
|
||||
|
||||
def draw(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
layout = self.layout
|
||||
|
||||
col = layout.column()
|
||||
col.label(text="Remove the following data-blocks?")
|
||||
|
||||
# display if no main panel properties are toggled
|
||||
if not (atom.collections or atom.images or atom.lights or
|
||||
atom.materials or atom.node_groups or atom.particles
|
||||
or atom.textures or atom.worlds):
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
)
|
||||
|
||||
# display when the main panel collections property is toggled
|
||||
if atom.collections:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Collections",
|
||||
items=self.unused_collections,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
# display when the main panel images property is toggled
|
||||
if atom.images:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Images",
|
||||
items=self.unused_images,
|
||||
icon="IMAGE_DATA"
|
||||
)
|
||||
|
||||
# display when the main panel lights property is toggled
|
||||
if atom.lights:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Lights",
|
||||
items=self.unused_lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
# display when the main panel materials property is toggled
|
||||
if atom.materials:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=self.unused_materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
# display when the main panel node groups property is toggled
|
||||
if atom.node_groups:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=self.unused_node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
# display when the main panel particle systems property is toggled
|
||||
if atom.particles:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Particle Systems",
|
||||
items=self.unused_particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
# display when the main panel textures property is toggled
|
||||
if atom.textures:
|
||||
textures = sorted(unused.textures_deep())
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
# display when the main panel worlds property is toggled
|
||||
if atom.worlds:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=self.unused_worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra spacing
|
||||
|
||||
def execute(self, context):
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
if atom.collections:
|
||||
clean.collections()
|
||||
|
||||
if atom.images:
|
||||
clean.images()
|
||||
|
||||
if atom.lights:
|
||||
clean.lights()
|
||||
|
||||
if atom.materials:
|
||||
clean.materials()
|
||||
|
||||
if atom.node_groups:
|
||||
clean.node_groups()
|
||||
|
||||
if atom.particles:
|
||||
clean.particles()
|
||||
|
||||
if atom.textures:
|
||||
clean.textures()
|
||||
|
||||
if atom.worlds:
|
||||
clean.worlds()
|
||||
|
||||
bpy.ops.atomic.deselect_all()
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
if atom.collections:
|
||||
self.unused_collections = unused.collections_deep()
|
||||
|
||||
if atom.images:
|
||||
self.unused_images = unused.images_deep()
|
||||
|
||||
if atom.lights:
|
||||
self.unused_lights = unused.lights_deep()
|
||||
|
||||
if atom.materials:
|
||||
self.unused_materials = unused.materials_deep()
|
||||
|
||||
if atom.node_groups:
|
||||
self.unused_node_groups = unused.node_groups_deep()
|
||||
|
||||
if atom.particles:
|
||||
self.unused_particles = unused.particles_deep()
|
||||
|
||||
if atom.textures:
|
||||
self.unused_textures = unused.textures_deep()
|
||||
|
||||
if atom.worlds:
|
||||
self.unused_worlds = unused.worlds()
|
||||
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Undo Operator
|
||||
class ATOMIC_OT_undo(bpy.types.Operator):
|
||||
"""Undo the previous action"""
|
||||
bl_idname = "atomic.undo"
|
||||
bl_label = "Undo"
|
||||
|
||||
def execute(self, context):
|
||||
bpy.ops.ed.undo()
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Smart Select Operator
|
||||
class ATOMIC_OT_smart_select(bpy.types.Operator):
|
||||
"""Auto-select categories with unused data"""
|
||||
bl_idname = "atomic.smart_select"
|
||||
bl_label = "Smart Select"
|
||||
|
||||
def execute(self, context):
|
||||
|
||||
bpy.context.scene.atomic.collections = \
|
||||
any(unused.collections_deep())
|
||||
|
||||
bpy.context.scene.atomic.images = \
|
||||
any(unused.images_deep())
|
||||
|
||||
bpy.context.scene.atomic.lights = \
|
||||
any(unused.lights_deep())
|
||||
|
||||
bpy.context.scene.atomic.materials = \
|
||||
any(unused.materials_deep())
|
||||
|
||||
bpy.context.scene.atomic.node_groups = \
|
||||
any(unused.node_groups_deep())
|
||||
|
||||
bpy.context.scene.atomic.particles = \
|
||||
any(unused.particles_deep())
|
||||
|
||||
bpy.context.scene.atomic.textures = \
|
||||
any(unused.textures_deep())
|
||||
|
||||
bpy.context.scene.atomic.worlds = \
|
||||
any(unused.worlds())
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Select All Operator
|
||||
class ATOMIC_OT_select_all(bpy.types.Operator):
|
||||
"""Select all categories"""
|
||||
bl_idname = "atomic.select_all"
|
||||
bl_label = "Select All"
|
||||
|
||||
def execute(self, context):
|
||||
bpy.context.scene.atomic.collections = True
|
||||
bpy.context.scene.atomic.images = True
|
||||
bpy.context.scene.atomic.lights = True
|
||||
bpy.context.scene.atomic.materials = True
|
||||
bpy.context.scene.atomic.node_groups = True
|
||||
bpy.context.scene.atomic.particles = True
|
||||
bpy.context.scene.atomic.textures = True
|
||||
bpy.context.scene.atomic.worlds = True
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Deselect All Operator
|
||||
class ATOMIC_OT_deselect_all(bpy.types.Operator):
|
||||
"""Deselect all categories"""
|
||||
bl_idname = "atomic.deselect_all"
|
||||
bl_label = "Deselect All"
|
||||
|
||||
def execute(self, context):
|
||||
bpy.context.scene.atomic.collections = False
|
||||
bpy.context.scene.atomic.images = False
|
||||
bpy.context.scene.atomic.lights = False
|
||||
bpy.context.scene.atomic.materials = False
|
||||
bpy.context.scene.atomic.node_groups = False
|
||||
bpy.context.scene.atomic.particles = False
|
||||
bpy.context.scene.atomic.textures = False
|
||||
bpy.context.scene.atomic.worlds = False
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_OT_nuke,
|
||||
ATOMIC_OT_clean,
|
||||
ATOMIC_OT_undo,
|
||||
ATOMIC_OT_smart_select,
|
||||
ATOMIC_OT_select_all,
|
||||
ATOMIC_OT_deselect_all
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for item in reg_list:
|
||||
register_class(item)
|
||||
|
||||
|
||||
def unregister():
|
||||
for item in reg_list:
|
||||
unregister_class(item)
|
||||
@@ -1,195 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains operations for missing file handling. This includes
|
||||
the option to reload, remove, replace, and search for these missing files.
|
||||
|
||||
It also contains the post-reload report dialog that appears after
|
||||
attempting to reload missing project files.
|
||||
|
||||
# TODO: implement missing file replace and search once Blender fixes the
|
||||
# TODO: bugs with the file chooser not opening from a dialog
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.stats import missing
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# Atomic Data Manager Reload Missing Files Operator
|
||||
class ATOMIC_OT_reload_missing(bpy.types.Operator):
|
||||
"""Reload missing files"""
|
||||
bl_idname = "atomic.reload_missing"
|
||||
bl_label = "Reload Missing Files"
|
||||
|
||||
def execute(self, context):
|
||||
# reload images
|
||||
for image in bpy.data.images:
|
||||
image.reload()
|
||||
|
||||
# reload libraries
|
||||
for library in bpy.data.libraries:
|
||||
library.reload()
|
||||
|
||||
# call reload report
|
||||
bpy.ops.atomic.reload_report('INVOKE_DEFAULT')
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
# Atomic Data Manager Reload Missing Files Report Operator
|
||||
class ATOMIC_OT_reload_report(bpy.types.Operator):
|
||||
"""Reload report for missing files"""
|
||||
bl_idname = "atomic.reload_report"
|
||||
bl_label = "Missing File Reload Report"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
missing_images = missing.images()
|
||||
missing_libraries = missing.libraries()
|
||||
|
||||
if missing_images or missing_libraries:
|
||||
row = layout.row()
|
||||
row.label(
|
||||
text="Atomic was unable to reload the following files:"
|
||||
)
|
||||
|
||||
if missing_images:
|
||||
ui_layouts.box_list(
|
||||
layout=self.layout,
|
||||
items=missing_images,
|
||||
icon='IMAGE_DATA',
|
||||
columns=2
|
||||
)
|
||||
|
||||
if missing_libraries:
|
||||
ui_layouts.box_list(
|
||||
layout=self.layout,
|
||||
items=missing_images,
|
||||
icon='LIBRARY_DATA_DIRECT',
|
||||
columns=2
|
||||
)
|
||||
|
||||
else:
|
||||
row = layout.row()
|
||||
row.label(text="All files successfully reloaded!")
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Remove Missing Files Operator
|
||||
class ATOMIC_OT_remove_missing(bpy.types.Operator):
|
||||
"""Remove all missing files from this project"""
|
||||
bl_idname = "atomic.remove_missing"
|
||||
bl_label = "Remove Missing Files"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
row = layout.row()
|
||||
row.label(text="Remove the following data-blocks?")
|
||||
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
items=missing.images(),
|
||||
icon="IMAGE_DATA",
|
||||
columns=2
|
||||
)
|
||||
|
||||
row = layout.row() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
for image_key in missing.images():
|
||||
bpy.data.images.remove(bpy.data.images[image_key])
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# TODO: Implement search for missing once file browser bugs are fixed
|
||||
# Atomic Data Manager Search for Missing Files Operator
|
||||
class ATOMIC_OT_search_missing(bpy.types.Operator):
|
||||
"""Search a specified directory for the missing files"""
|
||||
bl_idname = "atomic.search_missing"
|
||||
bl_label = "Search for Missing Files"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Unsupported Operation!")
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# TODO: Implement replace missing once file browser bugs are fixed
|
||||
# Atomic Data Manager Replace Missing Files Operator
|
||||
class ATOMIC_OT_replace_missing(bpy.types.Operator):
|
||||
"""Replace each missing file with a new file"""
|
||||
bl_idname = "atomic.replace_missing"
|
||||
bl_label = "Replace Missing Files"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
row = layout.row()
|
||||
row.label(text="Unsupported Operation!")
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_OT_reload_missing,
|
||||
ATOMIC_OT_reload_report,
|
||||
ATOMIC_OT_search_missing,
|
||||
ATOMIC_OT_replace_missing,
|
||||
ATOMIC_OT_remove_missing
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for item in reg_list:
|
||||
register_class(item)
|
||||
|
||||
|
||||
def unregister():
|
||||
for item in reg_list:
|
||||
unregister_class(item)
|
||||
@@ -1,55 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
|
||||
---
|
||||
|
||||
This file contains the operator for opening the Remington Creative
|
||||
support page in the web browser.
|
||||
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
import webbrowser
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
|
||||
|
||||
# Atomic Data Manager Open Support Me Operator
|
||||
class ATOMIC_OT_open_support_me(bpy.types.Operator):
|
||||
"""Opens the Remington Creative \"Support Me\" webpage"""
|
||||
bl_idname = "atomic.open_support_me"
|
||||
bl_label = "Support Me"
|
||||
|
||||
def execute(self, context):
|
||||
webbrowser.open("https://remingtoncreative.com/support/")
|
||||
return {'FINISHED'}
|
||||
|
||||
|
||||
reg_list = [ATOMIC_OT_open_support_me]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
@@ -1,74 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions for cleaning out specific data categories.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from atomic_data_manager.stats import unused
|
||||
|
||||
|
||||
def collections():
|
||||
# removes all unused collections from the project
|
||||
for collection_key in unused.collections_deep():
|
||||
bpy.data.collections.remove(bpy.data.collections[collection_key])
|
||||
|
||||
|
||||
def images():
|
||||
# removes all unused images from the project
|
||||
for image_key in unused.images_deep():
|
||||
bpy.data.images.remove(bpy.data.images[image_key])
|
||||
|
||||
|
||||
def lights():
|
||||
# removes all unused lights from the project
|
||||
for light_key in unused.lights_deep():
|
||||
bpy.data.lights.remove(bpy.data.lights[light_key])
|
||||
|
||||
|
||||
def materials():
|
||||
# removes all unused materials from the project
|
||||
for light_key in unused.materials_deep():
|
||||
bpy.data.materials.remove(bpy.data.materials[light_key])
|
||||
|
||||
|
||||
def node_groups():
|
||||
# removes all unused node groups from the project
|
||||
for node_group_key in unused.node_groups_deep():
|
||||
bpy.data.node_groups.remove(bpy.data.node_groups[node_group_key])
|
||||
|
||||
|
||||
def particles():
|
||||
# removes all unused particle systems from the project
|
||||
for particle_key in unused.particles_deep():
|
||||
bpy.data.particles.remove(bpy.data.particles[particle_key])
|
||||
|
||||
|
||||
def textures():
|
||||
# removes all unused textures from the project
|
||||
for texture_key in unused.textures_deep():
|
||||
bpy.data.textures.remove(bpy.data.textures[texture_key])
|
||||
|
||||
|
||||
def worlds():
|
||||
# removes all unused worlds from the project
|
||||
for world_key in unused.worlds():
|
||||
bpy.data.worlds.remove(bpy.data.worlds[world_key])
|
||||
@@ -1,71 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions for deleting individual data-blocks from
|
||||
Atomic's inspection inteface.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
|
||||
|
||||
def delete_datablock(data, key):
|
||||
# deletes a specific data-block from a set of data
|
||||
data.remove(data[key])
|
||||
|
||||
|
||||
def collection(key):
|
||||
# removes a specific collection
|
||||
delete_datablock(bpy.data.collections, key)
|
||||
|
||||
|
||||
def image(key):
|
||||
# removes a specific image
|
||||
delete_datablock(bpy.data.images, key)
|
||||
|
||||
|
||||
def light(key):
|
||||
# removes a specific light
|
||||
delete_datablock(bpy.data.lights, key)
|
||||
|
||||
|
||||
def material(key):
|
||||
# removes a specific material
|
||||
delete_datablock(bpy.data.materials, key)
|
||||
|
||||
|
||||
def node_group(key):
|
||||
# removes a specific node group
|
||||
delete_datablock(bpy.data.node_groups, key)
|
||||
|
||||
|
||||
def particle(key):
|
||||
# removes a specific particle system
|
||||
delete_datablock(bpy.data.particles, key)
|
||||
|
||||
|
||||
def texture(key):
|
||||
# removes a specific texture
|
||||
delete_datablock(bpy.data.textures, key)
|
||||
|
||||
|
||||
def world(key):
|
||||
# removes a specific world
|
||||
delete_datablock(bpy.data.worlds, key)
|
||||
@@ -1,77 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions for duplicating data-blocks from Atomic's
|
||||
inspection interface.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
|
||||
|
||||
def duplicate_data(data, key):
|
||||
# creates a copy of the specified data-block and returns its key
|
||||
return data[key].copy().name
|
||||
|
||||
|
||||
def collection(key):
|
||||
# creates of copy of the specified collection and places it under the
|
||||
# scene collection
|
||||
collections = bpy.data.collections
|
||||
scene_collection = bpy.context.scene.collection
|
||||
|
||||
copy_key = duplicate_data(collections, key)
|
||||
scene_collection.children.link(collections[copy_key])
|
||||
return copy_key
|
||||
|
||||
|
||||
def image(key):
|
||||
# creates of copy of the specified image
|
||||
return duplicate_data(bpy.data.images, key)
|
||||
|
||||
|
||||
def light(key):
|
||||
# creates of copy of the specified light
|
||||
return duplicate_data(bpy.data.lights, key)
|
||||
|
||||
|
||||
def material(key):
|
||||
# creates of copy of the specified material
|
||||
return duplicate_data(bpy.data.materials, key)
|
||||
|
||||
|
||||
def node_group(key):
|
||||
# creates of copy of the specified node group
|
||||
return duplicate_data(bpy.data.node_groups, key)
|
||||
|
||||
|
||||
def particle(key):
|
||||
# creates of copy of the specified particle
|
||||
return duplicate_data(bpy.data.particles, key)
|
||||
|
||||
|
||||
def texture(key):
|
||||
# creates of copy of the specified texture
|
||||
return duplicate_data(bpy.data.textures, key)
|
||||
|
||||
|
||||
def world(key):
|
||||
# creates of copy of the specified world
|
||||
return duplicate_data(bpy.data.worlds, key)
|
||||
@@ -1,72 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions for removing all data-blocks from specified
|
||||
data categories.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
|
||||
|
||||
def nuke_data(data):
|
||||
# removes all data-blocks from the indicated set of data
|
||||
for key in data.keys():
|
||||
data.remove(data[key])
|
||||
|
||||
|
||||
def collections():
|
||||
# removes all collections from the project
|
||||
nuke_data(bpy.data.collections)
|
||||
|
||||
|
||||
def images():
|
||||
# removes all images from the project
|
||||
nuke_data(bpy.data.images)
|
||||
|
||||
|
||||
def lights():
|
||||
# removes all lights from the project
|
||||
nuke_data(bpy.data.lights)
|
||||
|
||||
|
||||
def materials():
|
||||
# removes all materials from the project
|
||||
nuke_data(bpy.data.materials)
|
||||
|
||||
|
||||
def node_groups():
|
||||
# removes all node groups from the project
|
||||
nuke_data(bpy.data.node_groups)
|
||||
|
||||
|
||||
def particles():
|
||||
# removes all particle systems from the project
|
||||
nuke_data(bpy.data.particles)
|
||||
|
||||
|
||||
def textures():
|
||||
# removes all textures from the project
|
||||
nuke_data(bpy.data.textures)
|
||||
|
||||
|
||||
def worlds():
|
||||
# removes all worlds from the project
|
||||
nuke_data(bpy.data.worlds)
|
||||
@@ -1,190 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions that count quantities of various sets of data.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from atomic_data_manager.stats import unused
|
||||
from atomic_data_manager.stats import unnamed
|
||||
from atomic_data_manager.stats import missing
|
||||
|
||||
|
||||
def collections():
|
||||
# returns the number of collections in the project
|
||||
|
||||
return len(bpy.data.collections)
|
||||
|
||||
|
||||
def collections_unused():
|
||||
# returns the number of unused collections in the project
|
||||
|
||||
return len(unused.collections_shallow())
|
||||
|
||||
|
||||
def collections_unnamed():
|
||||
# returns the number of unnamed collections in the project
|
||||
|
||||
return len(unnamed.collections())
|
||||
|
||||
|
||||
def images():
|
||||
# returns the number of images in the project
|
||||
|
||||
return len(bpy.data.images)
|
||||
|
||||
|
||||
def images_unused():
|
||||
# returns the number of unused images in the project
|
||||
|
||||
return len(unused.images_shallow())
|
||||
|
||||
|
||||
def images_unnamed():
|
||||
# returns the number of unnamed images in the project
|
||||
|
||||
return len(unnamed.images())
|
||||
|
||||
|
||||
def images_missing():
|
||||
# returns the number of missing images in the project
|
||||
|
||||
return len(missing.images())
|
||||
|
||||
|
||||
def lights():
|
||||
# returns the number of lights in the project
|
||||
|
||||
return len(bpy.data.lights)
|
||||
|
||||
|
||||
def lights_unused():
|
||||
# returns the number of unused lights in the project
|
||||
|
||||
return len(unused.lights_shallow())
|
||||
|
||||
|
||||
def lights_unnamed():
|
||||
# returns the number of unnamed lights in the project
|
||||
|
||||
return len(unnamed.lights())
|
||||
|
||||
|
||||
def materials():
|
||||
# returns the number of materials in the project
|
||||
|
||||
return len(bpy.data.materials)
|
||||
|
||||
|
||||
def materials_unused():
|
||||
# returns the number of unused materials in the project
|
||||
|
||||
return len(unused.materials_shallow())
|
||||
|
||||
|
||||
def materials_unnamed():
|
||||
# returns the number of unnamed materials in the project
|
||||
|
||||
return len(unnamed.materials())
|
||||
|
||||
|
||||
def node_groups():
|
||||
# returns the number of node groups in the project
|
||||
|
||||
return len(bpy.data.node_groups)
|
||||
|
||||
|
||||
def node_groups_unused():
|
||||
# returns the number of unused node groups in the project
|
||||
|
||||
return len(unused.node_groups_shallow())
|
||||
|
||||
|
||||
def node_groups_unnamed():
|
||||
# returns the number of unnamed node groups in the project
|
||||
|
||||
return len(unnamed.node_groups())
|
||||
|
||||
|
||||
def objects():
|
||||
# returns the number of objects in the project
|
||||
|
||||
return len(bpy.data.objects)
|
||||
|
||||
|
||||
def objects_unnamed():
|
||||
# returns the number of unnamed objects in the project
|
||||
|
||||
return len(unnamed.objects())
|
||||
|
||||
|
||||
def particles():
|
||||
# returns the number of particles in the project
|
||||
|
||||
return len(bpy.data.particles)
|
||||
|
||||
|
||||
def particles_unused():
|
||||
# returns the number of unused particles in the project
|
||||
|
||||
return len(unused.particles_shallow())
|
||||
|
||||
|
||||
def particles_unnamed():
|
||||
# returns the number of unnamed particle systems in the project
|
||||
|
||||
return len(unnamed.particles())
|
||||
|
||||
|
||||
def textures():
|
||||
# returns the number of textures in the project
|
||||
|
||||
return len(bpy.data.textures)
|
||||
|
||||
|
||||
def textures_unused():
|
||||
# returns the number of unused textures in the project
|
||||
|
||||
return len(unused.textures_shallow())
|
||||
|
||||
|
||||
def textures_unnamed():
|
||||
# returns the number of unnamed textures in the project
|
||||
|
||||
return len(unnamed.textures())
|
||||
|
||||
|
||||
def worlds():
|
||||
# returns the number of worlds in the project
|
||||
|
||||
return len(bpy.data.worlds)
|
||||
|
||||
|
||||
def worlds_unused():
|
||||
# returns the number of unused worlds in the project
|
||||
|
||||
return len(unused.worlds())
|
||||
|
||||
|
||||
def worlds_unnamed():
|
||||
# returns the number of unnamed worlds in the project
|
||||
|
||||
return len(unnamed.worlds())
|
||||
@@ -1,50 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains miscellaneous statistics functions.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
import os
|
||||
|
||||
|
||||
def blend_size():
|
||||
# returns the size of the current Blender file as a string
|
||||
|
||||
filepath = bpy.data.filepath
|
||||
size_bytes = os.stat(filepath).st_size if filepath != '' else -1
|
||||
|
||||
kilobyte = 1024 # bytes
|
||||
megabyte = 1048576 # bytes
|
||||
gigabyte = 1073741824 # bytes
|
||||
|
||||
if 0 <= size_bytes < kilobyte:
|
||||
size_scaled = "{:.1f} B".format(size_bytes)
|
||||
elif kilobyte <= size_bytes < megabyte:
|
||||
size_scaled = "{:.1f} KB".format(size_bytes / kilobyte)
|
||||
elif megabyte <= size_bytes < gigabyte:
|
||||
size_scaled = "{:.1f} MB".format(size_bytes / megabyte)
|
||||
elif size_bytes >= gigabyte:
|
||||
size_scaled = "{:.1f} GB".format(size_bytes / gigabyte)
|
||||
else:
|
||||
size_scaled = "No Data!"
|
||||
|
||||
return size_scaled
|
||||
@@ -1,70 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions that detect missing files in the Blender
|
||||
project.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
import os
|
||||
|
||||
|
||||
def get_missing(data):
|
||||
# returns a list of keys of unpacked data-blocks with non-existent
|
||||
# filepaths
|
||||
|
||||
missing = []
|
||||
|
||||
# list of keys that should not be flagged
|
||||
do_not_flag = ["Render Result", "Viewer Node", "D-NOISE Export"]
|
||||
|
||||
for datablock in data:
|
||||
|
||||
# the absolute path to our data-block
|
||||
abspath = bpy.path.abspath(datablock.filepath)
|
||||
|
||||
# if data-block is not packed and has an invalid filepath
|
||||
if not datablock.packed_files and not os.path.isfile(abspath):
|
||||
|
||||
# if data-block is not in our do not flag list
|
||||
# append it to the missing data list
|
||||
if datablock.name not in do_not_flag:
|
||||
missing.append(datablock.name)
|
||||
|
||||
# if data-block is packed but it does not have a filepath
|
||||
elif datablock.packed_files and not abspath:
|
||||
|
||||
# if data-block is not in our do not flag list
|
||||
# append it to the missing data list
|
||||
if datablock.name not in do_not_flag:
|
||||
missing.append(datablock.name)
|
||||
|
||||
return missing
|
||||
|
||||
|
||||
def images():
|
||||
# returns a list of keys of images with a non-existent filepath
|
||||
return get_missing(bpy.data.images)
|
||||
|
||||
|
||||
def libraries():
|
||||
# returns a list of keys of libraries with a non-existent filepath
|
||||
return get_missing(bpy.data.libraries)
|
||||
@@ -1,207 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions that detect unnamed data-blocks in the
|
||||
Blender project.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
import re
|
||||
|
||||
|
||||
def collections():
|
||||
# returns the keys of all unnamed collections in the project
|
||||
unnamed = []
|
||||
|
||||
for collection in bpy.data.collections:
|
||||
if re.match(r'.*\.\d\d\d$', collection.name) or \
|
||||
collection.name.startswith("Collection"):
|
||||
unnamed.append(collection.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def images():
|
||||
# returns the keys of all unnamed images in the project
|
||||
unnamed = []
|
||||
|
||||
for image in bpy.data.images:
|
||||
if re.match(r'.*\.\d\d\d$', image.name) or \
|
||||
image.name.startswith("Untitled"):
|
||||
unnamed.append(image.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def lights():
|
||||
# returns the keys of all unnamed lights in the project
|
||||
unnamed = []
|
||||
|
||||
for light in bpy.data.lights:
|
||||
if re.match(r'.*\.\d\d\d$', light.name) or \
|
||||
light.name.startswith("Light"):
|
||||
unnamed.append(light.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def materials():
|
||||
# returns the keys of all unnamed materials in the project
|
||||
unnamed = []
|
||||
|
||||
for material in bpy.data.lights:
|
||||
if re.match(r'.*\.\d\d\d$', material.name) or \
|
||||
material.name.startswith("Material"):
|
||||
unnamed.append(material.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def objects():
|
||||
# returns the keys of all unnamed materials in the project
|
||||
# NOTE: lists of default names must be tuples!
|
||||
|
||||
# the default names all curve objects
|
||||
curve_names = (
|
||||
"BezierCircle",
|
||||
"BezierCurve",
|
||||
"NurbsCircle",
|
||||
"NurbsCurve",
|
||||
"NurbsPath"
|
||||
)
|
||||
|
||||
# the default names of all grease pencil objects
|
||||
gpencil_names = (
|
||||
"GPencil",
|
||||
"Stroke"
|
||||
)
|
||||
|
||||
# the default names of all light objects
|
||||
light_names = (
|
||||
"Area",
|
||||
"Light",
|
||||
"Point",
|
||||
"Spot",
|
||||
"Sun"
|
||||
)
|
||||
|
||||
# the default names of all light probe objects
|
||||
lprobe_names = (
|
||||
"IrradianceVolume",
|
||||
"ReflectionCubemap",
|
||||
"ReflectionPlane"
|
||||
)
|
||||
|
||||
# the default names of all mesh objects
|
||||
mesh_names = (
|
||||
"Circle",
|
||||
"Cone",
|
||||
"Cube",
|
||||
"Cylinder",
|
||||
"Grid",
|
||||
"Icosphere",
|
||||
"Plane",
|
||||
"Sphere",
|
||||
"Torus"
|
||||
)
|
||||
|
||||
# the default names of all miscellaneous objects
|
||||
misc_names = (
|
||||
"Mball",
|
||||
"Text",
|
||||
"Armature",
|
||||
"Lattice",
|
||||
"Empty",
|
||||
"Camera",
|
||||
"Speaker",
|
||||
"Field"
|
||||
)
|
||||
|
||||
# the default names of all nurbs objects
|
||||
nurbs_names = (
|
||||
"SurfCircle",
|
||||
"SurfCurve",
|
||||
"SurfPatch",
|
||||
"SurfTorus",
|
||||
"Surface"
|
||||
)
|
||||
|
||||
# the default names of all objects compiled into one tuple
|
||||
default_obj_names = \
|
||||
curve_names + gpencil_names + light_names + lprobe_names + \
|
||||
mesh_names + misc_names + nurbs_names
|
||||
|
||||
unnamed = []
|
||||
|
||||
for obj in bpy.data.objects:
|
||||
if re.match(r'.*\.\d\d\d$', obj.name) or \
|
||||
obj.name.startswith(default_obj_names):
|
||||
unnamed.append(obj.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def node_groups():
|
||||
# returns the keys of all unnamed node groups in the project
|
||||
unnamed = []
|
||||
|
||||
for node_group in bpy.data.node_groups:
|
||||
if re.match(r'.*\.\d\d\d$', node_group.name) or \
|
||||
node_group.name.startswith("NodeGroup"):
|
||||
unnamed.append(node_group.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def particles():
|
||||
# returns the keys of all unnamed particle systems in the project
|
||||
unnamed = []
|
||||
|
||||
for particle in bpy.data.particles:
|
||||
if re.match(r'.*\.\d\d\d$', particle.name) or \
|
||||
particle.name.startswith("ParticleSettings"):
|
||||
unnamed.append(particle.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def textures():
|
||||
# returns the keys of all unnamed textures in the project
|
||||
unnamed = []
|
||||
|
||||
for texture in bpy.data.textures:
|
||||
if re.match(r'.*\.\d\d\d$', texture.name) or \
|
||||
texture.name.startswith("Texture"):
|
||||
unnamed.append(texture.name)
|
||||
|
||||
return unnamed
|
||||
|
||||
|
||||
def worlds():
|
||||
# returns the keys of all unnamed worlds in the project
|
||||
unnamed = []
|
||||
|
||||
for world in bpy.data.worlds:
|
||||
if re.match(r'.*\.\d\d\d$', world.name) or \
|
||||
world.name.startswith("World"):
|
||||
unnamed.append(world.name)
|
||||
|
||||
return unnamed
|
||||
@@ -1,244 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions that detect data-blocks that have no users,
|
||||
as determined by stats.users.py
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from atomic_data_manager import config
|
||||
from atomic_data_manager.stats import users
|
||||
|
||||
|
||||
def shallow(data):
|
||||
# returns a list of keys of unused data-blocks in the data that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
unused = []
|
||||
|
||||
for datablock in data:
|
||||
|
||||
# if data-block has no users or if it has a fake user and
|
||||
# ignore fake users is enabled
|
||||
if datablock.users == 0 or (datablock.users == 1 and
|
||||
datablock.use_fake_user and
|
||||
config.include_fake_users):
|
||||
unused.append(datablock.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def collections_deep():
|
||||
# returns a full list of keys of unused collections
|
||||
|
||||
unused = []
|
||||
|
||||
for collection in bpy.data.collections:
|
||||
if not users.collection_all(collection.name):
|
||||
unused.append(collection.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def collections_shallow():
|
||||
# returns a list of keys of unused collections that may be
|
||||
# incomplete, but is significantly faster.
|
||||
|
||||
unused = []
|
||||
|
||||
for collection in bpy.data.collections:
|
||||
if not (collection.objects or collection.children):
|
||||
unused.append(collection.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def images_deep():
|
||||
# returns a full list of keys of unused images
|
||||
|
||||
unused = []
|
||||
|
||||
# a list of image keys that should not be flagged as unused
|
||||
# this list also exists in images_shallow()
|
||||
do_not_flag = ["Render Result", "Viewer Node", "D-NOISE Export"]
|
||||
|
||||
for image in bpy.data.images:
|
||||
if not users.image_all(image.name):
|
||||
|
||||
# check if image has a fake user or if ignore fake users
|
||||
# is enabled
|
||||
if not image.use_fake_user or config.include_fake_users:
|
||||
|
||||
# if image is not in our do not flag list
|
||||
if image.name not in do_not_flag:
|
||||
unused.append(image.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def images_shallow():
|
||||
# returns a list of keys of unused images that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
unused_images = shallow(bpy.data.images)
|
||||
|
||||
# a list of image keys that should not be flagged as unused
|
||||
# this list also exists in images_deep()
|
||||
do_not_flag = ["Render Result", "Viewer Node", "D-NOISE Export"]
|
||||
|
||||
# remove do not flag keys from unused images
|
||||
for key in do_not_flag:
|
||||
if key in unused_images:
|
||||
unused_images.remove(key)
|
||||
|
||||
return unused_images
|
||||
|
||||
|
||||
def lights_deep():
|
||||
# returns a list of keys of unused lights
|
||||
|
||||
unused = []
|
||||
|
||||
for light in bpy.data.lights:
|
||||
if not users.light_all(light.name):
|
||||
|
||||
# check if light has a fake user or if ignore fake users
|
||||
# is enabled
|
||||
if not light.use_fake_user or config.include_fake_users:
|
||||
unused.append(light.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def lights_shallow():
|
||||
# returns a list of keys of unused lights that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
return shallow(bpy.data.lights)
|
||||
|
||||
|
||||
def materials_deep():
|
||||
# returns a list of keys of unused materials
|
||||
|
||||
unused = []
|
||||
|
||||
for material in bpy.data.materials:
|
||||
if not users.material_all(material.name):
|
||||
|
||||
# check if material has a fake user or if ignore fake users
|
||||
# is enabled
|
||||
if not material.use_fake_user or config.include_fake_users:
|
||||
unused.append(material.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def materials_shallow():
|
||||
# returns a list of keys of unused material that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
return shallow(bpy.data.materials)
|
||||
|
||||
|
||||
def node_groups_deep():
|
||||
# returns a list of keys of unused node_groups
|
||||
|
||||
unused = []
|
||||
|
||||
for node_group in bpy.data.node_groups:
|
||||
if not users.node_group_all(node_group.name):
|
||||
|
||||
# check if node group has a fake user or if ignore fake users
|
||||
# is enabled
|
||||
if not node_group.use_fake_user or config.include_fake_users:
|
||||
unused.append(node_group.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def node_groups_shallow():
|
||||
# returns a list of keys of unused node groups that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
return shallow(bpy.data.node_groups)
|
||||
|
||||
|
||||
def particles_deep():
|
||||
# returns a list of keys of unused particle systems
|
||||
|
||||
unused = []
|
||||
|
||||
for particle in bpy.data.particles:
|
||||
if not users.particle_all(particle.name):
|
||||
|
||||
# check if particle system has a fake user or if ignore fake
|
||||
# users is enabled
|
||||
if not particle.use_fake_user or config.include_fake_users:
|
||||
unused.append(particle.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def particles_shallow():
|
||||
# returns a list of keys of unused particle systems that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
return shallow(bpy.data.particles)
|
||||
|
||||
|
||||
def textures_deep():
|
||||
# returns a list of keys of unused textures
|
||||
|
||||
unused = []
|
||||
|
||||
for texture in bpy.data.textures:
|
||||
if not users.texture_all(texture.name):
|
||||
|
||||
# check if texture has a fake user or if ignore fake users
|
||||
# is enabled
|
||||
if not texture.use_fake_user or config.include_fake_users:
|
||||
unused.append(texture.name)
|
||||
|
||||
return unused
|
||||
|
||||
|
||||
def textures_shallow():
|
||||
# returns a list of keys of unused textures that may be
|
||||
# incomplete, but is significantly faster than doing a deep search
|
||||
|
||||
return shallow(bpy.data.textures)
|
||||
|
||||
|
||||
def worlds():
|
||||
# returns a full list of keys of unused worlds
|
||||
|
||||
unused = []
|
||||
|
||||
for world in bpy.data.worlds:
|
||||
|
||||
# if data-block has no users or if it has a fake user and
|
||||
# ignore fake users is enabled
|
||||
if world.users == 0 or (world.users == 1 and
|
||||
world.use_fake_user and
|
||||
config.include_fake_users):
|
||||
unused.append(world.name)
|
||||
|
||||
return unused
|
||||
@@ -1,786 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains functions that return the keys of data-blocks that
|
||||
use other data-blocks.
|
||||
|
||||
They are titled as such that the first part of the function name is the
|
||||
type of the data being passed in and the second part of the function name
|
||||
is the users of that type.
|
||||
|
||||
e.g. If you were searching for all of the places where an image is used in
|
||||
a material would be searching for the image_materials() function.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
|
||||
|
||||
def collection_all(collection_key):
|
||||
# returns a list of keys of every data-block that uses this collection
|
||||
|
||||
return collection_cameras(collection_key) + \
|
||||
collection_children(collection_key) + \
|
||||
collection_lights(collection_key) + \
|
||||
collection_meshes(collection_key) + \
|
||||
collection_others(collection_key)
|
||||
|
||||
|
||||
def collection_cameras(collection_key):
|
||||
# recursively returns a list of camera object keys that are in the
|
||||
# collection and its child collections
|
||||
|
||||
users = []
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
# append all camera objects in our collection
|
||||
for obj in collection.objects:
|
||||
if obj.type == 'CAMERA':
|
||||
users.append(obj.name)
|
||||
|
||||
# list of all child collections in our collection
|
||||
children = collection_children(collection_key)
|
||||
|
||||
# append all camera objects from the child collections
|
||||
for child in children:
|
||||
for obj in bpy.data.collections[child].objects:
|
||||
if obj.type == 'CAMERA':
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def collection_children(collection_key):
|
||||
# returns a list of all child collections under the specified
|
||||
# collection using recursive functions
|
||||
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
children = collection_children_recursive(collection_key)
|
||||
children.remove(collection.name)
|
||||
|
||||
return children
|
||||
|
||||
|
||||
def collection_children_recursive(collection_key):
|
||||
# recursively returns a list of all child collections under the
|
||||
# specified collection including the collection itself
|
||||
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
# base case
|
||||
if not collection.children:
|
||||
return [collection.name]
|
||||
|
||||
# recursion case
|
||||
else:
|
||||
children = []
|
||||
for child in collection.children:
|
||||
children += collection_children(child.name)
|
||||
children.append(collection.name)
|
||||
return children
|
||||
|
||||
|
||||
def collection_lights(collection_key):
|
||||
# returns a list of light object keys that are in the collection
|
||||
|
||||
users = []
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
# append all light objects in our collection
|
||||
for obj in collection.objects:
|
||||
if obj.type == 'LIGHT':
|
||||
users.append(obj.name)
|
||||
|
||||
# list of all child collections in our collection
|
||||
children = collection_children(collection_key)
|
||||
|
||||
# append all light objects from the child collections
|
||||
for child in children:
|
||||
for obj in bpy.data.collections[child].objects:
|
||||
if obj.type == 'LIGHT':
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def collection_meshes(collection_key):
|
||||
# returns a list of mesh object keys that are in the collection
|
||||
|
||||
users = []
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
# append all mesh objects in our collection and from child
|
||||
# collections
|
||||
for obj in collection.all_objects:
|
||||
if obj.type == 'MESH':
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def collection_others(collection_key):
|
||||
# returns a list of other object keys that are in the collection
|
||||
# NOTE: excludes cameras, lights, and meshes
|
||||
|
||||
users = []
|
||||
collection = bpy.data.collections[collection_key]
|
||||
|
||||
# object types to exclude from this search
|
||||
excluded_types = ['CAMERA', 'LIGHT', 'MESH']
|
||||
|
||||
# append all other objects in our collection and from child
|
||||
# collections
|
||||
for obj in collection.all_objects:
|
||||
if obj.type not in excluded_types:
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def image_all(image_key):
|
||||
# returns a list of keys of every data-block that uses this image
|
||||
|
||||
return image_compositors(image_key) + \
|
||||
image_materials(image_key) + \
|
||||
image_node_groups(image_key) + \
|
||||
image_textures(image_key) + \
|
||||
image_worlds(image_key)
|
||||
|
||||
|
||||
def image_compositors(image_key):
|
||||
# returns a list containing "Compositor" if the image is used in
|
||||
# the scene's compositor
|
||||
|
||||
users = []
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# a list of node groups that use our image
|
||||
node_group_users = image_node_groups(image_key)
|
||||
|
||||
# if our compositor uses nodes and has a valid node tree
|
||||
if bpy.context.scene.use_nodes and bpy.context.scene.node_tree:
|
||||
|
||||
# check each node in the compositor
|
||||
for node in bpy.context.scene.node_tree.nodes:
|
||||
|
||||
# if the node is an image node with a valid image
|
||||
if hasattr(node, 'image') and node.image:
|
||||
|
||||
# if the node's image is our image
|
||||
if node.image.name == image.name:
|
||||
users.append("Compositor")
|
||||
|
||||
# if the node is a group node with a valid node tree
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if the node tree's name is in our list of node group
|
||||
# users
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append("Compositor")
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def image_materials(image_key):
|
||||
# returns a list of material keys that use the image
|
||||
|
||||
users = []
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# list of node groups that use this image
|
||||
node_group_users = image_node_groups(image_key)
|
||||
|
||||
for mat in bpy.data.materials:
|
||||
|
||||
# if material uses a valid node tree, check each node
|
||||
if mat.use_nodes and mat.node_tree:
|
||||
for node in mat.node_tree.nodes:
|
||||
|
||||
# if node is has a not none image attribute
|
||||
if hasattr(node, 'image') and node.image:
|
||||
|
||||
# if the nodes image is our image
|
||||
if node.image.name == image.name:
|
||||
users.append(mat.name)
|
||||
|
||||
# if image in node in node group in node tree
|
||||
elif node.type == 'GROUP':
|
||||
|
||||
# if node group has a valid node tree and is in our
|
||||
# list of node groups that use this image
|
||||
if node.node_tree and \
|
||||
node.node_tree.name in node_group_users:
|
||||
users.append(mat.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def image_node_groups(image_key):
|
||||
# returns a list of keys of node groups that use this image
|
||||
|
||||
users = []
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# for each node group
|
||||
for node_group in bpy.data.node_groups:
|
||||
|
||||
# if node group contains our image
|
||||
if node_group_has_image(node_group.name, image.name):
|
||||
users.append(node_group.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def image_textures(image_key):
|
||||
# returns a list of texture keys that use the image
|
||||
|
||||
users = []
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# list of node groups that use this image
|
||||
node_group_users = image_node_groups(image_key)
|
||||
|
||||
for texture in bpy.data.textures:
|
||||
|
||||
# if texture uses a valid node tree, check each node
|
||||
if texture.use_nodes and texture.node_tree:
|
||||
for node in texture.node_tree.nodes:
|
||||
|
||||
# check image nodes that use this image
|
||||
if hasattr(node, 'image') and node.image:
|
||||
if node.image.name == image.name:
|
||||
users.append(texture.name)
|
||||
|
||||
# check for node groups that use this image
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if node group is in our list of node groups that
|
||||
# use this image
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append(texture.name)
|
||||
|
||||
# otherwise check the texture's image attribute
|
||||
else:
|
||||
|
||||
# if texture uses an image
|
||||
if hasattr(texture, 'image') and texture.image:
|
||||
|
||||
# if texture image is our image
|
||||
if texture.image.name == image.name:
|
||||
users.append(texture.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def image_worlds(image_key):
|
||||
# returns a list of world keys that use the image
|
||||
|
||||
users = []
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# list of node groups that use this image
|
||||
node_group_users = image_node_groups(image_key)
|
||||
|
||||
for world in bpy.data.worlds:
|
||||
|
||||
# if world uses a valid node tree, check each node
|
||||
if world.use_nodes and world.node_tree:
|
||||
for node in world.node_tree.nodes:
|
||||
|
||||
# check image nodes
|
||||
if hasattr(node, 'image') and node.image:
|
||||
if node.image.name == image.name:
|
||||
users.append(world.name)
|
||||
|
||||
# check for node groups that use this image
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append(world.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def light_all(light_key):
|
||||
# returns a list of keys of every data-block that uses this light
|
||||
|
||||
return light_objects(light_key)
|
||||
|
||||
|
||||
def light_objects(light_key):
|
||||
# returns a list of light object keys that use the light data
|
||||
|
||||
users = []
|
||||
light = bpy.data.lights[light_key]
|
||||
|
||||
for obj in bpy.data.objects:
|
||||
if obj.type == 'LIGHT' and obj.data:
|
||||
if obj.data.name == light.name:
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def material_all(material_key):
|
||||
# returns a list of keys of every data-block that uses this material
|
||||
|
||||
return material_objects(material_key)
|
||||
|
||||
|
||||
def material_objects(material_key):
|
||||
# returns a list of object keys that use this material
|
||||
|
||||
users = []
|
||||
material = bpy.data.materials[material_key]
|
||||
|
||||
for obj in bpy.data.objects:
|
||||
|
||||
# if the object has the option to add materials
|
||||
if hasattr(obj, 'material_slots'):
|
||||
|
||||
# for each material slot
|
||||
for slot in obj.material_slots:
|
||||
|
||||
# if material slot has a valid material and it is our
|
||||
# material
|
||||
if slot.material and slot.material.name == material.name:
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_all(node_group_key):
|
||||
# returns a list of keys of every data-block that uses this node group
|
||||
|
||||
return node_group_compositors(node_group_key) + \
|
||||
node_group_materials(node_group_key) + \
|
||||
node_group_node_groups(node_group_key) + \
|
||||
node_group_textures(node_group_key) + \
|
||||
node_group_worlds(node_group_key)
|
||||
|
||||
|
||||
def node_group_compositors(node_group_key):
|
||||
# returns a list containing "Compositor" if the node group is used in
|
||||
# the scene's compositor
|
||||
|
||||
users = []
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# a list of node groups that use our node group
|
||||
node_group_users = node_group_node_groups(node_group_key)
|
||||
|
||||
# if our compositor uses nodes and has a valid node tree
|
||||
if bpy.context.scene.use_nodes and bpy.context.scene.node_tree:
|
||||
|
||||
# check each node in the compositor
|
||||
for node in bpy.context.scene.node_tree.nodes:
|
||||
|
||||
# if the node is a group and has a valid node tree
|
||||
if hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if the node group is our node group
|
||||
if node.node_tree.name == node_group.name:
|
||||
users.append("Compositor")
|
||||
|
||||
# if the node group is in our list of node group users
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append("Compositor")
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_materials(node_group_key):
|
||||
# returns a list of material keys that use the node group in their
|
||||
# node trees
|
||||
|
||||
users = []
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# node groups that use this node group
|
||||
node_group_users = node_group_node_groups(node_group_key)
|
||||
|
||||
for material in bpy.data.materials:
|
||||
|
||||
# if material uses nodes and has a valid node tree, check each node
|
||||
if material.use_nodes and material.node_tree:
|
||||
for node in material.node_tree.nodes:
|
||||
|
||||
# if node is a group node
|
||||
if hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if node is the node group
|
||||
if node.node_tree.name == node_group.name:
|
||||
users.append(material.name)
|
||||
|
||||
# if node is using a node group contains our node group
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append(material.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_node_groups(node_group_key):
|
||||
# returns a list of all node groups that use this node group in
|
||||
# their node tree
|
||||
|
||||
users = []
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# for each search group
|
||||
for search_group in bpy.data.node_groups:
|
||||
|
||||
# if the search group contains our node group
|
||||
if node_group_has_node_group(
|
||||
search_group.name, node_group.name):
|
||||
users.append(search_group.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_textures(node_group_key):
|
||||
# returns a list of texture keys that use this node group in their
|
||||
# node trees
|
||||
|
||||
users = []
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# list of node groups that use this node group
|
||||
node_group_users = node_group_node_groups(node_group_key)
|
||||
|
||||
for texture in bpy.data.textures:
|
||||
|
||||
# if texture uses a valid node tree, check each node
|
||||
if texture.use_nodes and texture.node_tree:
|
||||
for node in texture.node_tree.nodes:
|
||||
|
||||
# check if node is a node group and has a valid node tree
|
||||
if hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if node is our node group
|
||||
if node.node_tree.name == node_group.name:
|
||||
users.append(texture.name)
|
||||
|
||||
# if node is a node group that contains our node group
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append(texture.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_worlds(node_group_key):
|
||||
# returns a list of world keys that use the node group in their node
|
||||
# trees
|
||||
|
||||
users = []
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# node groups that use this node group
|
||||
node_group_users = node_group_node_groups(node_group_key)
|
||||
|
||||
for world in bpy.data.worlds:
|
||||
|
||||
# if world uses nodes and has a valid node tree
|
||||
if world.use_nodes and world.node_tree:
|
||||
for node in world.node_tree.nodes:
|
||||
|
||||
# if node is a node group and has a valid node tree
|
||||
if hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if this node is our node group
|
||||
if node.node_tree.name == node_group.name:
|
||||
users.append(world.name)
|
||||
|
||||
# if this node is one of the node groups that use
|
||||
# our node group
|
||||
elif node.node_tree.name in node_group_users:
|
||||
users.append(world.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def node_group_has_image(node_group_key, image_key):
|
||||
# recursively returns true if the node group contains this image
|
||||
# directly or if it contains a node group a node group that contains
|
||||
# the image indirectly
|
||||
|
||||
has_image = False
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
image = bpy.data.images[image_key]
|
||||
|
||||
# for each node in our search group
|
||||
for node in node_group.nodes:
|
||||
|
||||
# base case
|
||||
# if node has a not none image attribute
|
||||
if hasattr(node, 'image') and node.image:
|
||||
|
||||
# if the node group is our node group
|
||||
if node.image.name == image.name:
|
||||
has_image = True
|
||||
|
||||
# recurse case
|
||||
# if node is a node group and has a valid node tree
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
has_image = node_group_has_image(
|
||||
node.node_tree.name, image.name)
|
||||
|
||||
# break the loop if the image is found
|
||||
if has_image:
|
||||
break
|
||||
|
||||
return has_image
|
||||
|
||||
|
||||
def node_group_has_node_group(search_group_key, node_group_key):
|
||||
# returns true if a node group contains this node group
|
||||
|
||||
has_node_group = False
|
||||
search_group = bpy.data.node_groups[search_group_key]
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
|
||||
# for each node in our search group
|
||||
for node in search_group.nodes:
|
||||
|
||||
# if node is a node group and has a valid node tree
|
||||
if hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
if node.node_tree.name == "RG_MetallicMap":
|
||||
print(node.node_tree.name)
|
||||
print(node_group.name)
|
||||
|
||||
# base case
|
||||
# if node group is our node group
|
||||
if node.node_tree.name == node_group.name:
|
||||
has_node_group = True
|
||||
|
||||
# recurse case
|
||||
# if node group is any other node group
|
||||
else:
|
||||
has_node_group = node_group_has_node_group(
|
||||
node.node_tree.name, node_group.name)
|
||||
|
||||
# break the loop if the node group is found
|
||||
if has_node_group:
|
||||
break
|
||||
|
||||
return has_node_group
|
||||
|
||||
|
||||
def node_group_has_texture(node_group_key, texture_key):
|
||||
# returns true if a node group contains this image
|
||||
|
||||
has_texture = False
|
||||
node_group = bpy.data.node_groups[node_group_key]
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
# for each node in our search group
|
||||
for node in node_group.nodes:
|
||||
|
||||
# base case
|
||||
# if node has a not none image attribute
|
||||
if hasattr(node, 'texture') and node.texture:
|
||||
|
||||
# if the node group is our node group
|
||||
if node.texture.name == texture.name:
|
||||
has_texture = True
|
||||
|
||||
# recurse case
|
||||
# if node is a node group and has a valid node tree
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
has_texture = node_group_has_texture(
|
||||
node.node_tree.name, texture.name)
|
||||
|
||||
# break the loop if the texture is found
|
||||
if has_texture:
|
||||
break
|
||||
|
||||
return has_texture
|
||||
|
||||
|
||||
def particle_all(particle_key):
|
||||
# returns a list of keys of every data-block that uses this particle
|
||||
# system
|
||||
|
||||
return particle_objects(particle_key)
|
||||
|
||||
|
||||
def particle_objects(particle_key):
|
||||
# returns a list of object keys that use the particle system
|
||||
|
||||
users = []
|
||||
particle_system = bpy.data.particles[particle_key]
|
||||
|
||||
for obj in bpy.data.objects:
|
||||
|
||||
# if object can have a particle system
|
||||
if hasattr(obj, 'particle_systems'):
|
||||
for particle in obj.particle_systems:
|
||||
|
||||
# if particle settings is our particle system
|
||||
if particle.settings.name == particle_system.name:
|
||||
users.append(obj.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def texture_all(texture_key):
|
||||
# returns a list of keys of every data-block that uses this texture
|
||||
|
||||
return texture_brushes(texture_key) + \
|
||||
texture_compositor(texture_key) + \
|
||||
texture_objects(texture_key) + \
|
||||
texture_node_groups(texture_key) + \
|
||||
texture_particles(texture_key)
|
||||
|
||||
|
||||
def texture_brushes(texture_key):
|
||||
# returns a list of brush keys that use the texture
|
||||
|
||||
users = []
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
for brush in bpy.data.brushes:
|
||||
|
||||
# if brush has a texture
|
||||
if brush.texture:
|
||||
|
||||
# if brush texture is our texture
|
||||
if brush.texture.name == texture.name:
|
||||
users.append(brush.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def texture_compositor(texture_key):
|
||||
# returns a list containing "Compositor" if the texture is used in
|
||||
# the scene's compositor
|
||||
|
||||
users = []
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
# a list of node groups that use our image
|
||||
node_group_users = texture_node_groups(texture_key)
|
||||
|
||||
# if our compositor uses nodes and has a valid node tree
|
||||
if bpy.context.scene.use_nodes and bpy.context.scene.node_tree:
|
||||
|
||||
# check each node in the compositor
|
||||
for node in bpy.context.scene.node_tree.nodes:
|
||||
|
||||
# if the node is an texture node with a valid texture
|
||||
if hasattr(node, 'texture') and node.texture:
|
||||
|
||||
# if the node's texture is our texture
|
||||
if node.texture.name == texture.name:
|
||||
users.append("Compositor")
|
||||
|
||||
# if the node is a group node with a valid node tree
|
||||
elif hasattr(node, 'node_tree') and node.node_tree:
|
||||
|
||||
# if the node tree's name is in our list of node group
|
||||
# users
|
||||
if node.node_tree.name in node_group_users:
|
||||
users.append("Compositor")
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def texture_objects(texture_key):
|
||||
# returns a list of object keys that use the texture in one of their
|
||||
# modifiers
|
||||
|
||||
users = []
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
# list of particle systems that use our texture
|
||||
particle_users = texture_particles(texture_key)
|
||||
|
||||
# append objects that use the texture in a modifier
|
||||
for obj in bpy.data.objects:
|
||||
|
||||
# if object can have modifiers applied to it
|
||||
if hasattr(obj, 'modifiers'):
|
||||
for modifier in obj.modifiers:
|
||||
|
||||
# if the modifier has a texture attribute that is not None
|
||||
if hasattr(modifier, 'texture') \
|
||||
and modifier.texture:
|
||||
if modifier.texture.name == texture.name:
|
||||
users.append(obj.name)
|
||||
|
||||
# if the modifier has a mask_texture attribute that is
|
||||
# not None
|
||||
elif hasattr(modifier, 'mask_texture') \
|
||||
and modifier.mask_texture:
|
||||
if modifier.mask_texture.name == texture.name:
|
||||
users.append(obj.name)
|
||||
|
||||
# append objects that use the texture in a particle system
|
||||
for particle in particle_users:
|
||||
|
||||
# append all objects that use the particle system
|
||||
users += particle_objects(particle)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def texture_node_groups(texture_key):
|
||||
# returns a list of keys of all node groups that use this texture
|
||||
|
||||
users = []
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
# for each node group
|
||||
for node_group in bpy.data.node_groups:
|
||||
|
||||
# if node group contains our texture
|
||||
if node_group_has_texture(
|
||||
node_group.name, texture.name):
|
||||
users.append(node_group.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def texture_particles(texture_key):
|
||||
# returns a list of particle system keys that use the texture in
|
||||
# their texture slots
|
||||
|
||||
users = []
|
||||
texture = bpy.data.textures[texture_key]
|
||||
|
||||
for particle in bpy.data.particles:
|
||||
|
||||
# for each texture slot in the particle system
|
||||
for texture_slot in particle.texture_slots:
|
||||
|
||||
# if texture slot has a texture that is not None
|
||||
if hasattr(texture_slot, 'texture') and texture_slot.texture:
|
||||
|
||||
# if texture in texture slot is our texture
|
||||
if texture_slot.texture.name == texture.name:
|
||||
users.append(particle.name)
|
||||
|
||||
return distinct(users)
|
||||
|
||||
|
||||
def distinct(seq):
|
||||
# returns a list of distinct elements
|
||||
|
||||
return list(set(seq))
|
||||
@@ -1,55 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file handles the registration of the atomic_data_manager.ui package
|
||||
|
||||
"""
|
||||
|
||||
from atomic_data_manager.ui import main_panel_ui
|
||||
from atomic_data_manager.ui import stats_panel_ui
|
||||
from atomic_data_manager.ui import inspect_ui
|
||||
from atomic_data_manager.ui import missing_file_ui
|
||||
from atomic_data_manager.ui import missing_file_ui
|
||||
from atomic_data_manager.ui import pie_menu_ui
|
||||
from atomic_data_manager.ui import preferences_ui
|
||||
from atomic_data_manager.ui import support_me_ui
|
||||
|
||||
|
||||
def register():
|
||||
# register preferences first so we can access variables in config.py
|
||||
preferences_ui.register()
|
||||
|
||||
# register everything else
|
||||
main_panel_ui.register()
|
||||
stats_panel_ui.register()
|
||||
inspect_ui.register()
|
||||
missing_file_ui.register()
|
||||
pie_menu_ui.register()
|
||||
support_me_ui.register()
|
||||
|
||||
|
||||
def unregister():
|
||||
main_panel_ui.unregister()
|
||||
stats_panel_ui.unregister()
|
||||
inspect_ui.unregister()
|
||||
missing_file_ui.unregister()
|
||||
pie_menu_ui.unregister()
|
||||
preferences_ui.unregister()
|
||||
support_me_ui.unregister()
|
||||
@@ -1,722 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the inspection user interface.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.stats import users
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# bool that triggers an inspection update if it is True when the
|
||||
# inspection's draw() method is called
|
||||
inspection_update_trigger = False
|
||||
|
||||
|
||||
def update_inspection(self, context):
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Collections UI Operator
|
||||
class ATOMIC_OT_inspect_collections(bpy.types.Operator):
|
||||
"""Inspect Collections"""
|
||||
bl_idname = "atomic.inspect_collections"
|
||||
bl_label = "Inspect Collections"
|
||||
|
||||
# user lists
|
||||
users_meshes = []
|
||||
users_lights = []
|
||||
users_cameras = []
|
||||
users_others = []
|
||||
users_children = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect collections box list
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="collections_field",
|
||||
data="collections"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if key is valid, update the user lists
|
||||
if atom.collections_field in bpy.data.collections.keys():
|
||||
self.users_meshes = \
|
||||
users.collection_meshes(atom.collections_field)
|
||||
self.users_lights = \
|
||||
users.collection_lights(atom.collections_field)
|
||||
self.users_cameras = \
|
||||
users.collection_cameras(atom.collections_field)
|
||||
self.users_others = \
|
||||
users.collection_others(atom.collections_field)
|
||||
self.users_children = \
|
||||
users.collection_children(atom.collections_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_meshes = []
|
||||
self.users_lights = []
|
||||
self.users_cameras = []
|
||||
self.users_others = []
|
||||
self.users_children = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# mesh box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Meshes",
|
||||
items=self.users_meshes,
|
||||
icon="OUTLINER_OB_MESH"
|
||||
)
|
||||
|
||||
# light box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Lights",
|
||||
items=self.users_lights,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
# camera box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Cameras",
|
||||
items=self.users_cameras,
|
||||
icon="OUTLINER_OB_CAMERA"
|
||||
)
|
||||
|
||||
# other objects box list
|
||||
ui_layouts.box_list_diverse(
|
||||
layout=layout,
|
||||
title="Other",
|
||||
items=self.users_others
|
||||
)
|
||||
|
||||
# child collections box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Child Collections",
|
||||
items=self.users_children,
|
||||
icon="OUTLINER_OB_GROUP_INSTANCE"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "COLLECTIONS"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Images UI Operator
|
||||
class ATOMIC_OT_inspect_images(bpy.types.Operator):
|
||||
"""Inspect Images"""
|
||||
bl_idname = "atomic.inspect_images"
|
||||
bl_label = "Inspect Images"
|
||||
|
||||
# user lists
|
||||
users_compositors = []
|
||||
users_materials = []
|
||||
users_node_groups = []
|
||||
users_textures = []
|
||||
users_worlds = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect images header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="images_field",
|
||||
data="images"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if key is valid, update the user lists
|
||||
if atom.images_field in bpy.data.images.keys():
|
||||
self.users_compositors = \
|
||||
users.image_compositors(atom.images_field)
|
||||
self.users_materials = \
|
||||
users.image_materials(atom.images_field)
|
||||
self.users_node_groups = \
|
||||
users.image_node_groups(atom.images_field)
|
||||
self.users_textures = \
|
||||
users.image_textures(atom.images_field)
|
||||
self.users_worlds = \
|
||||
users.image_worlds(atom.images_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_compositors = []
|
||||
self.users_materials = []
|
||||
self.users_node_groups = []
|
||||
self.users_textures = []
|
||||
self.users_worlds = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# compositors box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Compositors",
|
||||
items=self.users_compositors,
|
||||
icon="NODE_COMPOSITING"
|
||||
)
|
||||
|
||||
# materials box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=self.users_materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
# node groups box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=self.users_node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
# textures box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=self.users_textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
# worlds box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=self.users_worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "IMAGES"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
# Atomic Data Manager Inspect Lights UI Operator
|
||||
class ATOMIC_OT_inspect_lights(bpy.types.Operator):
|
||||
"""Inspect Lights"""
|
||||
bl_idname = "atomic.inspect_lights"
|
||||
bl_label = "Inspect Lights"
|
||||
|
||||
# user lists
|
||||
users_objects = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect lights header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="lights_field",
|
||||
data="lights"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
# if key is valid, update the user lists
|
||||
if atom.lights_field in bpy.data.lights.keys():
|
||||
self.users_objects = users.light_objects(atom.lights_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_objects = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# light objects box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Light Objects",
|
||||
items=self.users_objects,
|
||||
icon="OUTLINER_OB_LIGHT"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "LIGHTS"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Materials UI Operator
|
||||
class ATOMIC_OT_inspect_materials(bpy.types.Operator):
|
||||
"""Inspect Materials"""
|
||||
bl_idname = "atomic.inspect_materials"
|
||||
bl_label = "Inspect Materials"
|
||||
|
||||
# user lists
|
||||
users_objects = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect materials header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="materials_field",
|
||||
data="materials"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if key is valid, update the user lists
|
||||
if atom.materials_field in bpy.data.materials.keys():
|
||||
self.users_objects = \
|
||||
users.material_objects(atom.materials_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_objects = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# objects box list
|
||||
ui_layouts.box_list_diverse(
|
||||
layout=layout,
|
||||
title="Objects",
|
||||
items=self.users_objects
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "MATERIALS"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Node Groups UI Operator
|
||||
class ATOMIC_OT_inspect_node_groups(bpy.types.Operator):
|
||||
"""Inspect Node Groups"""
|
||||
bl_idname = "atomic.inspect_node_groups"
|
||||
bl_label = "Inspect Node Groups"
|
||||
|
||||
# user lists
|
||||
users_compositors = []
|
||||
users_materials = []
|
||||
users_node_groups = []
|
||||
users_textures = []
|
||||
users_worlds = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect node groups header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="node_groups_field",
|
||||
data="node_groups"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if key is valid, update the user lists
|
||||
if atom.node_groups_field in bpy.data.node_groups.keys():
|
||||
|
||||
self.users_compositors = \
|
||||
users.node_group_compositors(atom.node_groups_field)
|
||||
self.users_materials = \
|
||||
users.node_group_materials(atom.node_groups_field)
|
||||
self.users_node_groups = \
|
||||
users.node_group_node_groups(atom.node_groups_field)
|
||||
self.users_textures = \
|
||||
users.node_group_textures(atom.node_groups_field)
|
||||
self.users_worlds = \
|
||||
users.node_group_worlds(atom.node_groups_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_compositors = []
|
||||
self.users_materials = []
|
||||
self.users_node_groups = []
|
||||
self.users_textures = []
|
||||
self.users_worlds = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# compositors box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Compositors",
|
||||
items=self.users_compositors,
|
||||
icon="NODE_COMPOSITING"
|
||||
)
|
||||
|
||||
# materials box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Materials",
|
||||
items=self.users_materials,
|
||||
icon="MATERIAL"
|
||||
)
|
||||
|
||||
# node groups box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Node Groups",
|
||||
items=self.users_node_groups,
|
||||
icon="NODETREE"
|
||||
)
|
||||
|
||||
# textures box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Textures",
|
||||
items=self.users_textures,
|
||||
icon="TEXTURE"
|
||||
)
|
||||
|
||||
# world box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds",
|
||||
items=self.users_worlds,
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "NODE_GROUPS"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Particles UI Operator
|
||||
class ATOMIC_OT_inspect_particles(bpy.types.Operator):
|
||||
"""Inspect Particle Systems"""
|
||||
bl_idname = "atomic.inspect_particles"
|
||||
bl_label = "Inspect Particles"
|
||||
|
||||
# user lists
|
||||
users_objects = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect particles header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="particles_field",
|
||||
data="particles"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if key is valid, update the user lists
|
||||
if atom.particles_field in bpy.data.particles.keys():
|
||||
|
||||
self.users_objects = \
|
||||
users.particle_objects(atom.particles_field)
|
||||
|
||||
# if key is invalid, empty the user lists
|
||||
else:
|
||||
self.users_objects = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# objects box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Objects",
|
||||
items=self.users_objects,
|
||||
icon="OUTLINER_OB_MESH"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "PARTICLES"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Textures UI Operator
|
||||
class ATOMIC_OT_inspect_textures(bpy.types.Operator):
|
||||
"""Inspect Textures"""
|
||||
bl_idname = "atomic.inspect_textures"
|
||||
bl_label = "Inspect Textures"
|
||||
|
||||
# user lists
|
||||
users_compositors = []
|
||||
users_brushes = []
|
||||
users_particles = []
|
||||
users_objects = []
|
||||
|
||||
def draw(self, context):
|
||||
global inspection_update_trigger
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
layout = self.layout
|
||||
|
||||
# inspect textures header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="textures_field",
|
||||
data="textures"
|
||||
)
|
||||
|
||||
# inspection update code
|
||||
if inspection_update_trigger:
|
||||
|
||||
# if the key is valid, update the user lists
|
||||
if atom.textures_field in bpy.data.textures.keys():
|
||||
|
||||
self.users_compositors = \
|
||||
users.texture_compositor(atom.textures_field)
|
||||
self.users_brushes = \
|
||||
users.texture_brushes(atom.textures_field)
|
||||
self.users_objects = \
|
||||
users.texture_objects(atom.textures_field)
|
||||
self.users_particles = \
|
||||
users.texture_particles(atom.textures_field)
|
||||
|
||||
# if the key is invalid, set empty the user lists
|
||||
else:
|
||||
self.users_compositors = []
|
||||
self.users_brushes = []
|
||||
self.users_particles = []
|
||||
self.users_objects = []
|
||||
|
||||
inspection_update_trigger = False
|
||||
|
||||
# brushes box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Brushes",
|
||||
items=self.users_brushes,
|
||||
icon="BRUSH_DATA"
|
||||
)
|
||||
|
||||
# compositors box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Compositors",
|
||||
items=self.users_compositors,
|
||||
icon="NODE_COMPOSITING"
|
||||
)
|
||||
|
||||
# particles box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Particles",
|
||||
items=self.users_particles,
|
||||
icon="PARTICLES"
|
||||
)
|
||||
|
||||
# objects box list
|
||||
ui_layouts.box_list_diverse(
|
||||
layout=layout,
|
||||
title="Objects",
|
||||
items=self.users_objects,
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "TEXTURES"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Worlds UI Operator
|
||||
class ATOMIC_OT_inspect_worlds(bpy.types.Operator):
|
||||
"""Inspect Worlds"""
|
||||
bl_idname = "atomic.inspect_worlds"
|
||||
bl_label = "Inspect Worlds"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# inspect worlds header
|
||||
ui_layouts.inspect_header(
|
||||
layout=layout,
|
||||
atom_prop="worlds_field",
|
||||
data="worlds"
|
||||
)
|
||||
|
||||
# worlds box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Worlds in Scene",
|
||||
items=bpy.data.worlds.keys(),
|
||||
icon="WORLD"
|
||||
)
|
||||
|
||||
row = layout.row() # extra row for spacing
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# update inspection context
|
||||
atom = bpy.context.scene.atomic
|
||||
atom.active_inspection = "WORLDS"
|
||||
|
||||
# trigger update on invoke
|
||||
global inspection_update_trigger
|
||||
inspection_update_trigger = True
|
||||
|
||||
# invoke inspect dialog
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_OT_inspect_collections,
|
||||
ATOMIC_OT_inspect_images,
|
||||
ATOMIC_OT_inspect_lights,
|
||||
ATOMIC_OT_inspect_materials,
|
||||
ATOMIC_OT_inspect_node_groups,
|
||||
ATOMIC_OT_inspect_particles,
|
||||
ATOMIC_OT_inspect_textures,
|
||||
ATOMIC_OT_inspect_worlds
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
@@ -1,245 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the primary Atomic Data Manager panel that will
|
||||
appear in the Scene tab of the Properties panel.
|
||||
|
||||
This panel contains the Nuke/Clean/Undo buttons as well as the data
|
||||
category toggles and the category selection tools.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.stats import count
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# Atomic Data Manager Main Panel
|
||||
class ATOMIC_PT_main_panel(bpy.types.Panel):
|
||||
"""The main Atomic Data Manager panel"""
|
||||
bl_label = "Atomic Data Manager"
|
||||
bl_space_type = "PROPERTIES"
|
||||
bl_region_type = "WINDOW"
|
||||
bl_context = "scene"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
atom = bpy.context.scene.atomic
|
||||
category_props = [
|
||||
atom.collections,
|
||||
atom.images,
|
||||
atom.lights,
|
||||
atom.materials,
|
||||
atom.node_groups,
|
||||
atom.particles,
|
||||
atom.textures,
|
||||
atom.worlds
|
||||
]
|
||||
|
||||
# nuke and clean buttons
|
||||
row = layout.row(align=True)
|
||||
row.scale_y = 2.0
|
||||
row.operator("atomic.nuke", text="Nuke", icon="GHOST_ENABLED")
|
||||
row.operator("atomic.clean", text="Clean", icon="PARTICLEMODE")
|
||||
row.operator("atomic.undo", text="Undo", icon="LOOP_BACK")
|
||||
|
||||
row = layout.row()
|
||||
|
||||
# category toggles
|
||||
split = layout.split(align=False)
|
||||
|
||||
# left column
|
||||
col = split.column(align=True)
|
||||
|
||||
# collections buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"collections",
|
||||
text="Collections",
|
||||
icon='GROUP',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_collections",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# lights buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"lights",
|
||||
text="Lights",
|
||||
icon='LIGHT',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_lights",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# node groups buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"node_groups",
|
||||
text="Node Groups",
|
||||
icon='NODETREE',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_node_groups",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# textures button
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"textures",
|
||||
text="Textures",
|
||||
icon='TEXTURE',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_textures",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# right column
|
||||
col = split.column(align=True)
|
||||
|
||||
# images buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"images",
|
||||
text="Images",
|
||||
toggle=True,
|
||||
icon='IMAGE_DATA'
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_images",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# materials buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"materials",
|
||||
text="Materials",
|
||||
icon='MATERIAL',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_materials",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# particles buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"particles",
|
||||
text="Particles",
|
||||
icon='PARTICLES',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_particles",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# worlds buttons
|
||||
splitcol = col.split(factor=0.8, align=True)
|
||||
splitcol.prop(
|
||||
atom,
|
||||
"worlds",
|
||||
text="Worlds",
|
||||
icon='WORLD',
|
||||
toggle=True
|
||||
)
|
||||
|
||||
splitcol.operator(
|
||||
"atomic.inspect_worlds",
|
||||
icon='VIEWZOOM',
|
||||
text=""
|
||||
)
|
||||
|
||||
# selection operators
|
||||
row = layout.row(align=True)
|
||||
|
||||
row.operator(
|
||||
"atomic.smart_select",
|
||||
text='Smart Select',
|
||||
icon='ZOOM_SELECTED'
|
||||
)
|
||||
|
||||
if all(prop is True for prop in category_props):
|
||||
row.operator(
|
||||
"atomic.deselect_all",
|
||||
text="Deselect All",
|
||||
icon='RESTRICT_SELECT_ON'
|
||||
)
|
||||
|
||||
else:
|
||||
row.operator(
|
||||
"atomic.select_all",
|
||||
text="Select All",
|
||||
icon='RESTRICT_SELECT_OFF'
|
||||
)
|
||||
|
||||
|
||||
reg_list = [ATOMIC_PT_main_panel]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
@@ -1,195 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the user interface for the missing file dialog that
|
||||
pops up when missing files are detected on file load.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from bpy.app.handlers import persistent
|
||||
from atomic_data_manager import config
|
||||
from atomic_data_manager.stats import missing
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# Atomic Data Manager Detect Missing Files Popup
|
||||
class ATOMIC_OT_detect_missing(bpy.types.Operator):
|
||||
"""Detect missing files in this project"""
|
||||
bl_idname = "atomic.detect_missing"
|
||||
bl_label = "Missing File Detection"
|
||||
|
||||
# missing file lists
|
||||
missing_images = []
|
||||
missing_libraries = []
|
||||
|
||||
# missing file recovery option enum property
|
||||
recovery_option: bpy.props.EnumProperty(
|
||||
items=[
|
||||
(
|
||||
'IGNORE',
|
||||
'Ignore Missing Files',
|
||||
'Ignore the missing files and leave them offline'
|
||||
),
|
||||
(
|
||||
'RELOAD',
|
||||
'Reload Missing Files',
|
||||
'Reload the missing files from their existing file paths'
|
||||
),
|
||||
(
|
||||
'REMOVE',
|
||||
'Remove Missing Files',
|
||||
'Remove the missing files from the project'
|
||||
),
|
||||
(
|
||||
'SEARCH',
|
||||
'Search for Missing Files (under development)',
|
||||
'Search for the missing files in a directory'
|
||||
),
|
||||
(
|
||||
'REPLACE',
|
||||
'Specify Replacement Files (under development)',
|
||||
'Replace missing files with new files'
|
||||
),
|
||||
],
|
||||
default='IGNORE'
|
||||
)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# missing files interface if missing files are found
|
||||
if self.missing_images or self.missing_libraries:
|
||||
|
||||
# header warning
|
||||
row = layout.row()
|
||||
row.label(
|
||||
text="Atomic has detected one or more missing files in "
|
||||
"your project!"
|
||||
)
|
||||
|
||||
# missing images box list
|
||||
if self.missing_images:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Images",
|
||||
items=self.missing_images,
|
||||
icon="IMAGE_DATA",
|
||||
columns=3
|
||||
)
|
||||
|
||||
# missing libraries box list
|
||||
if self.missing_libraries:
|
||||
ui_layouts.box_list(
|
||||
layout=layout,
|
||||
title="Libraries",
|
||||
items=self.missing_libraries,
|
||||
icon="LIBRARY_DATA_DIRECT",
|
||||
columns=3
|
||||
)
|
||||
|
||||
row = layout.separator() # extra space
|
||||
|
||||
# recovery option selection
|
||||
row = layout.row()
|
||||
row.label(text="What would you like to do?")
|
||||
|
||||
row = layout.row()
|
||||
row.prop(self, 'recovery_option', text="")
|
||||
|
||||
# missing files interface if no missing files are found
|
||||
else:
|
||||
row = layout.row()
|
||||
row.label(text="No missing files were found!")
|
||||
|
||||
# empty box list
|
||||
ui_layouts.box_list(
|
||||
layout=layout
|
||||
)
|
||||
|
||||
row = layout.separator() # extra space
|
||||
|
||||
def execute(self, context):
|
||||
|
||||
# ignore missing files will take no action
|
||||
|
||||
# reload missing files
|
||||
if self.recovery_option == 'RELOAD':
|
||||
bpy.ops.atomic.reload_missing('INVOKE_DEFAULT')
|
||||
|
||||
# remove missing files
|
||||
elif self.recovery_option == 'REMOVE':
|
||||
bpy.ops.atomic.remove_missing('INVOKE_DEFAULT')
|
||||
|
||||
# search for missing files
|
||||
elif self.recovery_option == 'SEARCH':
|
||||
bpy.ops.atomic.search_missing('INVOKE_DEFAULT')
|
||||
|
||||
# replace missing files
|
||||
elif self.recovery_option == 'REPLACE':
|
||||
bpy.ops.atomic.replace_missing('INVOKE_DEFAULT')
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
|
||||
# update missing file lists
|
||||
self.missing_images = missing.images()
|
||||
self.missing_libraries = missing.libraries()
|
||||
|
||||
wm = context.window_manager
|
||||
|
||||
# invoke large dialog if there are missing files
|
||||
if self.missing_images or self.missing_libraries:
|
||||
return wm.invoke_props_dialog(self, width=500)
|
||||
|
||||
# invoke small dialog if there are no missing files
|
||||
else:
|
||||
return wm.invoke_popup(self, width=300)
|
||||
|
||||
|
||||
@persistent
|
||||
def autodetect_missing_files(dummy=None):
|
||||
# invokes the detect missing popup when missing files are detected upon
|
||||
# loading a new Blender project
|
||||
if config.enable_missing_file_warning and \
|
||||
(missing.images() or missing.libraries()):
|
||||
bpy.ops.atomic.detect_missing('INVOKE_DEFAULT')
|
||||
|
||||
|
||||
reg_list = [ATOMIC_OT_detect_missing]
|
||||
|
||||
|
||||
def register():
|
||||
for item in reg_list:
|
||||
register_class(item)
|
||||
|
||||
# run missing file auto-detection after loading a Blender file
|
||||
bpy.app.handlers.load_post.append(autodetect_missing_files)
|
||||
|
||||
|
||||
def unregister():
|
||||
for item in reg_list:
|
||||
unregister_class(item)
|
||||
|
||||
# stop running missing file auto-detection after loading a Blender file
|
||||
bpy.app.handlers.load_post.remove(autodetect_missing_files)
|
||||
@@ -1,200 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains Atomic's pie menu UI and its pie menu keymap
|
||||
registration.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
|
||||
|
||||
# Atomic Data Manager Main Pie Menu
|
||||
class ATOMIC_MT_main_pie(bpy.types.Menu):
|
||||
bl_idname = "ATOMIC_MT_main_pie"
|
||||
bl_label = "Atomic Data Manager"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
pie = layout.menu_pie()
|
||||
|
||||
# nuke all operator
|
||||
pie.operator(
|
||||
"atomic.nuke_all",
|
||||
text="Nuke All",
|
||||
icon="GHOST_ENABLED"
|
||||
)
|
||||
|
||||
# clean all operator
|
||||
pie.operator(
|
||||
"atomic.clean_all",
|
||||
text="Clean All",
|
||||
icon="PARTICLEMODE"
|
||||
)
|
||||
|
||||
# undo operator
|
||||
pie.operator(
|
||||
"atomic.detect_missing",
|
||||
text="Detect Missing Files",
|
||||
icon="SHADERFX"
|
||||
)
|
||||
|
||||
# inspect category operator
|
||||
pie.operator(
|
||||
"wm.call_menu_pie",
|
||||
text="Inspect",
|
||||
icon="VIEWZOOM"
|
||||
).name = "ATOMIC_MT_inspect_pie"
|
||||
|
||||
# nuke category operator
|
||||
pie.operator(
|
||||
"wm.call_menu_pie",
|
||||
text="Nuke",
|
||||
icon="GHOST_ENABLED"
|
||||
).name = "ATOMIC_MT_nuke_pie"
|
||||
|
||||
# clean category operator
|
||||
pie.operator(
|
||||
"wm.call_menu_pie",
|
||||
text="Clean",
|
||||
icon="PARTICLEMODE"
|
||||
).name = "ATOMIC_MT_clean_pie"
|
||||
|
||||
|
||||
# Atomic Data Manager Nuke Pie Menu
|
||||
class ATOMIC_MT_nuke_pie(bpy.types.Menu):
|
||||
bl_idname = "ATOMIC_MT_nuke_pie"
|
||||
bl_label = "Atomic Nuke"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
pie = layout.menu_pie()
|
||||
|
||||
# nuke node groups operator
|
||||
pie.operator("atomic.nuke_node_groups", icon="NODETREE")
|
||||
|
||||
# nuke materials operator
|
||||
pie.operator("atomic.nuke_materials", icon="MATERIAL")
|
||||
|
||||
# nuke worlds operator
|
||||
pie.operator("atomic.nuke_worlds", icon="WORLD")
|
||||
|
||||
# nuke collections operator
|
||||
pie.operator("atomic.nuke_collections", icon="GROUP")
|
||||
|
||||
# nuke lights operator
|
||||
pie.operator("atomic.nuke_lights", icon="LIGHT")
|
||||
|
||||
# nuke images operator
|
||||
pie.operator("atomic.nuke_images", icon="IMAGE_DATA")
|
||||
|
||||
# nuke textures operator
|
||||
pie.operator("atomic.nuke_textures", icon="TEXTURE")
|
||||
|
||||
# nuke particles operator
|
||||
pie.operator("atomic.nuke_particles", icon="PARTICLES")
|
||||
|
||||
|
||||
# Atomic Data Manager Clean Pie Menu
|
||||
class ATOMIC_MT_clean_pie(bpy.types.Menu):
|
||||
bl_idname = "ATOMIC_MT_clean_pie"
|
||||
bl_label = "Atomic Clean"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
pie = layout.menu_pie()
|
||||
|
||||
# clean node groups operator
|
||||
pie.operator("atomic.clean_node_groups", icon="NODETREE")
|
||||
|
||||
# clean materials operator
|
||||
pie.operator("atomic.clean_materials", icon="MATERIAL")
|
||||
|
||||
# clean worlds operator
|
||||
pie.operator("atomic.clean_worlds", icon="WORLD")
|
||||
|
||||
# clean collections operator
|
||||
pie.operator("atomic.clean_collections", icon="GROUP")
|
||||
|
||||
# clean lights operator
|
||||
pie.operator("atomic.clean_lights", icon="LIGHT")
|
||||
|
||||
# clean images operator
|
||||
pie.operator("atomic.clean_images", icon="IMAGE_DATA")
|
||||
|
||||
# clean textures operator
|
||||
pie.operator("atomic.clean_textures", icon="TEXTURE")
|
||||
|
||||
# clean materials operator
|
||||
pie.operator("atomic.clean_particles", icon="PARTICLES")
|
||||
|
||||
|
||||
# Atomic Data Manager Inspect Pie Menu
|
||||
class ATOMIC_MT_inspect_pie(bpy.types.Menu):
|
||||
bl_idname = "ATOMIC_MT_inspect_pie"
|
||||
bl_label = "Atomic Inspect"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
pie = layout.menu_pie()
|
||||
|
||||
# inspect node groups operator
|
||||
pie.operator("atomic.inspect_node_groups", icon="NODETREE")
|
||||
|
||||
# inspect materials operator
|
||||
pie.operator("atomic.inspect_materials", icon="MATERIAL")
|
||||
|
||||
# inspect worlds operator
|
||||
pie.operator("atomic.inspect_worlds", icon="WORLD")
|
||||
|
||||
# inspect groups operator
|
||||
pie.operator("atomic.inspect_collections", icon="GROUP")
|
||||
|
||||
# inspect lights operator
|
||||
pie.operator("atomic.inspect_lights", icon="LIGHT")
|
||||
|
||||
# inspect images operator
|
||||
pie.operator("atomic.inspect_images", icon="IMAGE_DATA")
|
||||
|
||||
# inspect textures operator
|
||||
pie.operator("atomic.inspect_textures", icon="TEXTURE")
|
||||
|
||||
# inspect particles operator
|
||||
pie.operator("atomic.inspect_particles", icon="PARTICLES")
|
||||
|
||||
|
||||
reg_list = [
|
||||
ATOMIC_MT_main_pie,
|
||||
ATOMIC_MT_nuke_pie,
|
||||
ATOMIC_MT_clean_pie,
|
||||
ATOMIC_MT_inspect_pie
|
||||
]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
@@ -1,350 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the Atomic preferences UI, preferences properties, and
|
||||
some functions for syncing the preference properties with external factors.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager import config
|
||||
from atomic_data_manager.updater import addon_updater_ops
|
||||
|
||||
|
||||
def set_enable_support_me_popup(value):
|
||||
# sets the value of the enable_support_me_popup boolean property
|
||||
|
||||
bpy.context.preferences.addons["atomic_data_manager"]\
|
||||
.preferences.enable_support_me_popup = value
|
||||
copy_prefs_to_config(None, None)
|
||||
bpy.ops.wm.save_userpref()
|
||||
|
||||
|
||||
def set_last_popup_day(day):
|
||||
# sets the value of the last_popup_day float property
|
||||
|
||||
bpy.context.preferences.addons["atomic_data_manager"]\
|
||||
.preferences.last_popup_day = day
|
||||
copy_prefs_to_config(None, None)
|
||||
|
||||
|
||||
def copy_prefs_to_config(self, context):
|
||||
# copies the values of Atomic's preferences to the variables in
|
||||
# config.py for global use
|
||||
|
||||
preferences = bpy.context.preferences
|
||||
|
||||
atomic_preferences = preferences.addons['atomic_data_manager']\
|
||||
.preferences
|
||||
|
||||
# visible atomic preferences
|
||||
config.enable_missing_file_warning = \
|
||||
atomic_preferences.enable_missing_file_warning
|
||||
|
||||
config.enable_pie_menu_ui = \
|
||||
atomic_preferences.enable_pie_menu_ui
|
||||
|
||||
config.enable_support_me_popup = \
|
||||
atomic_preferences.enable_support_me_popup
|
||||
|
||||
config.include_fake_users = \
|
||||
atomic_preferences.include_fake_users
|
||||
|
||||
# hidden atomic preferences
|
||||
config.pie_menu_type = \
|
||||
atomic_preferences.pie_menu_type
|
||||
|
||||
config.pie_menu_alt = \
|
||||
atomic_preferences.pie_menu_alt
|
||||
|
||||
config.pie_menu_any = \
|
||||
atomic_preferences.pie_menu_any
|
||||
|
||||
config.pie_menu_ctrl = \
|
||||
atomic_preferences.pie_menu_ctrl
|
||||
|
||||
config.pie_menu_oskey = \
|
||||
atomic_preferences.pie_menu_oskey
|
||||
|
||||
config.pie_menu_shift = \
|
||||
atomic_preferences.pie_menu_shift
|
||||
|
||||
config.last_popup_day = \
|
||||
atomic_preferences.last_popup_day
|
||||
|
||||
|
||||
def update_pie_menu_hotkeys(self, context):
|
||||
preferences = bpy.context.preferences
|
||||
atomic_preferences = preferences.addons['atomic_data_manager'] \
|
||||
.preferences
|
||||
|
||||
# add the hotkeys if the preference is enabled
|
||||
if atomic_preferences.enable_pie_menu_ui:
|
||||
add_pie_menu_hotkeys()
|
||||
|
||||
# remove the hotkeys otherwise
|
||||
else:
|
||||
remove_pie_menu_hotkeys()
|
||||
|
||||
|
||||
def add_pie_menu_hotkeys():
|
||||
# adds the pie menu hotkeys to blender's addon keymaps
|
||||
|
||||
global keymaps
|
||||
keyconfigs = bpy.context.window_manager.keyconfigs.addon
|
||||
|
||||
# check to see if a window keymap already exists
|
||||
if "Window" in keyconfigs.keymaps.keys():
|
||||
km = keyconfigs.keymaps['Window']
|
||||
|
||||
# if not, crate a new one
|
||||
else:
|
||||
km = keyconfigs.keymaps.new(
|
||||
name="Window",
|
||||
space_type='EMPTY',
|
||||
region_type='WINDOW'
|
||||
)
|
||||
|
||||
# add a new keymap item to that keymap
|
||||
kmi = km.keymap_items.new(
|
||||
idname="atomic.invoke_pie_menu_ui",
|
||||
type=config.pie_menu_type,
|
||||
value="PRESS",
|
||||
alt=config.pie_menu_alt,
|
||||
any=config.pie_menu_any,
|
||||
ctrl=config.pie_menu_ctrl,
|
||||
oskey=config.pie_menu_oskey,
|
||||
shift=config.pie_menu_shift,
|
||||
)
|
||||
|
||||
# # point the keymap item to our pie menu
|
||||
# kmi.properties.name = "ATOMIC_MT_main_pie"
|
||||
keymaps.append((km, kmi))
|
||||
|
||||
|
||||
def remove_pie_menu_hotkeys():
|
||||
# removes the pie menu hotkeys from blender's addon keymaps if they
|
||||
# exist there
|
||||
|
||||
global keymaps
|
||||
|
||||
# remove each hotkey in our keymaps list if it exists in blenders
|
||||
# addon keymaps
|
||||
for km, kmi in keymaps:
|
||||
km.keymap_items.remove(kmi)
|
||||
|
||||
# clear our keymaps list
|
||||
keymaps.clear()
|
||||
|
||||
|
||||
# Atomic Data Manager Preference Panel UI
|
||||
class ATOMIC_PT_preferences_panel(bpy.types.AddonPreferences):
|
||||
bl_idname = "atomic_data_manager"
|
||||
|
||||
# visible atomic preferences
|
||||
enable_missing_file_warning: bpy.props.BoolProperty(
|
||||
description="Display a warning on startup if Atomic detects "
|
||||
"missing files in your project",
|
||||
default=True
|
||||
)
|
||||
|
||||
enable_support_me_popup: bpy.props.BoolProperty(
|
||||
description="Occasionally display a popup asking if you would "
|
||||
"like to support Remington Creative",
|
||||
default=True
|
||||
)
|
||||
|
||||
include_fake_users: bpy.props.BoolProperty(
|
||||
description="Include data-blocks with only fake users in unused "
|
||||
"data detection",
|
||||
default=False
|
||||
)
|
||||
|
||||
enable_pie_menu_ui: bpy.props.BoolProperty(
|
||||
description="Enable the Atomic pie menu UI, so you can clean "
|
||||
"your project from anywhere.",
|
||||
default=True,
|
||||
update=update_pie_menu_hotkeys
|
||||
)
|
||||
|
||||
# hidden atomic preferences
|
||||
pie_menu_type: bpy.props.StringProperty(
|
||||
default="D"
|
||||
)
|
||||
|
||||
pie_menu_alt: bpy.props.BoolProperty(
|
||||
default=False
|
||||
)
|
||||
|
||||
pie_menu_any: bpy.props.BoolProperty(
|
||||
default=False
|
||||
)
|
||||
|
||||
pie_menu_ctrl: bpy.props.BoolProperty(
|
||||
default=False
|
||||
)
|
||||
|
||||
pie_menu_oskey: bpy.props.BoolProperty(
|
||||
default=False
|
||||
)
|
||||
|
||||
pie_menu_shift: bpy.props.BoolProperty(
|
||||
default=False
|
||||
)
|
||||
|
||||
last_popup_day: bpy.props.FloatProperty(
|
||||
default=0
|
||||
)
|
||||
|
||||
# add-on updater properties
|
||||
auto_check_update: bpy.props.BoolProperty(
|
||||
name="Auto-check for Update",
|
||||
description="If enabled, auto-check for updates using an interval",
|
||||
default=True,
|
||||
)
|
||||
|
||||
updater_intrval_months: bpy.props.IntProperty(
|
||||
name='Months',
|
||||
description="Number of months between checking for updates",
|
||||
default=0,
|
||||
min=0,
|
||||
max=6
|
||||
)
|
||||
updater_intrval_days: bpy.props.IntProperty(
|
||||
name='Days',
|
||||
description="Number of days between checking for updates",
|
||||
default=7,
|
||||
min=0,
|
||||
)
|
||||
updater_intrval_hours: bpy.props.IntProperty(
|
||||
name='Hours',
|
||||
description="Number of hours between checking for updates",
|
||||
default=0,
|
||||
min=0,
|
||||
max=23
|
||||
)
|
||||
updater_intrval_minutes: bpy.props.IntProperty(
|
||||
name='Minutes',
|
||||
description="Number of minutes between checking for updates",
|
||||
default=0,
|
||||
min=0,
|
||||
max=59
|
||||
)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
split = layout.split()
|
||||
|
||||
# left column
|
||||
col = split.column()
|
||||
|
||||
# enable missing file warning toggle
|
||||
col.prop(
|
||||
self,
|
||||
"enable_missing_file_warning",
|
||||
text="Show Missing File Warning"
|
||||
)
|
||||
|
||||
# enable support me popup toggle
|
||||
col.prop(
|
||||
self,
|
||||
"enable_support_me_popup",
|
||||
text="Show \"Support Me\" Popup"
|
||||
)
|
||||
|
||||
# right column
|
||||
col = split.column()
|
||||
|
||||
# ignore fake users toggle
|
||||
col.prop(
|
||||
self,
|
||||
"include_fake_users",
|
||||
text="Include Fake Users"
|
||||
)
|
||||
|
||||
# pie menu settings
|
||||
pie_split = col.split(factor=0.55) # nice
|
||||
|
||||
# enable pie menu ui toggle
|
||||
pie_split.prop(
|
||||
self,
|
||||
"enable_pie_menu_ui",
|
||||
text="Enable Pie Menu"
|
||||
)
|
||||
|
||||
# put the property in a row so it can be disabled
|
||||
pie_row = pie_split.row()
|
||||
pie_row.enabled = self.enable_pie_menu_ui
|
||||
|
||||
if pie_row.enabled:
|
||||
# keymap item that contains our pie menu hotkey
|
||||
# note: keymap item index hardcoded with an index -- may be
|
||||
# dangerous if more keymap items are added
|
||||
kmi = bpy.context.window_manager.keyconfigs.addon.keymaps[
|
||||
'Window'].keymap_items[0]
|
||||
|
||||
# hotkey property
|
||||
pie_row.prop(
|
||||
kmi,
|
||||
"type",
|
||||
text="",
|
||||
full_event=True
|
||||
)
|
||||
|
||||
# update hotkey preferences
|
||||
self.pie_menu_type = kmi.type
|
||||
self.pie_menu_any = kmi.any
|
||||
self.pie_menu_alt = kmi.alt
|
||||
self.pie_menu_ctrl = kmi.ctrl
|
||||
self.pie_menu_oskey = kmi.oskey
|
||||
self.pie_menu_shift = kmi.shift
|
||||
|
||||
separator = layout.row() # extra space
|
||||
|
||||
# add-on updater box
|
||||
addon_updater_ops.update_settings_ui(self, context)
|
||||
|
||||
# update config with any new preferences
|
||||
copy_prefs_to_config(None, None)
|
||||
|
||||
|
||||
reg_list = [ATOMIC_PT_preferences_panel]
|
||||
keymaps = []
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
# make sure global preferences are updated on registration
|
||||
copy_prefs_to_config(None, None)
|
||||
|
||||
# update keymaps
|
||||
add_pie_menu_hotkeys()
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
|
||||
remove_pie_menu_hotkeys()
|
||||
@@ -1,376 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the user interface for Atomic's statistics subpanel.
|
||||
|
||||
The statistics panel is nested in the main Atomic Data Manager panel. This
|
||||
panel contains statistics about the Blender file and each data category in
|
||||
it.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from atomic_data_manager.stats import count
|
||||
from atomic_data_manager.stats import misc
|
||||
from atomic_data_manager.ui.utils import ui_layouts
|
||||
|
||||
|
||||
# Atomic Data Manager Statistics SubPanel
|
||||
class ATOMIC_PT_stats_panel(bpy.types.Panel):
|
||||
"""The Atomic Data Manager \"Stats for Nerds\" panel"""
|
||||
bl_idname = "ATOMIC_PT_stats_panel"
|
||||
bl_label = "Stats for Nerds"
|
||||
bl_space_type = "PROPERTIES"
|
||||
bl_region_type = "WINDOW"
|
||||
bl_parent_id = "ATOMIC_PT_main_panel"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
# categories selector / header
|
||||
row = layout.row()
|
||||
row.label(text="Categories:")
|
||||
row.prop(atom, "stats_mode", expand=True, icon_only=True)
|
||||
|
||||
# statistics box
|
||||
box = layout.box()
|
||||
|
||||
# overview statistics
|
||||
if atom.stats_mode == 'OVERVIEW':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Overview", icon='FILE')
|
||||
|
||||
# blender project file size statistic
|
||||
row = box.row()
|
||||
row.label(text="Blend File Size: " + misc.blend_size())
|
||||
|
||||
# cateogry statistics
|
||||
split = box.split()
|
||||
|
||||
# left column
|
||||
col = split.column()
|
||||
|
||||
# left column category labels
|
||||
col.label(text="Collections")
|
||||
col.label(text="Lights")
|
||||
col.label(text="Node Groups")
|
||||
col.label(text="Textures")
|
||||
|
||||
col = split.column()
|
||||
|
||||
# collection count
|
||||
col.label(text=str(count.collections()))
|
||||
|
||||
# light count
|
||||
col.label(text=str(count.lights()))
|
||||
|
||||
# node group count
|
||||
col.label(text=str(count.node_groups()))
|
||||
|
||||
# texture count
|
||||
col.label(text=str(count.textures()))
|
||||
|
||||
# right column
|
||||
col = split.column()
|
||||
|
||||
# right column category labels
|
||||
col.label(text="Images")
|
||||
col.label(text="Materials")
|
||||
col.label(text="Particles")
|
||||
col.label(text="Worlds")
|
||||
|
||||
col = split.column()
|
||||
|
||||
# image count
|
||||
col.label(text=str(count.images()))
|
||||
|
||||
# material count
|
||||
col.label(text=str(count.materials()))
|
||||
|
||||
# particle system count
|
||||
col.label(text=str(count.particles()))
|
||||
|
||||
# world count
|
||||
col.label(text=str(count.worlds()))
|
||||
|
||||
# collection statistics
|
||||
elif atom.stats_mode == 'COLLECTIONS':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Collections", icon='GROUP')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.collections())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.collections_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.collections_unnamed())
|
||||
)
|
||||
|
||||
# image statistics
|
||||
elif atom.stats_mode == 'IMAGES':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Images", icon='IMAGE_DATA')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and missing count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.images())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Missing: {0}".format(count.images_missing())
|
||||
)
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.images_unused())
|
||||
)
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.images_unnamed())
|
||||
)
|
||||
|
||||
# light statistics
|
||||
elif atom.stats_mode == 'LIGHTS':
|
||||
row = box.row()
|
||||
row.label(text="Lights", icon='LIGHT')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.lights())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.lights_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.lights_unnamed())
|
||||
)
|
||||
|
||||
# material statistics
|
||||
elif atom.stats_mode == 'MATERIALS':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Materials", icon='MATERIAL')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.materials())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.materials_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.materials_unnamed())
|
||||
)
|
||||
|
||||
# object statistics
|
||||
elif atom.stats_mode == 'OBJECTS':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Objects", icon='OBJECT_DATA')
|
||||
|
||||
# total count
|
||||
split = box.split()
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.objects())
|
||||
)
|
||||
|
||||
# unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.objects_unnamed())
|
||||
)
|
||||
|
||||
# node group statistics
|
||||
elif atom.stats_mode == 'NODE_GROUPS':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Node Groups", icon='NODETREE')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.node_groups())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.node_groups_unused())
|
||||
)
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.node_groups_unnamed())
|
||||
)
|
||||
|
||||
# particle statistics
|
||||
elif atom.stats_mode == 'PARTICLES':
|
||||
|
||||
# category header label
|
||||
row = box.row()
|
||||
row.label(text="Particle Systems", icon='PARTICLES')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.particles())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.particles_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.particles_unnamed())
|
||||
)
|
||||
|
||||
# texture statistics
|
||||
elif atom.stats_mode == 'TEXTURES':
|
||||
row = box.row()
|
||||
row.label(text="Textures", icon='TEXTURE')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.textures())
|
||||
)
|
||||
|
||||
# col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.textures_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.textures_unnamed())
|
||||
)
|
||||
|
||||
# world statistics
|
||||
elif atom.stats_mode == 'WORLDS':
|
||||
row = box.row()
|
||||
row.label(text="Worlds", icon='WORLD')
|
||||
|
||||
split = box.split()
|
||||
|
||||
# total and placeholder count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Total: {0}".format(count.worlds())
|
||||
)
|
||||
|
||||
# # col.label(text="Placeholder") # TODO: remove placeholder
|
||||
|
||||
# unused and unnamed count
|
||||
col = split.column()
|
||||
|
||||
col.label(
|
||||
text="Unused: {0}".format(count.worlds_unused())
|
||||
)
|
||||
|
||||
col.label(
|
||||
text="Unnamed: {0}".format(count.worlds_unnamed())
|
||||
)
|
||||
|
||||
|
||||
reg_list = [ATOMIC_PT_stats_panel]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
@@ -1,128 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains the user interface and some helper functions for the
|
||||
support Remington Creative popup.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
import time
|
||||
from bpy.utils import register_class
|
||||
from bpy.utils import unregister_class
|
||||
from bpy.app.handlers import persistent
|
||||
from atomic_data_manager import config
|
||||
from atomic_data_manager.ui import preferences_ui
|
||||
|
||||
|
||||
def get_current_day():
|
||||
# returns the current day since the start of the computer clock
|
||||
seconds_per_day = 86400
|
||||
return int(time.time() / seconds_per_day)
|
||||
|
||||
|
||||
def update_enable_show_support_me_popup(self, context):
|
||||
# copy the inverse of the stop show support popup property to Atomic's
|
||||
# enable support me popup preference
|
||||
preferences_ui.set_enable_support_me_popup(
|
||||
not self.stop_showing_support_popup)
|
||||
|
||||
|
||||
@persistent
|
||||
def show_support_me_popup(dummy=None):
|
||||
# shows the support me popup if the 5 day interval has expired and the
|
||||
# enable support me popup preference is enabled
|
||||
|
||||
popup_interval = 5 # days
|
||||
|
||||
current_day = get_current_day()
|
||||
next_day = config.last_popup_day + popup_interval
|
||||
|
||||
if config.enable_support_me_popup and current_day >= next_day:
|
||||
preferences_ui.set_last_popup_day(current_day)
|
||||
bpy.ops.atomic.show_support_me('INVOKE_DEFAULT')
|
||||
|
||||
|
||||
# Atomic Data Manager Support Me Popup Operator
|
||||
class ATOMIC_OT_support_me_popup(bpy.types.Operator):
|
||||
"""Displays the Atomic \"Support Me\" popup"""
|
||||
bl_idname = "atomic.show_support_me"
|
||||
bl_label = "Like Atomic Data Manager?"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
stop_showing_support_popup: bpy.props.BoolProperty(
|
||||
default=False,
|
||||
update=update_enable_show_support_me_popup
|
||||
)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# call to action label
|
||||
col = layout.column(align=True)
|
||||
col.label(
|
||||
text="Consider supporting our free software development!"
|
||||
)
|
||||
|
||||
separator = layout.separator() # extra space
|
||||
|
||||
# never show again toggle
|
||||
row = layout.row()
|
||||
row.prop(
|
||||
self, "stop_showing_support_popup", text="Never Show Again"
|
||||
)
|
||||
|
||||
# support remington creative button
|
||||
row = layout.row()
|
||||
row.scale_y = 2
|
||||
row.operator(
|
||||
"atomic.open_support_me",
|
||||
text="Support Remington Creative",
|
||||
icon="FUND"
|
||||
)
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
wm = context.window_manager
|
||||
return wm.invoke_props_dialog(self)
|
||||
|
||||
|
||||
reg_list = [ATOMIC_OT_support_me_popup]
|
||||
|
||||
|
||||
def register():
|
||||
for cls in reg_list:
|
||||
register_class(cls)
|
||||
|
||||
bpy.app.handlers.load_post.append(show_support_me_popup)
|
||||
|
||||
# reset day counter if it equals zero of if it is in the future
|
||||
if config.last_popup_day == 0 \
|
||||
or config.last_popup_day > get_current_day():
|
||||
preferences_ui.set_last_popup_day(get_current_day())
|
||||
|
||||
|
||||
def unregister():
|
||||
for cls in reg_list:
|
||||
unregister_class(cls)
|
||||
|
||||
bpy.app.handlers.load_post.remove(show_support_me_popup)
|
||||
@@ -1,224 +0,0 @@
|
||||
"""
|
||||
Copyright (C) 2019 Remington Creative
|
||||
|
||||
This file is part of Atomic Data Manager.
|
||||
|
||||
Atomic Data Manager is free software: you can redistribute
|
||||
it and/or modify it under the terms of the GNU General Public License
|
||||
as published by the Free Software Foundation, either version 3 of the
|
||||
License, or (at your option) any later version.
|
||||
|
||||
Atomic Data Manager is distributed in the hope that it will
|
||||
be useful, but WITHOUT ANY WARRANTY; without even the implied warranty
|
||||
of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License along
|
||||
with Atomic Data Manager. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
---
|
||||
|
||||
This file contains basic UI layouts for the Atomic add-on that can be
|
||||
used throughout the interface.
|
||||
|
||||
"""
|
||||
|
||||
import bpy
|
||||
|
||||
|
||||
def box_list(layout, title=None, items=None, columns=2, icon=None):
|
||||
# a title label followed by a box that contains a two column list of
|
||||
# items, each of which is preceded by a uniform icon that does not
|
||||
# change depending on the objects type
|
||||
|
||||
# box list title
|
||||
row = layout.row() # extra row for additional spacing
|
||||
|
||||
if title is not None:
|
||||
row = layout.row()
|
||||
row.label(text=title)
|
||||
|
||||
box = layout.box()
|
||||
|
||||
# if the list has elements
|
||||
if items is not None and len(items) != 0:
|
||||
|
||||
# display the list
|
||||
flow = box.column_flow(columns=columns)
|
||||
for item in items:
|
||||
if icon is not None:
|
||||
flow.label(text=item, icon=icon)
|
||||
else:
|
||||
flow.label(text=item)
|
||||
|
||||
# if the list has no elements
|
||||
else:
|
||||
|
||||
# display the none label
|
||||
row = box.row()
|
||||
row.enabled = False
|
||||
row.label(text="none")
|
||||
|
||||
|
||||
def box_list_diverse(layout, title, items, columns=2):
|
||||
# a title label followed by a box that contains a two column list of
|
||||
# items, each of which is preceded by an icon that changes depending
|
||||
# on the type of object that is being listed
|
||||
|
||||
# box list title
|
||||
row = layout.row() # extra row for additional spacing
|
||||
row = layout.row()
|
||||
row.label(text=title)
|
||||
box = layout.box()
|
||||
|
||||
# if the list has elements
|
||||
if len(items) != 0:
|
||||
|
||||
# display the list
|
||||
flow = box.column_flow(columns=columns)
|
||||
objects = bpy.data.objects
|
||||
for item in items:
|
||||
if objects[item].type == 'ARMATURE':
|
||||
flow.label(text=item, icon="OUTLINER_OB_ARMATURE")
|
||||
|
||||
elif objects[item].type == 'CAMERA':
|
||||
flow.label(text=item, icon="OUTLINER_OB_CAMERA")
|
||||
|
||||
elif objects[item].type == 'CURVE':
|
||||
flow.label(text=item, icon="OUTLINER_OB_CURVE")
|
||||
|
||||
elif objects[item].type == 'EMPTY':
|
||||
flow.label(text=item, icon="OUTLINER_OB_EMPTY")
|
||||
|
||||
elif objects[item].type == 'FONT':
|
||||
flow.label(text=item, icon="OUTLINER_OB_FONT")
|
||||
|
||||
elif objects[item].type == 'GPENCIL':
|
||||
flow.label(text=item, icon="OUTLINER_OB_GREASEPENCIL")
|
||||
|
||||
elif objects[item].type == 'LATTICE':
|
||||
flow.label(text=item, icon="OUTLINER_OB_LATTICE")
|
||||
|
||||
elif objects[item].type == 'LIGHT':
|
||||
flow.label(text=item, icon="OUTLINER_OB_LIGHT")
|
||||
|
||||
elif objects[item].type == 'LIGHT_PROBE':
|
||||
flow.label(text=item, icon="OUTLINER_OB_LIGHTPROBE")
|
||||
|
||||
elif objects[item].type == 'MESH':
|
||||
flow.label(text=item, icon="OUTLINER_OB_MESH")
|
||||
|
||||
elif objects[item].type == 'META':
|
||||
flow.label(text=item, icon="OUTLINER_OB_META")
|
||||
|
||||
elif objects[item].type == 'SPEAKER':
|
||||
flow.label(text=item, icon="OUTLINER_OB_SPEAKER")
|
||||
|
||||
elif objects[item].type == 'SURFACE':
|
||||
flow.label(text=item, icon="OUTLINER_OB_SURFACE")
|
||||
|
||||
# if the object doesn't fit any of the previous types
|
||||
else:
|
||||
flow.label(text=item, icon="QUESTION")
|
||||
|
||||
# if the list has no elements
|
||||
else:
|
||||
|
||||
# display the none label
|
||||
row = box.row()
|
||||
row.enabled = False
|
||||
row.label(text="none")
|
||||
|
||||
|
||||
def inspect_header(layout, atom_prop, data):
|
||||
# a single column containing a search property and basic data
|
||||
# manipulation functions that appears at the top of all inspect data
|
||||
# set dialogs
|
||||
|
||||
atom = bpy.context.scene.atomic
|
||||
|
||||
# exterior box and prop search for data-blocks
|
||||
col = layout.column(align=True)
|
||||
box = col.box()
|
||||
row = box.row()
|
||||
split = row.split()
|
||||
split.prop_search(atom, atom_prop, bpy.data, data, text="")
|
||||
|
||||
# convert the data set string into an actual data set reference
|
||||
data = getattr(bpy.data, data)
|
||||
|
||||
# get the string value of the string property
|
||||
text_field = getattr(atom, atom_prop)
|
||||
|
||||
# determine whether or not the text entered in the string property
|
||||
# is a valid key
|
||||
is_valid_key = text_field in data.keys()
|
||||
|
||||
# determine whether or not the piece of data is using a fake user
|
||||
has_fake_user = is_valid_key and data[text_field].use_fake_user
|
||||
|
||||
# buttons that follow the prop search
|
||||
split = row.split()
|
||||
row = split.row(align=True)
|
||||
|
||||
# disable the buttons if the key in the search property is invalid
|
||||
row.enabled = is_valid_key
|
||||
|
||||
# toggle fake user button (do not show for collections)
|
||||
# icon and depression changes depending on whether or not the object
|
||||
# is using a fake user
|
||||
if data != bpy.data.collections:
|
||||
|
||||
# has fake user
|
||||
if has_fake_user:
|
||||
row.operator(
|
||||
"atomic.toggle_fake_user",
|
||||
text="",
|
||||
icon="FAKE_USER_ON",
|
||||
depress=True
|
||||
)
|
||||
|
||||
# does not have fake user
|
||||
else:
|
||||
row.operator(
|
||||
"atomic.toggle_fake_user",
|
||||
text="",
|
||||
icon="FAKE_USER_OFF",
|
||||
depress=False
|
||||
)
|
||||
|
||||
# duplicate button
|
||||
row.operator(
|
||||
"atomic.inspection_duplicate",
|
||||
text="",
|
||||
icon="DUPLICATE"
|
||||
)
|
||||
|
||||
# replace button (do not show for collections)
|
||||
if data != bpy.data.collections:
|
||||
row.operator(
|
||||
"atomic.replace",
|
||||
text="",
|
||||
icon="UV_SYNC_SELECT"
|
||||
)
|
||||
|
||||
# rename button
|
||||
row.operator(
|
||||
"atomic.rename",
|
||||
text="",
|
||||
icon="GREASEPENCIL"
|
||||
)
|
||||
|
||||
# delete button
|
||||
row.operator(
|
||||
"atomic.inspection_delete",
|
||||
text="",
|
||||
icon="TRASH"
|
||||
)
|
||||
|
||||
|
||||
def number_suffix(text, number):
|
||||
# returns the text properly formatted as a suffix
|
||||
# e.g. passing in "hello" and "100" will result in "hello (100)"
|
||||
|
||||
return text + " ({0})".format(number) if int(number) != 0 else text
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
-9
@@ -1,9 +0,0 @@
|
||||
{
|
||||
"last_check": "2025-03-04 11:17:59.498811",
|
||||
"backup_date": "",
|
||||
"update_ready": false,
|
||||
"ignore": false,
|
||||
"just_restored": false,
|
||||
"just_updated": false,
|
||||
"version_text": {}
|
||||
}
|
||||
@@ -1,199 +0,0 @@
|
||||
bl_info = {
|
||||
"name": "Raincloud's Bulk Scene Tools",
|
||||
"author": "RaincloudTheDragon",
|
||||
"version": (0, 9, 1),
|
||||
"blender": (4, 5, 0),
|
||||
"location": "View3D > Sidebar > Edit Tab",
|
||||
"description": "Tools for bulk operations on scene data",
|
||||
"warning": "",
|
||||
"doc_url": "https://github.com/RaincloudTheDragon/Rainys-Bulk-Scene-Tools",
|
||||
"category": "Scene",
|
||||
"maintainer": "RaincloudTheDragon",
|
||||
"support": "COMMUNITY",
|
||||
}
|
||||
|
||||
import bpy # type: ignore
|
||||
from bpy.types import AddonPreferences, Operator, Panel # type: ignore
|
||||
from bpy.props import BoolProperty, IntProperty # type: ignore
|
||||
from .panels import bulk_viewport_display
|
||||
from .panels import bulk_data_remap
|
||||
from .panels import bulk_path_management
|
||||
from .panels import bulk_scene_general
|
||||
from .ops.AutoMatExtractor import AutoMatExtractor, AUTOMAT_OT_summary_dialog
|
||||
from .ops.Rename_images_by_mat import Rename_images_by_mat, RENAME_OT_summary_dialog
|
||||
from .ops.FreeGPU import BST_FreeGPU
|
||||
from .ops import ghost_buster
|
||||
from . import updater
|
||||
|
||||
# Addon preferences class for update settings
|
||||
class BST_AddonPreferences(AddonPreferences):
|
||||
bl_idname = __package__
|
||||
|
||||
# Auto Updater settings
|
||||
check_for_updates: BoolProperty(
|
||||
name="Check for Updates on Startup",
|
||||
description="Automatically check for new versions of the addon when Blender starts",
|
||||
default=True,
|
||||
)
|
||||
|
||||
update_check_interval: IntProperty( # type: ignore
|
||||
name="Update check interval (hours)",
|
||||
description="How often to check for updates (in hours)",
|
||||
default=24,
|
||||
min=1,
|
||||
max=168 # 1 week max
|
||||
)
|
||||
|
||||
# AutoMat Extractor settings
|
||||
automat_common_outside_blend: BoolProperty(
|
||||
name="Place 'common' folder outside 'blend' folder",
|
||||
description="If enabled, the 'common' folder for shared textures will be placed directly in 'textures/'. If disabled, it will be placed inside 'textures/<blend_name>/'",
|
||||
default=False,
|
||||
)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Custom updater UI
|
||||
box = layout.box()
|
||||
box.label(text="Update Settings")
|
||||
row = box.row()
|
||||
row.prop(self, "check_for_updates")
|
||||
row = box.row()
|
||||
row.prop(self, "update_check_interval")
|
||||
|
||||
# Check for updates button
|
||||
row = box.row()
|
||||
row.operator("bst.check_for_updates", icon='FILE_REFRESH')
|
||||
|
||||
# Show update status if available
|
||||
if updater.UpdaterState.update_available:
|
||||
box.label(text=f"Update available: v{updater.UpdaterState.update_version}")
|
||||
row = box.row()
|
||||
row.operator("bst.install_update", icon='IMPORT')
|
||||
row = box.row()
|
||||
row.operator("wm.url_open", text="Download Update").url = updater.UpdaterState.update_download_url
|
||||
elif updater.UpdaterState.checking_for_updates:
|
||||
box.label(text="Checking for updates...")
|
||||
elif updater.UpdaterState.error_message:
|
||||
box.label(text=f"Error checking for updates: {updater.UpdaterState.error_message}")
|
||||
|
||||
# AutoMat Extractor settings
|
||||
box = layout.box()
|
||||
box.label(text="AutoMat Extractor Settings")
|
||||
row = box.row()
|
||||
row.prop(self, "automat_common_outside_blend")
|
||||
|
||||
# Main panel for Bulk Scene Tools
|
||||
class VIEW3D_PT_BulkSceneTools(Panel):
|
||||
"""Bulk Scene Tools Panel"""
|
||||
bl_label = "Bulk Scene Tools"
|
||||
bl_idname = "VIEW3D_PT_bulk_scene_tools"
|
||||
bl_space_type = 'VIEW_3D'
|
||||
bl_region_type = 'UI'
|
||||
bl_category = 'Edit'
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
layout.label(text="Tools for bulk operations on scene data")
|
||||
|
||||
# List of all classes in this module
|
||||
classes = (
|
||||
VIEW3D_PT_BulkSceneTools,
|
||||
BST_AddonPreferences,
|
||||
AutoMatExtractor,
|
||||
AUTOMAT_OT_summary_dialog,
|
||||
Rename_images_by_mat,
|
||||
RENAME_OT_summary_dialog,
|
||||
BST_FreeGPU,
|
||||
)
|
||||
|
||||
def register():
|
||||
# Register classes from this module (do this first to ensure preferences are available)
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
|
||||
# Print debug info about preferences
|
||||
try:
|
||||
prefs = bpy.context.preferences.addons.get(__package__)
|
||||
if prefs:
|
||||
print(f"Addon preferences registered successfully: {prefs}")
|
||||
else:
|
||||
print("WARNING: Addon preferences not found after registration!")
|
||||
print(f"Available addons: {', '.join(bpy.context.preferences.addons.keys())}")
|
||||
except Exception as e:
|
||||
print(f"Error accessing preferences: {str(e)}")
|
||||
|
||||
# Register the updater module
|
||||
updater.register()
|
||||
|
||||
# Check for updates on startup
|
||||
if hasattr(updater, "check_for_updates"):
|
||||
updater.check_for_updates()
|
||||
|
||||
# Register modules
|
||||
bulk_scene_general.register()
|
||||
bulk_viewport_display.register()
|
||||
bulk_data_remap.register()
|
||||
bulk_path_management.register()
|
||||
ghost_buster.register()
|
||||
|
||||
# Add keybind for Free GPU (global context)
|
||||
wm = bpy.context.window_manager
|
||||
kc = wm.keyconfigs.addon
|
||||
if kc:
|
||||
# Use Screen keymap for global shortcuts that work everywhere
|
||||
km = kc.keymaps.new(name='Screen', space_type='EMPTY')
|
||||
kmi = km.keymap_items.new('bst.free_gpu', 'M', 'PRESS', ctrl=True, alt=True, shift=True)
|
||||
# Store keymap for cleanup
|
||||
addon_keymaps = getattr(bpy.types.Scene, '_bst_keymaps', [])
|
||||
addon_keymaps.append((km, kmi))
|
||||
bpy.types.Scene._bst_keymaps = addon_keymaps
|
||||
|
||||
def unregister():
|
||||
# Remove keybinds
|
||||
addon_keymaps = getattr(bpy.types.Scene, '_bst_keymaps', [])
|
||||
for km, kmi in addon_keymaps:
|
||||
try:
|
||||
km.keymap_items.remove(kmi)
|
||||
except:
|
||||
pass
|
||||
addon_keymaps.clear()
|
||||
if hasattr(bpy.types.Scene, '_bst_keymaps'):
|
||||
delattr(bpy.types.Scene, '_bst_keymaps')
|
||||
|
||||
# Unregister modules
|
||||
try:
|
||||
ghost_buster.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
bulk_path_management.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
bulk_data_remap.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
bulk_viewport_display.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
bulk_scene_general.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
# Unregister the updater module
|
||||
try:
|
||||
updater.unregister()
|
||||
except Exception:
|
||||
pass
|
||||
# Unregister classes from this module
|
||||
for cls in reversed(classes):
|
||||
try:
|
||||
bpy.utils.unregister_class(cls)
|
||||
except RuntimeError:
|
||||
pass
|
||||
|
||||
if __name__ == "__main__":
|
||||
register()
|
||||
@@ -1,13 +0,0 @@
|
||||
{
|
||||
"name": "Raincloud's Bulk Scene Tools",
|
||||
"author": "RaincloudTheDragon",
|
||||
"version": [0, 10, 0],
|
||||
"blender": [4, 5, 0],
|
||||
"location": "View3D > Sidebar > Edit Tab",
|
||||
"description": "Tools for bulk operations on scene data",
|
||||
"category": "Scene",
|
||||
"maintainer": "RaincloudTheDragon",
|
||||
"support": "COMMUNITY",
|
||||
"doc_url": "https://github.com/RaincloudTheDragon/Rainys-Bulk-Scene-Tools",
|
||||
"tracker_url": ""
|
||||
}
|
||||
@@ -1,147 +0,0 @@
|
||||
# v 0.10.0
|
||||
- **AutoMat Extractor**
|
||||
- Added UDIM/tiled image detection so multi-tile textures are organized alongside standard images without errors. #8
|
||||
- Path builder now emits UDIM filename templates (e.g., `name.[UDIM].png`) plus per-tile targets (e.g., `name.1001.png`), preventing collisions during relocation.
|
||||
- Remapping helper sets tile-level `filepath` values and ensures directories exist before saving.
|
||||
- Saving routine attempts whole-image writes first, then falls back to per-tile saves via the Image Editor context, with summary logs noting UDIM sets processed.
|
||||
- **Viewport Colors**
|
||||
- Added a Refresh Material Previews button that clears thumbnails, assigns each material to a temporary preview mesh, and forces `preview_ensure()` so stubborn viewport colors now reliably pick up thumbnail data. #7
|
||||
|
||||
# v 0.9.1
|
||||
- **Convert Relations to Constraint**
|
||||
- Bugfix: Now converts bone parenting as intended
|
||||
|
||||
# v 0.9.0
|
||||
- **Convert Relations to Constraint**: Operator in Animation Data section that converts regular parenting relationships to Child Of constraints for selected objects, maintaining world position and transform hierarchy
|
||||
- Bugfix: Adapted old operator that wasn't drawing due to using the wrong icon string name.
|
||||
|
||||
# v 0.8.1
|
||||
- Delete Single Keyframe Actions: fixed bug caused by not ignoring linked files
|
||||
|
||||
# v 0.8.0
|
||||
|
||||
## New Features
|
||||
- **Delete Single Keyframe Actions**: New operator to remove unwanted animation actions (no keyframes, single keyframe, or all keyframes on same frame)
|
||||
- **Find Material Users**: New operator with native material selector interface that displays detailed material usage analysis in a popup dialog, showing:
|
||||
- Object users with material slots
|
||||
- Node tree references
|
||||
- Material node tree usage
|
||||
- Blender's internal user count and fake user status
|
||||
- **Remove Unused Material Slots**: New operator to clean up unused material slots from all mesh objects in the scene
|
||||
- **Enhanced Bulk Scene General Panel**: Reorganized panel with new sections:
|
||||
- Materials section containing material analysis and cleanup tools
|
||||
- Animation Data section for keyframe/action management
|
||||
- All new operators integrated with consistent UI and project formatting standards
|
||||
|
||||
## Fixes
|
||||
- PathMan
|
||||
- Automat summary no longer gives invoke error
|
||||
- Fixed timing/cancellation error when cancelling Rename Flat Colors operation
|
||||
- Pack files operator no longer throws AttributeError for is_generated (now uses img.source != 'GENERATED')
|
||||
- Pack files operator now properly skips special Blender images like "Render Result" and "Viewer Node" that can't be packed
|
||||
- General
|
||||
- Removed debug print statement that was showing "Subdivision Surface modifiers removed from all objects" on every addon load
|
||||
|
||||
# v 0.7.1
|
||||
|
||||
## Ghost Buster Enhancements
|
||||
|
||||
### Added
|
||||
- **Low Priority Ghost Detection**: New option to delete objects not in scenes with no legitimate use and users < 2
|
||||
- **Smart Instance Collection Detection**: Ghost Buster now properly detects when objects are used by instance collections in scenes
|
||||
- **Enhanced Legitimacy Checks**: Improved detection of objects with valid uses outside scenes (constraints, modifiers, particle systems only count if the using object is in a scene)
|
||||
|
||||
### Improved
|
||||
- **More Accurate Ghost Detection**: Eliminated false positives by checking if instance collection targets are actually being used by scene objects
|
||||
- **Better Classification**: Objects are now classified as "Legitimate", "Ghosts (users >= 2)", or "Low Priority (users < 2)" with clearer reasoning
|
||||
- Cleaned UI
|
||||
|
||||
### Technical Changes
|
||||
- Added `is_object_used_by_scene_instance_collections()` function for precise instance collection detection
|
||||
- Enhanced `is_object_legitimate_outside_scene()` with scene-aware checks for modifiers, constraints, and particle systems
|
||||
- Updated ghost analysis and removal logic to use more precise categorization
|
||||
- Added scene property `ghost_buster_delete_low_priority` for user preference storage
|
||||
|
||||
# v 0.7.0
|
||||
|
||||
## New: Ghost Detection System
|
||||
- **Universal Object Analysis**: Expanded ghost detection from CC-objects only to all object types (meshes, empties, curves, etc.)
|
||||
- **Enhanced Safety Framework**: Added comprehensive protection for legitimate objects outside scenes:
|
||||
- WGT rig widgets (`WGT-*` objects)
|
||||
- Modifier targets (curve modifiers, constraints)
|
||||
- Constraint targets and references
|
||||
- Particle system objects
|
||||
- Collection instance objects (linked collection references)
|
||||
- **Smart Classification**: Objects not in scenes now categorized as:
|
||||
- `LEGITIMATE`: Has valid use outside scenes (protected)
|
||||
- `LOW PRIORITY`: Only collection reference (preserved)
|
||||
- `GHOST`: Multiple users but not in scenes (removed)
|
||||
- **Conservative Cleanup Logic**: Only removes objects with 2+ users that have no legitimate purpose
|
||||
- **Updated UI**: Ghost Detector popup now shows "Ghost Objects Analysis" with enhanced categorization and object type details
|
||||
- **Improved Safety**: All linked/library content automatically protected from ghost detection
|
||||
|
||||
# v 0.6.1
|
||||
|
||||
## Bug Fixes
|
||||
- **Fixed flat color detection**: Redesigned algorithm with exact pixel matching and smart sampling
|
||||
- **Fixed AutoMat Extractor**: Now properly organizes images by material instead of dumping everything to common folder
|
||||
- **Fixed viewport color setting**: Resolved context restriction errors with deferred color application
|
||||
- **Fixed timer performance**: Reduced timer frequency and improved cancellation reliability
|
||||
- **Enhanced debugging**: Added comprehensive console reporting for all bulk operations
|
||||
|
||||
## Improvements
|
||||
- Better performance with optimized sampling
|
||||
- More reliable cancellation system
|
||||
- Context-safe operations that don't interfere with Blender's drawing state
|
||||
|
||||
# v 0.6.0
|
||||
|
||||
- **Enhancement: Progress Reporting & Cancellation**
|
||||
- Some of the PathMan's operators are pretty resource-intense. Due to Python's GIL, I haven't been able to figure out how to run some of these more efficiently. Without the console window, you're flying blind, so I've integrated a loading bar with progress reporting for the following operators:
|
||||
- Flat Color Texture Renamer
|
||||
- Remove Extensions
|
||||
- Save All to image Paths
|
||||
- Remap Selected
|
||||
- Rename by Material
|
||||
- AutoMat Extractor
|
||||
|
||||
# v 0.5.1
|
||||
|
||||
- **Enhanced AutoMat Extractor:**
|
||||
- Added a crucial safety check to prevent textures from overwriting each other if they resolve to the same filename (e.g., `Image.001.png` and `Image.002.png` both becoming `Image.png`).
|
||||
- The operator now correctly sanitizes names with numerical suffixes before saving.
|
||||
- A new summary dialog now appears after the operation, reporting how many files were extracted successfully and listing any files that were skipped due to naming conflicts.
|
||||
- Added a user preference to control the location of the `common` folder, allowing it to be placed either inside or outside the blend file's specific texture folder. A checkbox for this setting was added to the UI.
|
||||
- **Improved Suffix Handling:**
|
||||
- The "Rename by Material" tool now correctly preserves spaces in packed texture names (e.g., `Flow Pack` instead of `FlowPack`).
|
||||
- Added support for underscore-separated packed texture names (e.g., `flow_pack`).
|
||||
- **Bug Fixes:**
|
||||
- Resolved multiple `AttributeError` and `TypeError` exceptions that occurred due to incorrect addon name lookups and invalid icon names, making the UI and addon registration more robust.
|
||||
|
||||
# v 0.5.0
|
||||
|
||||
- **Integrated Scene General: Free GPU VRAM**
|
||||
- **Integrated PathMan: Automatic Material Extractor**
|
||||
- **Integrated PathMan: Rename Image Textures by Material**: Added comprehensive texture suffix recognition
|
||||
- Recognizes many Character Creator suffixes
|
||||
- Recognizes most standard material suffixes
|
||||
- Images with unrecognized suffixes are skipped instead of renamed, preventing unintended modifications
|
||||
- Enhanced logging: Unrecognized suffix images are listed separately for easy identification
|
||||
- **UI Improvements**:
|
||||
- Rearranged workflow layout: Make Paths Relative/Absolute moved to main workflow section
|
||||
- Remap Selected moved under path preview for better workflow progression
|
||||
- Rename by Material and AutoMat Extractor repositioned after Remap Selected
|
||||
- Added Autopack toggle at beginning of workflow sections (both Node Editor and 3D Viewport)
|
||||
- Consolidated draw functions: Node Editor panel now serves as master template for both panels
|
||||
|
||||
# v 0.4.1
|
||||
|
||||
- Fixed traceback error causing remap to fail to draw buttons
|
||||
|
||||
# v 0.4.0
|
||||
|
||||
Overhaul! Added new Scene General panel, major enhancements to all panels and functions.
|
||||
|
||||
# v0.3.0
|
||||
|
||||
- Added image path remapping for unpacked images, keeping them organized.
|
||||
@@ -1,540 +0,0 @@
|
||||
import bpy
|
||||
import os
|
||||
import re
|
||||
from ..panels.bulk_path_management import (
|
||||
get_image_extension,
|
||||
bulk_remap_paths,
|
||||
set_image_paths,
|
||||
ensure_directory_for_path,
|
||||
)
|
||||
|
||||
class AUTOMAT_OT_summary_dialog(bpy.types.Operator):
|
||||
"""Show AutoMat Extractor operation summary"""
|
||||
bl_idname = "bst.automat_summary_dialog"
|
||||
bl_label = "AutoMat Extractor Summary"
|
||||
bl_options = {'REGISTER', 'INTERNAL'}
|
||||
|
||||
# Properties to store summary data
|
||||
total_selected: bpy.props.IntProperty(default=0)
|
||||
success_count: bpy.props.IntProperty(default=0)
|
||||
overwrite_skipped_count: bpy.props.IntProperty(default=0)
|
||||
failed_remap_count: bpy.props.IntProperty(default=0)
|
||||
|
||||
overwrite_details: bpy.props.StringProperty(default="")
|
||||
failed_remap_details: bpy.props.StringProperty(default="")
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
layout.label(text="AutoMat Extractor - Summary", icon='INFO')
|
||||
layout.separator()
|
||||
|
||||
box = layout.box()
|
||||
col = box.column(align=True)
|
||||
col.label(text=f"Total selected images: {self.total_selected}")
|
||||
col.label(text=f"Successfully extracted: {self.success_count}", icon='CHECKMARK')
|
||||
|
||||
if self.overwrite_skipped_count > 0:
|
||||
col.label(text=f"Skipped to prevent overwrite: {self.overwrite_skipped_count}", icon='ERROR')
|
||||
if self.failed_remap_count > 0:
|
||||
col.label(text=f"Failed to remap (path issue): {self.failed_remap_count}", icon='ERROR')
|
||||
|
||||
if self.overwrite_details:
|
||||
layout.separator()
|
||||
box = layout.box()
|
||||
box.label(text="Overwrite Conflicts (Skipped):", icon='FILE_TEXT')
|
||||
for line in self.overwrite_details.split('\n'):
|
||||
if line.strip():
|
||||
box.label(text=line)
|
||||
|
||||
if self.failed_remap_details:
|
||||
layout.separator()
|
||||
box = layout.box()
|
||||
box.label(text="Failed Remaps:", icon='FILE_TEXT')
|
||||
for line in self.failed_remap_details.split('\n'):
|
||||
if line.strip():
|
||||
box.label(text=line)
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
return context.window_manager.invoke_popup(self, width=500)
|
||||
|
||||
class AutoMatExtractor(bpy.types.Operator):
|
||||
bl_idname = "bst.automatextractor"
|
||||
bl_label = "AutoMatExtractor"
|
||||
bl_description = "Pack selected images and extract them with organized paths by blend file and material"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
# Get addon preferences
|
||||
addon_name = __package__.split('.')[0]
|
||||
prefs = context.preferences.addons.get(addon_name).preferences
|
||||
common_outside = prefs.automat_common_outside_blend
|
||||
|
||||
# Get selected images
|
||||
selected_images = [img for img in bpy.data.images if hasattr(img, "bst_selected") and img.bst_selected]
|
||||
|
||||
if not selected_images:
|
||||
self.report({'WARNING'}, "No images selected for extraction")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# Set up progress tracking
|
||||
props = context.scene.bst_path_props
|
||||
props.is_operation_running = True
|
||||
props.operation_progress = 0.0
|
||||
props.operation_status = f"Preparing AutoMat extraction for {len(selected_images)} images..."
|
||||
|
||||
# Store data for timer processing
|
||||
self.selected_images = selected_images
|
||||
self.common_outside = common_outside
|
||||
self.current_step = 0
|
||||
self.current_index = 0
|
||||
self.packed_count = 0
|
||||
self.success_count = 0
|
||||
self.overwrite_skipped = []
|
||||
self.failed_list = []
|
||||
self.path_mapping = {}
|
||||
self.udim_summary = {
|
||||
"found": 0,
|
||||
"saved": 0,
|
||||
}
|
||||
|
||||
# Start timer for processing
|
||||
bpy.app.timers.register(self._process_step)
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def _process_step(self):
|
||||
"""Process AutoMat extraction in steps to avoid blocking the UI"""
|
||||
props = bpy.context.scene.bst_path_props
|
||||
|
||||
# Check for cancellation
|
||||
if props.cancel_operation:
|
||||
props.is_operation_running = False
|
||||
props.operation_progress = 0.0
|
||||
props.operation_status = "Operation cancelled"
|
||||
props.cancel_operation = False
|
||||
return None
|
||||
|
||||
if self.current_step == 0:
|
||||
# Step 1: Pack images
|
||||
if self.current_index >= len(self.selected_images):
|
||||
# Packing complete, move to next step
|
||||
self.current_step = 1
|
||||
self.current_index = 0
|
||||
props.operation_status = "Removing extensions from image names..."
|
||||
props.operation_progress = 25.0
|
||||
return 0.01
|
||||
|
||||
# Pack current image
|
||||
img = self.selected_images[self.current_index]
|
||||
props.operation_status = f"Packing {img.name}..."
|
||||
|
||||
if not img.packed_file:
|
||||
try:
|
||||
img.pack()
|
||||
self.packed_count += 1
|
||||
except Exception as e:
|
||||
# Continue even if packing fails
|
||||
pass
|
||||
|
||||
self.current_index += 1
|
||||
progress = (self.current_index / len(self.selected_images)) * 25.0
|
||||
props.operation_progress = progress
|
||||
|
||||
elif self.current_step == 1:
|
||||
# Step 2: Remove extensions (this is a quick operation)
|
||||
try:
|
||||
bpy.ops.bst.remove_extensions()
|
||||
except Exception as e:
|
||||
pass # Continue even if this fails
|
||||
|
||||
self.current_step = 2
|
||||
self.current_index = 0
|
||||
props.operation_status = "Analyzing material usage..."
|
||||
props.operation_progress = 30.0
|
||||
|
||||
elif self.current_step == 2:
|
||||
# Step 3: Organize images by material usage
|
||||
if self.current_index >= len(self.selected_images):
|
||||
# Analysis complete, move to path building
|
||||
self.current_step = 3
|
||||
self.current_index = 0
|
||||
props.operation_status = "Building path mapping..."
|
||||
props.operation_progress = 50.0
|
||||
return 0.01
|
||||
|
||||
# Get material mapping for all selected images
|
||||
if self.current_index == 0:
|
||||
self.material_mapping = self.get_image_material_mapping(self.selected_images)
|
||||
print(f"DEBUG: Material mapping created for {len(self.selected_images)} images")
|
||||
|
||||
# This step is quick, just mark progress
|
||||
self.current_index += 1
|
||||
progress = 30.0 + (self.current_index / len(self.selected_images)) * 20.0
|
||||
props.operation_progress = progress
|
||||
|
||||
elif self.current_step == 3:
|
||||
# Step 4: Build path mapping
|
||||
if self.current_index >= len(self.selected_images):
|
||||
# Path building complete, move to remapping
|
||||
self.current_step = 4
|
||||
self.current_index = 0
|
||||
props.operation_status = "Remapping image paths..."
|
||||
props.operation_progress = 70.0
|
||||
return 0.01
|
||||
|
||||
# Build path for current image
|
||||
img = self.selected_images[self.current_index]
|
||||
props.operation_status = f"Building path for {img.name}..."
|
||||
|
||||
# Get blend file name
|
||||
blend_name = bpy.path.basename(bpy.data.filepath)
|
||||
if blend_name:
|
||||
blend_name = os.path.splitext(blend_name)[0]
|
||||
else:
|
||||
blend_name = "untitled"
|
||||
blend_name = self.sanitize_filename(blend_name)
|
||||
|
||||
# Determine common path
|
||||
if self.common_outside:
|
||||
common_path_part = "common"
|
||||
else:
|
||||
common_path_part = f"{blend_name}\\common"
|
||||
|
||||
# Get extension and build path
|
||||
extension = get_image_extension(img)
|
||||
sanitized_base_name = self.sanitize_filename(img.name)
|
||||
filename = f"{sanitized_base_name}{extension}"
|
||||
|
||||
if img.name.startswith('#'):
|
||||
# Flat colors go to FlatColors subfolder
|
||||
base_folder = f"//textures\\{common_path_part}\\FlatColors"
|
||||
else:
|
||||
# Check material usage for this image
|
||||
materials_using_image = self.material_mapping.get(img.name, [])
|
||||
|
||||
if not materials_using_image:
|
||||
# No materials found, put in common folder
|
||||
base_folder = f"//textures\\{common_path_part}"
|
||||
print(f"DEBUG: {img.name} - No materials found, using common folder")
|
||||
elif len(materials_using_image) == 1:
|
||||
# Used by exactly one material, organize by material name
|
||||
material_name = self.sanitize_filename(materials_using_image[0])
|
||||
base_folder = f"//textures\\{blend_name}\\{material_name}"
|
||||
print(f"DEBUG: {img.name} - Used by {material_name}, organizing by material")
|
||||
else:
|
||||
# Used by multiple materials, put in common folder
|
||||
base_folder = f"//textures\\{common_path_part}"
|
||||
print(f"DEBUG: {img.name} - Used by multiple materials: {materials_using_image}, using common folder")
|
||||
|
||||
is_udim = self.is_udim_image(img)
|
||||
if is_udim:
|
||||
udim_mapping = self.build_udim_mapping(base_folder, sanitized_base_name, extension, img)
|
||||
self.path_mapping[img.name] = udim_mapping
|
||||
self.udim_summary["found"] += 1
|
||||
print(f"DEBUG: {img.name} - UDIM detected with {len(udim_mapping.get('tiles', {}))} tiles")
|
||||
else:
|
||||
path = f"{base_folder}\\{filename}"
|
||||
self.path_mapping[img.name] = path
|
||||
|
||||
self.current_index += 1
|
||||
progress = 50.0 + (self.current_index / len(self.selected_images)) * 20.0
|
||||
props.operation_progress = progress
|
||||
|
||||
elif self.current_step == 4:
|
||||
# Step 5: Remap paths
|
||||
if self.current_index >= len(self.path_mapping):
|
||||
# Remapping complete, move to saving
|
||||
self.current_step = 5
|
||||
self.current_index = 0
|
||||
props.operation_status = "Saving images to new locations..."
|
||||
props.operation_progress = 85.0
|
||||
return 0.01
|
||||
|
||||
# Remap current image
|
||||
img_name = list(self.path_mapping.keys())[self.current_index]
|
||||
mapping_entry = self.path_mapping[img_name]
|
||||
props.operation_status = f"Remapping {img_name}..."
|
||||
|
||||
if isinstance(mapping_entry, dict) and mapping_entry.get("udim"):
|
||||
success = set_image_paths(
|
||||
img_name,
|
||||
mapping_entry.get("template", ""),
|
||||
tile_paths=mapping_entry.get("tiles", {})
|
||||
)
|
||||
else:
|
||||
success = set_image_paths(img_name, mapping_entry)
|
||||
if success:
|
||||
self.success_count += 1
|
||||
else:
|
||||
self.failed_list.append(img_name)
|
||||
|
||||
self.current_index += 1
|
||||
progress = 70.0 + (self.current_index / len(self.path_mapping)) * 15.0
|
||||
props.operation_progress = progress
|
||||
|
||||
elif self.current_step == 5:
|
||||
# Step 6: Save images
|
||||
if self.current_index >= len(self.selected_images):
|
||||
# Operation complete
|
||||
props.is_operation_running = False
|
||||
props.operation_progress = 100.0
|
||||
props.operation_status = f"Completed! Extracted {self.success_count} images{f', {len(self.failed_list)} failed' if self.failed_list else ''}"
|
||||
|
||||
# Show summary dialog
|
||||
self.show_summary_dialog(
|
||||
bpy.context,
|
||||
total_selected=len(self.selected_images),
|
||||
success_count=self.success_count,
|
||||
overwrite_skipped_list=self.overwrite_skipped,
|
||||
failed_remap_list=self.failed_list
|
||||
)
|
||||
|
||||
# Console summary
|
||||
print(f"\n=== AUTOMAT EXTRACTION SUMMARY ===")
|
||||
print(f"Total images processed: {len(self.selected_images)}")
|
||||
print(f"Successfully extracted: {self.success_count}")
|
||||
print(f"Failed to remap: {len(self.failed_list)}")
|
||||
|
||||
# Show organization breakdown
|
||||
material_organized = 0
|
||||
common_organized = 0
|
||||
flat_colors = 0
|
||||
|
||||
for img_name, path in self.path_mapping.items():
|
||||
current_path = path["template"] if isinstance(path, dict) else path
|
||||
if "FlatColors" in current_path:
|
||||
flat_colors += 1
|
||||
elif "common" in current_path:
|
||||
common_organized += 1
|
||||
else:
|
||||
material_organized += 1
|
||||
|
||||
print(f"\nOrganization breakdown:")
|
||||
print(f" Material-specific folders: {material_organized}")
|
||||
print(f" Common folder: {common_organized}")
|
||||
print(f" Flat colors: {flat_colors}")
|
||||
|
||||
# Show material organization details
|
||||
if material_organized > 0:
|
||||
print(f"\nMaterial organization details:")
|
||||
material_folders = {}
|
||||
for img_name, path in self.path_mapping.items():
|
||||
if "FlatColors" not in path and "common" not in path:
|
||||
# Extract material name from path
|
||||
if isinstance(path, dict):
|
||||
continue
|
||||
path_parts = path.split('\\')
|
||||
if len(path_parts) >= 3:
|
||||
material_name = path_parts[-2]
|
||||
if material_name not in material_folders:
|
||||
material_folders[material_name] = []
|
||||
material_folders[material_name].append(img_name)
|
||||
|
||||
for material_name, images in material_folders.items():
|
||||
print(f" {material_name}: {len(images)} images")
|
||||
|
||||
print(f"=====================================\n")
|
||||
if self.udim_summary["found"]:
|
||||
print(f"UDIM images processed: {self.udim_summary['found']} (saved successfully: {self.udim_summary['saved']})")
|
||||
|
||||
# Force UI update
|
||||
for area in bpy.context.screen.areas:
|
||||
area.tag_redraw()
|
||||
|
||||
return None
|
||||
|
||||
# Save current image
|
||||
img = self.selected_images[self.current_index]
|
||||
props.operation_status = f"Saving {img.name}..."
|
||||
|
||||
mapping_entry = self.path_mapping.get(img.name)
|
||||
if isinstance(mapping_entry, dict) and mapping_entry.get("udim"):
|
||||
self.save_udim_image(img, mapping_entry)
|
||||
else:
|
||||
self.save_standard_image(img)
|
||||
|
||||
self.current_index += 1
|
||||
progress = 85.0 + (self.current_index / len(self.selected_images)) * 15.0
|
||||
props.operation_progress = progress
|
||||
|
||||
# Force UI update
|
||||
for area in bpy.context.screen.areas:
|
||||
area.tag_redraw()
|
||||
|
||||
# Continue processing
|
||||
return 0.01
|
||||
|
||||
def show_summary_dialog(self, context, total_selected, success_count, overwrite_skipped_list, failed_remap_list):
|
||||
"""Show a popup dialog with the extraction summary"""
|
||||
overwrite_details = ""
|
||||
if overwrite_skipped_list:
|
||||
for name, path in overwrite_skipped_list:
|
||||
overwrite_details += f"'{name}' -> '{path}'\n"
|
||||
|
||||
failed_remap_details = ""
|
||||
if failed_remap_list:
|
||||
for name, path in failed_remap_list:
|
||||
failed_remap_details += f"'{name}' -> '{path}'\n"
|
||||
|
||||
bpy.ops.bst.automat_summary_dialog('INVOKE_DEFAULT',
|
||||
total_selected=total_selected,
|
||||
success_count=success_count,
|
||||
overwrite_skipped_count=len(overwrite_skipped_list),
|
||||
failed_remap_count=len(failed_remap_list),
|
||||
overwrite_details=overwrite_details.strip(),
|
||||
failed_remap_details=failed_remap_details.strip()
|
||||
)
|
||||
|
||||
def sanitize_filename(self, filename):
|
||||
"""Sanitize filename/folder name for filesystem compatibility"""
|
||||
# First, remove potential file extensions, including numerical ones like .001
|
||||
base_name = re.sub(r'\.\d{3}$', '', filename) # Remove .001, .002 etc.
|
||||
base_name = os.path.splitext(base_name)[0] # Remove standard extensions
|
||||
|
||||
# Remove or replace invalid characters for Windows/Mac/Linux
|
||||
sanitized = re.sub(r'[<>:"/\\|?*]', '_', base_name)
|
||||
# Remove leading/trailing spaces and dots
|
||||
sanitized = sanitized.strip(' .')
|
||||
# Ensure it's not empty
|
||||
if not sanitized:
|
||||
sanitized = "unnamed"
|
||||
return sanitized
|
||||
|
||||
def get_image_material_mapping(self, images):
|
||||
"""Create mapping of image names to materials that use them"""
|
||||
image_to_materials = {}
|
||||
|
||||
# Initialize mapping
|
||||
for img in images:
|
||||
image_to_materials[img.name] = []
|
||||
|
||||
# Check all materials for image usage
|
||||
for material in bpy.data.materials:
|
||||
if not material.use_nodes:
|
||||
continue
|
||||
|
||||
material_images = set()
|
||||
|
||||
# Find all image texture nodes in this material
|
||||
for node in material.node_tree.nodes:
|
||||
if node.type == 'TEX_IMAGE' and node.image:
|
||||
material_images.add(node.image.name)
|
||||
|
||||
# Add this material to each image's usage list
|
||||
for img_name in material_images:
|
||||
if img_name in image_to_materials:
|
||||
image_to_materials[img_name].append(material.name)
|
||||
|
||||
return image_to_materials
|
||||
|
||||
def is_udim_image(self, image):
|
||||
"""Return True when the image contains UDIM/tiled data"""
|
||||
has_tiles = hasattr(image, "source") and image.source == 'TILED'
|
||||
tiles_attr = getattr(image, "tiles", None)
|
||||
if tiles_attr and len(tiles_attr) > 1:
|
||||
return True
|
||||
return has_tiles
|
||||
|
||||
def build_udim_mapping(self, base_folder, base_name, extension, image):
|
||||
"""Create a path mapping structure for UDIM images"""
|
||||
udim_token = "<UDIM>"
|
||||
template_filename = f"{base_name}.{udim_token}{extension}"
|
||||
template_path = f"{base_folder}\\{template_filename}"
|
||||
tile_paths = {}
|
||||
|
||||
tiles = getattr(image, "tiles", [])
|
||||
for tile in tiles:
|
||||
tile_number = str(getattr(tile, "number", "1001"))
|
||||
tile_filename = f"{base_name}.{tile_number}{extension}"
|
||||
tile_paths[tile_number] = f"{base_folder}\\{tile_filename}"
|
||||
|
||||
return {
|
||||
"udim": True,
|
||||
"template": template_path,
|
||||
"tiles": tile_paths,
|
||||
}
|
||||
|
||||
def save_udim_image(self, image, mapping):
|
||||
"""Attempt to save each tile for a UDIM image"""
|
||||
success = False
|
||||
try:
|
||||
image.save()
|
||||
success = True
|
||||
except Exception as e:
|
||||
print(f"DEBUG: UDIM bulk save failed for {image.name}: {e}")
|
||||
success = self._save_udim_tiles_individually(image, mapping)
|
||||
|
||||
if success:
|
||||
self.udim_summary["saved"] += 1
|
||||
return success
|
||||
|
||||
def save_standard_image(self, image):
|
||||
"""Save a non-UDIM image safely"""
|
||||
try:
|
||||
if hasattr(image, 'save'):
|
||||
image.save()
|
||||
return True
|
||||
except Exception as e:
|
||||
print(f"DEBUG: Failed to save image {image.name}: {e}")
|
||||
return False
|
||||
|
||||
def _save_udim_tiles_individually(self, image, mapping):
|
||||
"""Fallback saving routine when image.save() fails on UDIMs"""
|
||||
tile_paths = mapping.get("tiles", {})
|
||||
any_saved = False
|
||||
|
||||
for tile in getattr(image, "tiles", []):
|
||||
tile_number = str(getattr(tile, "number", "1001"))
|
||||
target_path = tile_paths.get(tile_number)
|
||||
if not target_path:
|
||||
continue
|
||||
try:
|
||||
ensure_directory_for_path(target_path)
|
||||
self._save_tile_via_image_editor(image, tile_number, target_path)
|
||||
any_saved = True
|
||||
except Exception as e:
|
||||
print(f"DEBUG: Failed to save UDIM tile {tile_number} for {image.name}: {e}")
|
||||
|
||||
return any_saved
|
||||
|
||||
def _save_tile_via_image_editor(self, image, tile_number, filepath):
|
||||
"""Use an IMAGE_EDITOR override to save a specific tile"""
|
||||
# Try to find an existing image editor to reuse Blender UI context
|
||||
for area in bpy.context.screen.areas:
|
||||
if area.type != 'IMAGE_EDITOR':
|
||||
continue
|
||||
override = bpy.context.copy()
|
||||
override['area'] = area
|
||||
override['space_data'] = area.spaces.active
|
||||
region = next((r for r in area.regions if r.type == 'WINDOW'), None)
|
||||
if region is None:
|
||||
continue
|
||||
override['region'] = region
|
||||
space = area.spaces.active
|
||||
space.image = image
|
||||
if hasattr(space, "image_user"):
|
||||
space.image_user.tile = int(tile_number)
|
||||
bpy.ops.image.save(override, filepath=filepath)
|
||||
return
|
||||
# Fallback: attempt to set filepath and invoke save without override
|
||||
image.filepath = filepath
|
||||
image.save()
|
||||
|
||||
# Must register the new dialog class as well
|
||||
classes = (
|
||||
AUTOMAT_OT_summary_dialog,
|
||||
AutoMatExtractor,
|
||||
)
|
||||
|
||||
def register():
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
|
||||
def unregister():
|
||||
for cls in reversed(classes):
|
||||
bpy.utils.unregister_class(cls)
|
||||
|
||||
@@ -1,14 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class BST_FreeGPU(bpy.types.Operator):
|
||||
bl_idname = "bst.free_gpu"
|
||||
bl_label = "Free VRAM"
|
||||
bl_description = "Unallocate all material images from VRAM"
|
||||
|
||||
def execute(self, context):
|
||||
for mat in bpy.data.materials:
|
||||
if mat.use_nodes:
|
||||
for node in mat.node_tree.nodes:
|
||||
if hasattr(node, 'image') and node.image:
|
||||
node.image.gl_free()
|
||||
return {"FINISHED"}
|
||||
@@ -1,29 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class NoSubdiv(bpy.types.Operator):
|
||||
"""Remove all subdivision surface modifiers from objects"""
|
||||
bl_idname = "bst.no_subdiv"
|
||||
bl_label = "No Subdiv"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
only_selected: bpy.props.BoolProperty(
|
||||
name="Only Selected Objects",
|
||||
description="Apply only to selected objects",
|
||||
default=True
|
||||
)
|
||||
|
||||
def execute(self, context):
|
||||
# Choose objects based on the property
|
||||
if self.only_selected:
|
||||
objects = context.selected_objects
|
||||
else:
|
||||
objects = bpy.data.objects
|
||||
removed_count = 0
|
||||
for obj in objects:
|
||||
if obj.modifiers:
|
||||
subdiv_mods = [mod for mod in obj.modifiers if mod.type == 'SUBSURF']
|
||||
for mod in subdiv_mods:
|
||||
obj.modifiers.remove(mod)
|
||||
removed_count += 1
|
||||
self.report({'INFO'}, f"Subdivision Surface modifiers removed from {'selected' if self.only_selected else 'all'} objects. ({removed_count} removed)")
|
||||
return {'FINISHED'}
|
||||
@@ -1,513 +0,0 @@
|
||||
import bpy
|
||||
import re
|
||||
|
||||
class RENAME_OT_summary_dialog(bpy.types.Operator):
|
||||
"""Show rename operation summary"""
|
||||
bl_idname = "bst.rename_summary_dialog"
|
||||
bl_label = "Rename Summary"
|
||||
bl_options = {'REGISTER', 'INTERNAL'}
|
||||
|
||||
# Properties to store summary data
|
||||
total_selected: bpy.props.IntProperty(default=0)
|
||||
renamed_count: bpy.props.IntProperty(default=0)
|
||||
shared_count: bpy.props.IntProperty(default=0)
|
||||
unused_count: bpy.props.IntProperty(default=0)
|
||||
cc3iid_count: bpy.props.IntProperty(default=0)
|
||||
flatcolor_count: bpy.props.IntProperty(default=0)
|
||||
already_correct_count: bpy.props.IntProperty(default=0)
|
||||
unrecognized_suffix_count: bpy.props.IntProperty(default=0)
|
||||
rename_details: bpy.props.StringProperty(default="")
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Title
|
||||
layout.label(text="Rename by Material - Summary", icon='INFO')
|
||||
layout.separator()
|
||||
|
||||
# Statistics box
|
||||
box = layout.box()
|
||||
col = box.column(align=True)
|
||||
col.label(text=f"Total selected images: {self.total_selected}")
|
||||
col.label(text=f"Successfully renamed: {self.renamed_count}", icon='CHECKMARK')
|
||||
|
||||
if self.already_correct_count > 0:
|
||||
col.label(text=f"Already correctly named: {self.already_correct_count}", icon='CHECKMARK')
|
||||
if self.shared_count > 0:
|
||||
col.label(text=f"Shared images skipped: {self.shared_count}", icon='RADIOBUT_OFF')
|
||||
if self.unused_count > 0:
|
||||
col.label(text=f"Unused images skipped: {self.unused_count}", icon='RADIOBUT_OFF')
|
||||
if self.cc3iid_count > 0:
|
||||
col.label(text=f"CC3 ID textures skipped: {self.cc3iid_count}", icon='RADIOBUT_OFF')
|
||||
if self.flatcolor_count > 0:
|
||||
col.label(text=f"Flat colors skipped: {self.flatcolor_count}", icon='RADIOBUT_OFF')
|
||||
if self.unrecognized_suffix_count > 0:
|
||||
col.label(text=f"Unrecognized suffixes skipped: {self.unrecognized_suffix_count}", icon='RADIOBUT_OFF')
|
||||
|
||||
# Show detailed rename information if available
|
||||
if self.rename_details:
|
||||
layout.separator()
|
||||
box = layout.box()
|
||||
box.label(text="Renamed Images:", icon='FILE_TEXT')
|
||||
|
||||
# Split the details by lines and show each one
|
||||
lines = self.rename_details.split('\n')
|
||||
for line in lines[:10]: # Limit to first 10 to avoid overly long dialogs
|
||||
if line.strip():
|
||||
box.label(text=line)
|
||||
|
||||
if len(lines) > 10:
|
||||
box.label(text=f"... and {len(lines) - 10} more")
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
return context.window_manager.invoke_popup(self, width=500)
|
||||
|
||||
class Rename_images_by_mat(bpy.types.Operator):
|
||||
bl_idname = "bst.rename_images_by_mat"
|
||||
bl_label = "Rename Images by Material"
|
||||
bl_description = "Rename selected images based on their material usage, preserving texture type suffixes"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
# Get selected images
|
||||
selected_images = [img for img in bpy.data.images if hasattr(img, "bst_selected") and img.bst_selected]
|
||||
|
||||
if not selected_images:
|
||||
self.report({'WARNING'}, "No images selected for renaming")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# Get image to material mapping
|
||||
image_to_materials = self.get_image_material_mapping(selected_images)
|
||||
|
||||
renamed_count = 0
|
||||
shared_count = 0
|
||||
unused_count = 0
|
||||
cc3iid_count = 0 # Track CC3 ID textures
|
||||
flatcolor_count = 0 # Track flat color textures
|
||||
already_correct_count = 0 # Track images already correctly named
|
||||
unrecognized_suffix_count = 0 # Track images with unrecognized suffixes
|
||||
renamed_list = [] # Track renamed images for debug
|
||||
unrecognized_list = [] # Track images with unrecognized suffixes
|
||||
|
||||
for img in selected_images:
|
||||
# Skip CC3 ID textures (ignore case)
|
||||
if img.name.lower().startswith('cc3iid'):
|
||||
cc3iid_count += 1
|
||||
print(f"DEBUG: Skipped CC3 ID texture: {img.name}")
|
||||
continue
|
||||
|
||||
# Skip flat color textures (start with #)
|
||||
if img.name.startswith('#'):
|
||||
flatcolor_count += 1
|
||||
print(f"DEBUG: Skipped flat color texture: {img.name}")
|
||||
continue
|
||||
|
||||
materials = image_to_materials.get(img.name, [])
|
||||
|
||||
if len(materials) == 0:
|
||||
# Unused image - skip
|
||||
unused_count += 1
|
||||
print(f"DEBUG: Skipped unused image: {img.name}")
|
||||
continue
|
||||
elif len(materials) == 1:
|
||||
# Single material usage - check suffix recognition
|
||||
material_name = materials[0]
|
||||
suffix = self.extract_texture_suffix(img.name)
|
||||
original_name = img.name
|
||||
|
||||
# Skip images with unrecognized suffixes (only if they have a potential suffix pattern)
|
||||
if suffix is None and self.has_potential_suffix(img.name):
|
||||
unrecognized_suffix_count += 1
|
||||
unrecognized_list.append(img.name)
|
||||
print(f"DEBUG: Skipped image with unrecognized suffix: {img.name}")
|
||||
continue
|
||||
|
||||
if suffix:
|
||||
# Capitalize the suffix properly
|
||||
capitalized_suffix = self.capitalize_suffix(suffix)
|
||||
expected_name = f"{material_name}_{capitalized_suffix}"
|
||||
else:
|
||||
# No suffix detected, use material name only
|
||||
expected_name = material_name
|
||||
|
||||
# Check if the image is already correctly named
|
||||
if img.name == expected_name:
|
||||
already_correct_count += 1
|
||||
print(f"DEBUG: Skipped already correctly named: {img.name}")
|
||||
continue
|
||||
|
||||
# Avoid duplicate names
|
||||
new_name = self.ensure_unique_name(expected_name)
|
||||
|
||||
img.name = new_name
|
||||
renamed_count += 1
|
||||
renamed_list.append((original_name, new_name, material_name, capitalized_suffix if suffix else None))
|
||||
print(f"DEBUG: Renamed '{original_name}' → '{new_name}' (Material: {material_name}, Suffix: {capitalized_suffix if suffix else 'none'})")
|
||||
else:
|
||||
# Shared across multiple materials - skip
|
||||
shared_count += 1
|
||||
print(f"DEBUG: Skipped shared image: {img.name} (used by {len(materials)} materials: {', '.join(materials[:3])}{'...' if len(materials) > 3 else ''})")
|
||||
|
||||
# Console debug summary (keep for development)
|
||||
print(f"\n=== RENAME BY MATERIAL SUMMARY ===")
|
||||
print(f"Total selected: {len(selected_images)}")
|
||||
print(f"Renamed: {renamed_count}")
|
||||
print(f"Already correct (skipped): {already_correct_count}")
|
||||
print(f"Shared (skipped): {shared_count}")
|
||||
print(f"Unused (skipped): {unused_count}")
|
||||
print(f"CC3 ID textures (skipped): {cc3iid_count}")
|
||||
print(f"Flat colors (skipped): {flatcolor_count}")
|
||||
print(f"Unrecognized suffixes (skipped): {unrecognized_suffix_count}")
|
||||
|
||||
if renamed_list:
|
||||
print(f"\nDetailed rename log:")
|
||||
for original, new, material, suffix in renamed_list:
|
||||
suffix_info = f" (suffix: {suffix})" if suffix else " (no suffix)"
|
||||
print(f" '{original}' → '{new}' for material '{material}'{suffix_info}")
|
||||
|
||||
if unrecognized_list:
|
||||
print(f"\nImages with unrecognized suffixes:")
|
||||
for img_name in unrecognized_list:
|
||||
print(f" '{img_name}'")
|
||||
|
||||
print(f"===================================\n")
|
||||
|
||||
# Show popup summary dialog
|
||||
self.show_summary_dialog(context, len(selected_images), renamed_count, shared_count, unused_count, cc3iid_count, flatcolor_count, already_correct_count, unrecognized_suffix_count, renamed_list)
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def show_summary_dialog(self, context, total_selected, renamed_count, shared_count, unused_count, cc3iid_count, flatcolor_count, already_correct_count, unrecognized_suffix_count, renamed_list):
|
||||
"""Show a popup dialog with the rename summary"""
|
||||
# Prepare detailed rename information for display
|
||||
details_text = ""
|
||||
if renamed_list:
|
||||
for original, new, material, suffix in renamed_list:
|
||||
suffix_info = f" ({suffix})" if suffix else ""
|
||||
details_text += f"'{original}' → '{new}'{suffix_info}\n"
|
||||
|
||||
# Invoke the summary dialog
|
||||
dialog = bpy.ops.bst.rename_summary_dialog('INVOKE_DEFAULT',
|
||||
total_selected=total_selected,
|
||||
renamed_count=renamed_count,
|
||||
shared_count=shared_count,
|
||||
unused_count=unused_count,
|
||||
cc3iid_count=cc3iid_count,
|
||||
flatcolor_count=flatcolor_count,
|
||||
already_correct_count=already_correct_count,
|
||||
unrecognized_suffix_count=unrecognized_suffix_count,
|
||||
rename_details=details_text.strip())
|
||||
|
||||
def get_image_material_mapping(self, images):
|
||||
"""Create mapping of image names to materials that use them"""
|
||||
image_to_materials = {}
|
||||
|
||||
# Initialize mapping
|
||||
for img in images:
|
||||
image_to_materials[img.name] = []
|
||||
|
||||
# Check all materials for image usage
|
||||
for material in bpy.data.materials:
|
||||
if not material.use_nodes:
|
||||
continue
|
||||
|
||||
material_images = set()
|
||||
|
||||
# Find all image texture nodes in this material
|
||||
for node in material.node_tree.nodes:
|
||||
if node.type == 'TEX_IMAGE' and node.image:
|
||||
material_images.add(node.image.name)
|
||||
|
||||
# Add this material to each image's usage list
|
||||
for img_name in material_images:
|
||||
if img_name in image_to_materials:
|
||||
image_to_materials[img_name].append(material.name)
|
||||
|
||||
return image_to_materials
|
||||
|
||||
def extract_texture_suffix(self, name):
|
||||
"""Extract texture type suffix from image name (case-insensitive)"""
|
||||
# Comprehensive list of texture suffixes
|
||||
suffixes = [
|
||||
# Standard PBR suffixes
|
||||
'diffuse', 'basecolor', 'base_color', 'albedo', 'color', 'col',
|
||||
'normal', 'norm', 'nrm', 'bump',
|
||||
'roughness', 'rough', 'rgh',
|
||||
'metallic', 'metal', 'mtl',
|
||||
'specular', 'spec', 'spc',
|
||||
'ao', 'ambient_occlusion', 'ambientocclusion', 'occlusion',
|
||||
'gradao',
|
||||
'height', 'displacement', 'disp', 'displace',
|
||||
'opacity', 'alpha', 'mask',
|
||||
'emission', 'emissive', 'emit',
|
||||
'subsurface', 'sss', 'transmission',
|
||||
|
||||
# Character Creator / iClone suffixes
|
||||
'base', 'diffusemap', 'normalmap', 'roughnessmap', 'metallicmap',
|
||||
'aomap', 'opacitymap', 'emissionmap', 'heightmap', 'displacementmap',
|
||||
'detail_normal', 'detail_diffuse', 'detail_mask',
|
||||
'blend', 'id', 'cavity', 'curvature', 'transmap', 'rgbamask', 'sssmap', 'micronmask',
|
||||
'bcbmap', 'mnaomask', 'specmask', 'micron', 'cfulcmask', 'nmuilmask', 'nbmap', 'enmask', 'blend_multiply',
|
||||
|
||||
# Hair-related compound suffixes (no spaces)
|
||||
'hairflowmap', 'hairidmap', 'hairrootmap', 'hairdepthmap',
|
||||
'flowmap', 'idmap', 'rootmap', 'depthmap',
|
||||
|
||||
# Wrinkle map suffixes (Character Creator)
|
||||
'wrinkle_normal1', 'wrinkle_normal2', 'wrinkle_normal3',
|
||||
'wrinkle_roughness1', 'wrinkle_roughness2', 'wrinkle_roughness3',
|
||||
'wrinkle_diffuse1', 'wrinkle_diffuse2', 'wrinkle_diffuse3',
|
||||
'wrinkle_mask1', 'wrinkle_mask2', 'wrinkle_mask3',
|
||||
'wrinkle_flow1', 'wrinkle_flow2', 'wrinkle_flow3',
|
||||
|
||||
# Character Creator pack suffixes (with spaces)
|
||||
'flow pack', 'msmnao pack', 'roughness pack', 'sstm pack',
|
||||
'flow_pack', 'msmnao_pack', 'roughness_pack', 'sstm_pack',
|
||||
|
||||
# Hair-related multi-word suffixes (spaces)
|
||||
'hair flow map', 'hair id map', 'hair root map', 'hair depth map',
|
||||
'flow map', 'id map', 'root map', 'depth map',
|
||||
|
||||
# Additional common variations
|
||||
'tex', 'map', 'img', 'texture',
|
||||
'd', 'n', 'r', 'm', 's', 'a', 'h', 'o', 'e' # Single letter abbreviations
|
||||
]
|
||||
|
||||
# Remove file extension first
|
||||
base_name = re.sub(r'\.[^.]+$', '', name)
|
||||
|
||||
# Sort suffixes by length (longest first) to prioritize more specific matches
|
||||
sorted_suffixes = sorted(suffixes, key=len, reverse=True)
|
||||
|
||||
# First, try to find multi-word suffixes with spaces (case-insensitive)
|
||||
for suffix in sorted_suffixes:
|
||||
if ' ' in suffix: # Multi-word suffix
|
||||
# Pattern: ends with space + suffix
|
||||
pattern = rf'\s+({re.escape(suffix)})$'
|
||||
match = re.search(pattern, base_name, re.IGNORECASE)
|
||||
if match:
|
||||
return match.group(1).lower()
|
||||
|
||||
# Pattern: ends with suffix (no space separator, but exact match)
|
||||
if base_name.lower().endswith(suffix.lower()) and len(base_name) > len(suffix):
|
||||
# Check if there's a word boundary before the suffix
|
||||
prefix_end = len(base_name) - len(suffix)
|
||||
if prefix_end > 0 and base_name[prefix_end - 1] in ' _-':
|
||||
return suffix.lower()
|
||||
|
||||
# Then try single-word suffixes with traditional separators
|
||||
for suffix in sorted_suffixes:
|
||||
if ' ' not in suffix: # Single word suffix
|
||||
# Pattern: ends with _suffix or -suffix or .suffix
|
||||
pattern = rf'[._-]({re.escape(suffix)})$'
|
||||
match = re.search(pattern, base_name, re.IGNORECASE)
|
||||
if match:
|
||||
return match.group(1).lower()
|
||||
|
||||
# Check for numeric suffixes (like _01, _02, etc.)
|
||||
numeric_match = re.search(r'[._-](\d+)$', base_name)
|
||||
if numeric_match:
|
||||
return numeric_match.group(1)
|
||||
|
||||
return None
|
||||
|
||||
def ensure_unique_name(self, proposed_name):
|
||||
"""Ensure the proposed name is unique among all images"""
|
||||
if proposed_name not in bpy.data.images:
|
||||
return proposed_name
|
||||
|
||||
# If name exists, add numerical suffix
|
||||
counter = 1
|
||||
while f"{proposed_name}.{counter:03d}" in bpy.data.images:
|
||||
counter += 1
|
||||
|
||||
return f"{proposed_name}.{counter:03d}"
|
||||
|
||||
def capitalize_suffix(self, suffix):
|
||||
"""Properly capitalize texture type suffixes with correct formatting"""
|
||||
# Dictionary of common texture suffixes with proper capitalization
|
||||
suffix_mapping = {
|
||||
# Standard PBR suffixes
|
||||
'diffuse': 'Diffuse',
|
||||
'basecolor': 'BaseColor',
|
||||
'base_color': 'BaseColor',
|
||||
'albedo': 'Albedo',
|
||||
'color': 'Color',
|
||||
'col': 'Color',
|
||||
|
||||
'normal': 'Normal',
|
||||
'norm': 'Normal',
|
||||
'nrm': 'Normal',
|
||||
'bump': 'Bump',
|
||||
|
||||
'roughness': 'Roughness',
|
||||
'rough': 'Roughness',
|
||||
'rgh': 'Roughness',
|
||||
|
||||
'metallic': 'Metallic',
|
||||
'metal': 'Metallic',
|
||||
'mtl': 'Metallic',
|
||||
|
||||
'specular': 'Specular',
|
||||
'spec': 'Specular',
|
||||
'spc': 'Specular',
|
||||
|
||||
'ao': 'AO',
|
||||
'ambient_occlusion': 'AmbientOcclusion',
|
||||
'ambientocclusion': 'AmbientOcclusion',
|
||||
'occlusion': 'Occlusion',
|
||||
'gradao': 'GradAO',
|
||||
|
||||
'height': 'Height',
|
||||
'displacement': 'Displacement',
|
||||
'disp': 'Displacement',
|
||||
'displace': 'Displacement',
|
||||
|
||||
'opacity': 'Opacity',
|
||||
'alpha': 'Alpha',
|
||||
'mask': 'Mask',
|
||||
'transmap': 'TransMap',
|
||||
|
||||
'emission': 'Emission',
|
||||
'emissive': 'Emission',
|
||||
'emit': 'Emission',
|
||||
|
||||
'subsurface': 'Subsurface',
|
||||
'sss': 'SSS',
|
||||
'transmission': 'Transmission',
|
||||
|
||||
# Character Creator / iClone suffixes
|
||||
'base': 'Base',
|
||||
'diffusemap': 'DiffuseMap',
|
||||
'normalmap': 'NormalMap',
|
||||
'roughnessmap': 'RoughnessMap',
|
||||
'metallicmap': 'MetallicMap',
|
||||
'aomap': 'AOMap',
|
||||
'opacitymap': 'OpacityMap',
|
||||
'emissionmap': 'EmissionMap',
|
||||
'heightmap': 'HeightMap',
|
||||
'displacementmap': 'DisplacementMap',
|
||||
'detail_normal': 'DetailNormal',
|
||||
'detail_diffuse': 'DetailDiffuse',
|
||||
'detail_mask': 'DetailMask',
|
||||
'blend': 'Blend',
|
||||
'id': 'ID',
|
||||
'cavity': 'Cavity',
|
||||
'curvature': 'Curvature',
|
||||
'transmap': 'TransMap',
|
||||
'rgbamask': 'RGBAMask',
|
||||
'sssmap': 'SSSMap',
|
||||
'micronmask': 'MicroNMask',
|
||||
'bcbmap': 'BCBMap',
|
||||
'mnaomask': 'MNAOMask',
|
||||
'specmask': 'SpecMask',
|
||||
'micron': 'MicroN',
|
||||
'cfulcmask': 'CFULCMask',
|
||||
'nmuilmask': 'NMUILMask',
|
||||
'nbmap': 'NBMap',
|
||||
'enmask': 'ENMask',
|
||||
'blend_multiply': 'Blend_Multiply',
|
||||
|
||||
# Hair-related compound suffixes (no spaces)
|
||||
'hairflowmap': 'HairFlowMap',
|
||||
'hairidmap': 'HairIDMap',
|
||||
'hairrootmap': 'HairRootMap',
|
||||
'hairdepthmap': 'HairDepthMap',
|
||||
'flowmap': 'FlowMap',
|
||||
'idmap': 'IDMap',
|
||||
'rootmap': 'RootMap',
|
||||
'depthmap': 'DepthMap',
|
||||
|
||||
# Wrinkle map suffixes (Character Creator)
|
||||
'wrinkle_normal1': 'Wrinkle_Normal1',
|
||||
'wrinkle_normal2': 'Wrinkle_Normal2',
|
||||
'wrinkle_normal3': 'Wrinkle_Normal3',
|
||||
'wrinkle_roughness1': 'Wrinkle_Roughness1',
|
||||
'wrinkle_roughness2': 'Wrinkle_Roughness2',
|
||||
'wrinkle_roughness3': 'Wrinkle_Roughness3',
|
||||
'wrinkle_diffuse1': 'Wrinkle_Diffuse1',
|
||||
'wrinkle_diffuse2': 'Wrinkle_Diffuse2',
|
||||
'wrinkle_diffuse3': 'Wrinkle_Diffuse3',
|
||||
'wrinkle_mask1': 'Wrinkle_Mask1',
|
||||
'wrinkle_mask2': 'Wrinkle_Mask2',
|
||||
'wrinkle_mask3': 'Wrinkle_Mask3',
|
||||
'wrinkle_flow1': 'Wrinkle_Flow1',
|
||||
'wrinkle_flow2': 'Wrinkle_Flow2',
|
||||
'wrinkle_flow3': 'Wrinkle_Flow3',
|
||||
|
||||
# Character Creator pack suffixes (with spaces)
|
||||
'flow pack': 'Flow Pack',
|
||||
'msmnao pack': 'MSMNAO Pack',
|
||||
'roughness pack': 'Roughness Pack',
|
||||
'sstm pack': 'SSTM Pack',
|
||||
'flow_pack': 'Flow_Pack',
|
||||
'msmnao_pack': 'MSMNAO_Pack',
|
||||
'roughness_pack': 'Roughness_Pack',
|
||||
'sstm_pack': 'SSTM_Pack',
|
||||
|
||||
# Hair-related multi-word suffixes
|
||||
'hair flow map': 'HairFlowMap',
|
||||
'hair id map': 'HairIDMap',
|
||||
'hair root map': 'HairRootMap',
|
||||
'hair depth map': 'HairDepthMap',
|
||||
'flow map': 'FlowMap',
|
||||
'id map': 'IDMap',
|
||||
'root map': 'RootMap',
|
||||
'depth map': 'DepthMap',
|
||||
|
||||
# Additional common variations
|
||||
'tex': 'Texture',
|
||||
'map': 'Map',
|
||||
'img': 'Image',
|
||||
'texture': 'Texture',
|
||||
|
||||
# Single letter abbreviations
|
||||
'd': 'Diffuse',
|
||||
'n': 'Normal',
|
||||
'r': 'Roughness',
|
||||
'm': 'Metallic',
|
||||
's': 'Specular',
|
||||
'a': 'Alpha',
|
||||
'h': 'Height',
|
||||
'o': 'Occlusion',
|
||||
'e': 'Emission'
|
||||
}
|
||||
|
||||
# Get the proper capitalization from mapping, or capitalize first letter as fallback
|
||||
return suffix_mapping.get(suffix.lower(), suffix.capitalize())
|
||||
|
||||
def has_potential_suffix(self, name):
|
||||
"""Check if the image name has a potential suffix pattern that we should try to recognize"""
|
||||
# Remove file extension first
|
||||
base_name = re.sub(r'\.[^.]+$', '', name)
|
||||
|
||||
# Check for common suffix patterns: _something, -something, .something, or space something
|
||||
suffix_patterns = [
|
||||
r'[._-][a-zA-Z0-9]+$', # Underscore, dot, or dash followed by alphanumeric
|
||||
r'\s+[a-zA-Z0-9\s]+$', # Space followed by alphanumeric (for multi-word suffixes)
|
||||
]
|
||||
|
||||
for pattern in suffix_patterns:
|
||||
if re.search(pattern, base_name):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
|
||||
# Registration classes - need to register both operators
|
||||
classes = (
|
||||
RENAME_OT_summary_dialog,
|
||||
Rename_images_by_mat,
|
||||
)
|
||||
|
||||
def register():
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
|
||||
def unregister():
|
||||
for cls in reversed(classes):
|
||||
bpy.utils.unregister_class(cls)
|
||||
|
||||
@@ -1,87 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class ConvertRelationsToConstraint(bpy.types.Operator):
|
||||
"""Convert regular parenting to Child Of constraints for all selected objects"""
|
||||
bl_idname = "bst.convert_relations_to_constraint"
|
||||
bl_label = "Convert Relations to Constraint"
|
||||
bl_description = "Convert regular parenting relationships to Child Of constraints for selected objects"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
result = convert_relations_to_constraint()
|
||||
if result:
|
||||
self.report({'INFO'}, f"Converted {result} objects to Child Of constraints")
|
||||
else:
|
||||
self.report({'WARNING'}, "No objects with parents found in selection")
|
||||
return {'FINISHED'}
|
||||
|
||||
def convert_relations_to_constraint():
|
||||
"""Convert regular parenting to Child Of constraints for all selected objects"""
|
||||
|
||||
# Get all selected objects
|
||||
selected_objects = bpy.context.selected_objects
|
||||
|
||||
if not selected_objects:
|
||||
print("No objects selected!")
|
||||
return 0
|
||||
|
||||
print(f"Converting parenting to Child Of constraints for {len(selected_objects)} objects...")
|
||||
|
||||
converted_count = 0
|
||||
|
||||
for obj in selected_objects:
|
||||
# Check if object has a parent
|
||||
if obj.parent is None:
|
||||
print(f"Skipping {obj.name}: No parent found")
|
||||
continue
|
||||
|
||||
# Store bone information if parented to a bone
|
||||
parent_bone = obj.parent_bone if obj.parent_bone else None
|
||||
bone_info = f" (bone: {parent_bone})" if parent_bone else ""
|
||||
print(f"Processing {obj.name} -> {obj.parent.name}{bone_info}")
|
||||
|
||||
# Store original parent and current world matrix
|
||||
original_parent = obj.parent
|
||||
world_matrix = obj.matrix_world.copy()
|
||||
|
||||
# Remove the parent relationship
|
||||
obj.parent = None
|
||||
obj.parent_bone = "" # Clear the bone reference
|
||||
|
||||
# Add Child Of constraint
|
||||
child_of_constraint = obj.constraints.new(type='CHILD_OF')
|
||||
child_of_constraint.name = f"Child_Of_{original_parent.name}"
|
||||
child_of_constraint.target = original_parent
|
||||
|
||||
# Transfer bone information to constraint subtarget
|
||||
if parent_bone:
|
||||
child_of_constraint.subtarget = parent_bone
|
||||
print(f" ✓ Transferred bone target: {parent_bone}")
|
||||
|
||||
# Set the inverse matrix properly to maintain world position
|
||||
# This is equivalent to clicking "Set Inverse" in the UI
|
||||
child_of_constraint.inverse_matrix = original_parent.matrix_world.inverted()
|
||||
|
||||
# Restore the original world position
|
||||
obj.matrix_world = world_matrix
|
||||
|
||||
# Set the constraint to be active
|
||||
child_of_constraint.influence = 1.0
|
||||
|
||||
converted_count += 1
|
||||
print(f" ✓ Converted {obj.name} to Child Of constraint")
|
||||
|
||||
print(f"\nConversion complete! Converted {converted_count} objects.")
|
||||
|
||||
# Report remaining parented objects
|
||||
remaining_parented = [obj for obj in bpy.context.selected_objects if obj.parent is not None]
|
||||
if remaining_parented:
|
||||
print(f"\nObjects that still have parents (not converted):")
|
||||
for obj in remaining_parented:
|
||||
print(f" - {obj.name} -> {obj.parent.name}")
|
||||
|
||||
return converted_count
|
||||
|
||||
# Run the conversion
|
||||
if __name__ == "__main__":
|
||||
convert_relations_to_constraint()
|
||||
@@ -1,47 +0,0 @@
|
||||
import bpy
|
||||
from bpy.types import Operator
|
||||
|
||||
class CreateOrthoCamera(Operator):
|
||||
"""Create an orthographic camera with predefined settings"""
|
||||
bl_idname = "bst.create_ortho_camera"
|
||||
bl_label = "Create Ortho Camera"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
# Create a new camera
|
||||
bpy.ops.object.camera_add()
|
||||
camera = context.active_object
|
||||
|
||||
# Set camera to orthographic
|
||||
camera.data.type = 'ORTHO'
|
||||
camera.data.ortho_scale = 1.8 # Set orthographic scale
|
||||
|
||||
# Set camera position
|
||||
camera.location = (0, -2, 1) # x=0, y=-2m, z=1m
|
||||
|
||||
# Set camera rotation (90 degrees around X axis)
|
||||
camera.rotation_euler = (1.5708, 0, 0) # 90 degrees in radians
|
||||
|
||||
# Get or create camera collection
|
||||
camera_collection = bpy.data.collections.get("Camera")
|
||||
if not camera_collection:
|
||||
camera_collection = bpy.data.collections.new("Camera")
|
||||
context.scene.collection.children.link(camera_collection)
|
||||
|
||||
# Move camera to camera collection
|
||||
# First unlink from current collection
|
||||
for collection in camera.users_collection:
|
||||
collection.objects.unlink(camera)
|
||||
# Then link to camera collection
|
||||
camera_collection.objects.link(camera)
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
def register():
|
||||
bpy.utils.register_class(CreateOrthoCamera)
|
||||
|
||||
def unregister():
|
||||
bpy.utils.unregister_class(CreateOrthoCamera)
|
||||
|
||||
if __name__ == "__main__":
|
||||
register()
|
||||
@@ -1,39 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class DeleteSingleKeyframeActions(bpy.types.Operator):
|
||||
"""Delete actions that have no keyframes, only one keyframe, or all keyframes on the same frame"""
|
||||
bl_idname = "bst.delete_single_keyframe_actions"
|
||||
bl_label = "Delete Single Keyframe Actions"
|
||||
bl_description = "Delete actions with unwanted keyframe patterns (no keyframes, single keyframe, or all keyframes on same frame)"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
actions = bpy.data.actions
|
||||
actions_to_delete = []
|
||||
|
||||
for action in actions:
|
||||
keyframe_frames = set()
|
||||
total_keyframes = 0
|
||||
for fcurve in action.fcurves:
|
||||
for kf in fcurve.keyframe_points:
|
||||
keyframe_frames.add(kf.co[0])
|
||||
total_keyframes += 1
|
||||
|
||||
# No keyframes
|
||||
if total_keyframes == 0:
|
||||
actions_to_delete.append(action)
|
||||
# Only one keyframe
|
||||
elif total_keyframes == 1:
|
||||
actions_to_delete.append(action)
|
||||
# All keyframes on the same frame
|
||||
elif len(keyframe_frames) == 1:
|
||||
actions_to_delete.append(action)
|
||||
|
||||
deleted_count = 0
|
||||
for action in actions_to_delete:
|
||||
print(f"Deleting action '{action.name}' (unwanted keyframe pattern)")
|
||||
bpy.data.actions.remove(action)
|
||||
deleted_count += 1
|
||||
|
||||
self.report({'INFO'}, f"Deleted {deleted_count} unwanted actions")
|
||||
return {'FINISHED'}
|
||||
@@ -1,157 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class MATERIAL_USERS_OT_summary_dialog(bpy.types.Operator):
|
||||
"""Show material users analysis in a popup dialog"""
|
||||
bl_idname = "bst.material_users_summary_dialog"
|
||||
bl_label = "Material Users Summary"
|
||||
bl_options = {'REGISTER', 'INTERNAL'}
|
||||
|
||||
# Properties to store summary data
|
||||
material_name: bpy.props.StringProperty(default="")
|
||||
users_count: bpy.props.IntProperty(default=0)
|
||||
fake_user: bpy.props.BoolProperty(default=False)
|
||||
object_users: bpy.props.StringProperty(default="")
|
||||
node_users: bpy.props.StringProperty(default="")
|
||||
material_node_users: bpy.props.StringProperty(default="")
|
||||
total_user_count: bpy.props.IntProperty(default=0)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Title
|
||||
layout.label(text=f"Material Users - '{self.material_name}'", icon='MATERIAL')
|
||||
layout.separator()
|
||||
|
||||
# Basic info box
|
||||
box = layout.box()
|
||||
col = box.column(align=True)
|
||||
col.label(text=f"Blender Users Count: {self.users_count}")
|
||||
col.label(text=f"Fake User: {'Yes' if self.fake_user else 'No'}")
|
||||
col.label(text=f"Total Found Users: {self.total_user_count}")
|
||||
|
||||
layout.separator()
|
||||
|
||||
# Object users section
|
||||
if self.object_users:
|
||||
layout.label(text="Object Users:", icon='OBJECT_DATA')
|
||||
objects_box = layout.box()
|
||||
objects_col = objects_box.column(align=True)
|
||||
for obj_name in self.object_users.split('|'):
|
||||
if obj_name.strip():
|
||||
objects_col.label(text=f"• {obj_name}", icon='RIGHTARROW_THIN')
|
||||
else:
|
||||
layout.label(text="Object Users: None", icon='OBJECT_DATA')
|
||||
|
||||
# Node tree users section
|
||||
if self.node_users:
|
||||
layout.separator()
|
||||
layout.label(text="Node Tree Users:", icon='NODETREE')
|
||||
nodes_box = layout.box()
|
||||
nodes_col = nodes_box.column(align=True)
|
||||
for node_ref in self.node_users.split('|'):
|
||||
if node_ref.strip():
|
||||
nodes_col.label(text=f"• {node_ref}", icon='RIGHTARROW_THIN')
|
||||
|
||||
# Material node tree users section
|
||||
if self.material_node_users:
|
||||
layout.separator()
|
||||
layout.label(text="Material Node Tree Users:", icon='MATERIAL')
|
||||
mat_nodes_box = layout.box()
|
||||
mat_nodes_col = mat_nodes_box.column(align=True)
|
||||
for mat_node_ref in self.material_node_users.split('|'):
|
||||
if mat_node_ref.strip():
|
||||
mat_nodes_col.label(text=f"• {mat_node_ref}", icon='RIGHTARROW_THIN')
|
||||
|
||||
layout.separator()
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
return context.window_manager.invoke_popup(self, width=500)
|
||||
|
||||
class FindMaterialUsers(bpy.types.Operator):
|
||||
"""Find all users of a specified material and display detailed information"""
|
||||
bl_idname = "bst.find_material_users"
|
||||
bl_label = "Find Material Users"
|
||||
bl_description = "Find and display all users of a specified material"
|
||||
bl_options = {'REGISTER'}
|
||||
|
||||
material_name: bpy.props.StringProperty(
|
||||
name="Material",
|
||||
description="Name of the material to analyze",
|
||||
default="",
|
||||
)
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Set the material if we have a name
|
||||
if self.material_name and self.material_name in bpy.data.materials:
|
||||
context.scene.bst_temp_material = bpy.data.materials[self.material_name]
|
||||
|
||||
# Use template_ID to get the proper material selector (without new button)
|
||||
layout.template_ID(context.scene, "bst_temp_material", text="Material")
|
||||
|
||||
def execute(self, context):
|
||||
# Get the material from the temp property
|
||||
material = getattr(context.scene, 'bst_temp_material', None)
|
||||
|
||||
if not material:
|
||||
self.report({'ERROR'}, "No material selected")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# Update our material_name property
|
||||
self.material_name = material.name
|
||||
|
||||
# Check objects
|
||||
object_users = []
|
||||
for obj in bpy.data.objects:
|
||||
if obj.material_slots:
|
||||
for slot in obj.material_slots:
|
||||
if slot.material == material:
|
||||
object_users.append(obj.name)
|
||||
break
|
||||
|
||||
# Check node groups more thoroughly
|
||||
node_users = []
|
||||
for node_tree in bpy.data.node_groups:
|
||||
for node in node_tree.nodes:
|
||||
# Check material nodes
|
||||
if hasattr(node, 'material') and node.material == material:
|
||||
node_users.append(f"{node_tree.name}.{node.name}")
|
||||
# Check material input sockets
|
||||
for input_socket in node.inputs:
|
||||
if hasattr(input_socket, 'default_value') and hasattr(input_socket.default_value, 'name'):
|
||||
if input_socket.default_value.name == material.name:
|
||||
node_users.append(f"{node_tree.name}.{node.name}.{input_socket.name}")
|
||||
|
||||
# Check material node trees
|
||||
material_node_users = []
|
||||
for mat in bpy.data.materials:
|
||||
if mat.node_tree:
|
||||
for node in mat.node_tree.nodes:
|
||||
if hasattr(node, 'material') and node.material == material:
|
||||
material_node_users.append(f"{mat.name}.{node.name}")
|
||||
|
||||
# Show summary dialog
|
||||
self.show_summary_dialog(context, material, object_users, node_users, material_node_users)
|
||||
return {'FINISHED'}
|
||||
|
||||
def show_summary_dialog(self, context, material, object_users, node_users, material_node_users):
|
||||
"""Show the material users summary in a popup dialog"""
|
||||
total_user_count = len(object_users) + len(node_users) + len(material_node_users)
|
||||
|
||||
# Create and configure the summary dialog
|
||||
dialog_op = bpy.ops.bst.material_users_summary_dialog
|
||||
dialog_op('INVOKE_DEFAULT',
|
||||
material_name=material.name,
|
||||
users_count=material.users,
|
||||
fake_user=material.use_fake_user,
|
||||
object_users='|'.join(object_users),
|
||||
node_users='|'.join(node_users),
|
||||
material_node_users='|'.join(material_node_users),
|
||||
total_user_count=total_user_count)
|
||||
|
||||
def invoke(self, context, event):
|
||||
return context.window_manager.invoke_props_dialog(self)
|
||||
@@ -1,253 +0,0 @@
|
||||
import bpy
|
||||
import bmesh
|
||||
from mathutils import Color
|
||||
|
||||
def rgb_to_hex(r, g, b, a=1.0):
|
||||
"""Convert RGBA values (0-1 range) to hex color code."""
|
||||
# Convert to 0-255 range and format as hex
|
||||
r_int = int(round(r * 255))
|
||||
g_int = int(round(g * 255))
|
||||
b_int = int(round(b * 255))
|
||||
a_int = int(round(a * 255))
|
||||
|
||||
# If alpha is full (255), use RGB format, otherwise use RGBA
|
||||
if a_int == 255:
|
||||
return f"#{r_int:02X}{g_int:02X}{b_int:02X}"
|
||||
else:
|
||||
return f"#{r_int:02X}{g_int:02X}{b_int:02X}{a_int:02X}"
|
||||
|
||||
def is_flat_color_image_efficient(image, max_pixels_to_check=10000):
|
||||
"""
|
||||
Efficiently check if an image has all pixels of the same color.
|
||||
|
||||
Args:
|
||||
image: The image to check
|
||||
max_pixels_to_check: Maximum number of pixels to check (for performance)
|
||||
|
||||
Returns:
|
||||
tuple: (is_flat, color) where is_flat is bool and color is RGBA tuple
|
||||
"""
|
||||
if not image or not image.pixels:
|
||||
print(f" DEBUG: No image or no pixels")
|
||||
return False, None
|
||||
|
||||
# Get pixel data
|
||||
pixels = image.pixels[:]
|
||||
|
||||
if len(pixels) == 0:
|
||||
print(f" DEBUG: Empty pixel array")
|
||||
return False, None
|
||||
|
||||
# Images in Blender are typically RGBA, so 4 values per pixel
|
||||
channels = image.channels
|
||||
if channels not in [3, 4]: # RGB or RGBA
|
||||
print(f" DEBUG: Unsupported channels: {channels}")
|
||||
return False, None
|
||||
|
||||
# Get the first pixel color as reference
|
||||
first_pixel = pixels[:channels]
|
||||
print(f" DEBUG: Reference color: {first_pixel}")
|
||||
|
||||
# Calculate total pixels
|
||||
total_pixels = len(pixels) // channels
|
||||
print(f" DEBUG: Total pixels: {total_pixels}")
|
||||
|
||||
# Determine how many pixels to check
|
||||
pixels_to_check = min(total_pixels, max_pixels_to_check)
|
||||
|
||||
# For small images, check every pixel
|
||||
if total_pixels <= max_pixels_to_check:
|
||||
step = 1
|
||||
print(f" DEBUG: Checking all {total_pixels} pixels")
|
||||
else:
|
||||
# For large images, sample evenly across the image
|
||||
step = total_pixels // pixels_to_check
|
||||
print(f" DEBUG: Sampling {pixels_to_check} pixels with step {step}")
|
||||
|
||||
# Check pixels
|
||||
checked_count = 0
|
||||
for i in range(0, total_pixels, step):
|
||||
pixel_start = i * channels
|
||||
current_pixel = pixels[pixel_start:pixel_start + channels]
|
||||
checked_count += 1
|
||||
|
||||
# Compare with reference pixel (exact match)
|
||||
for j in range(channels):
|
||||
if current_pixel[j] != first_pixel[j]:
|
||||
print(f" DEBUG: Pixel {i} differs at channel {j}: {current_pixel[j]} vs {first_pixel[j]}")
|
||||
print(f" DEBUG: Checked {checked_count} pixels before finding difference")
|
||||
return False, None
|
||||
|
||||
print(f" DEBUG: All {checked_count} checked pixels are identical")
|
||||
|
||||
# If we get here, all checked pixels are the same color
|
||||
if channels == 3:
|
||||
return True, (first_pixel[0], first_pixel[1], first_pixel[2], 1.0)
|
||||
else:
|
||||
return True, tuple(first_pixel)
|
||||
|
||||
def is_flat_color_image(image):
|
||||
"""Check if an image has all pixels of the same color."""
|
||||
# Use the efficient version by default
|
||||
return is_flat_color_image_efficient(image, max_pixels_to_check=10000)
|
||||
|
||||
def safe_rename_image(image, new_name):
|
||||
"""Safely rename an image datablock using context override."""
|
||||
try:
|
||||
# Method 1: Try direct assignment first (works in some contexts)
|
||||
image.name = new_name
|
||||
return True
|
||||
except:
|
||||
try:
|
||||
# Method 2: Use context override with outliner
|
||||
for area in bpy.context.screen.areas:
|
||||
if area.type == 'OUTLINER':
|
||||
with bpy.context.temp_override(area=area):
|
||||
image.name = new_name
|
||||
return True
|
||||
except:
|
||||
try:
|
||||
# Method 3: Use bpy.ops with context override
|
||||
# Set the image as active and use the rename operator
|
||||
bpy.context.view_layer.objects.active = None
|
||||
|
||||
# Create a temporary override context
|
||||
override_context = bpy.context.copy()
|
||||
override_context['edit_image'] = image
|
||||
|
||||
with bpy.context.temp_override(**override_context):
|
||||
image.name = new_name
|
||||
return True
|
||||
except:
|
||||
# Method 4: Try using the data API directly with update
|
||||
try:
|
||||
old_name = image.name
|
||||
# Force an update cycle
|
||||
bpy.context.view_layer.update()
|
||||
image.name = new_name
|
||||
bpy.context.view_layer.update()
|
||||
return True
|
||||
except:
|
||||
return False
|
||||
|
||||
def rename_flat_color_textures():
|
||||
"""Main function to find and rename flat color textures."""
|
||||
renamed_count = 0
|
||||
failed_count = 0
|
||||
processed_count = 0
|
||||
|
||||
print("Scanning for flat color textures...")
|
||||
|
||||
# Store rename operations to perform them in batch
|
||||
rename_operations = []
|
||||
|
||||
for image in bpy.data.images:
|
||||
processed_count += 1
|
||||
|
||||
# Skip if image has no pixel data
|
||||
if not hasattr(image, 'pixels') or len(image.pixels) == 0:
|
||||
print(f"Skipping '{image.name}': No pixel data available")
|
||||
continue
|
||||
|
||||
# Check if image has flat color
|
||||
is_flat, color = is_flat_color_image(image)
|
||||
|
||||
if is_flat and color:
|
||||
# Convert color to hex
|
||||
hex_color = rgb_to_hex(*color)
|
||||
|
||||
# Store original name for logging
|
||||
original_name = image.name
|
||||
|
||||
# Check if name is already a hex color (to avoid renaming again)
|
||||
if not original_name.startswith('#'):
|
||||
rename_operations.append((image, original_name, hex_color, color))
|
||||
else:
|
||||
print(f"Skipping '{original_name}': Already appears to be hex-named")
|
||||
else:
|
||||
print(f"'{image.name}': Not a flat color texture")
|
||||
|
||||
# Perform rename operations
|
||||
print(f"\nPerforming {len(rename_operations)} rename operation(s)...")
|
||||
|
||||
for image, original_name, hex_color, color in rename_operations:
|
||||
success = safe_rename_image(image, hex_color)
|
||||
if success:
|
||||
print(f"Renamed '{original_name}' to '{hex_color}' (Color: RGBA{color})")
|
||||
renamed_count += 1
|
||||
else:
|
||||
print(f"Failed to rename '{original_name}' to '{hex_color}' - Context restriction")
|
||||
failed_count += 1
|
||||
|
||||
print(f"\nSummary:")
|
||||
print(f"Processed: {processed_count} images")
|
||||
print(f"Successfully renamed: {renamed_count} flat color textures")
|
||||
if failed_count > 0:
|
||||
print(f"Failed to rename: {failed_count} textures (try running from Python Console instead)")
|
||||
|
||||
return renamed_count
|
||||
|
||||
def reload_image_pixels():
|
||||
"""Reload pixel data for all images (useful if images aren't loaded)."""
|
||||
print("Reloading pixel data for all images...")
|
||||
|
||||
for image in bpy.data.images:
|
||||
if image.source == 'FILE' and image.filepath:
|
||||
try:
|
||||
image.reload()
|
||||
print(f"Reloaded: {image.name}")
|
||||
except:
|
||||
print(f"Failed to reload: {image.name}")
|
||||
|
||||
# Alternative function for running in restricted contexts
|
||||
def print_rename_suggestions():
|
||||
"""Print suggested renames without actually renaming (for restricted contexts)."""
|
||||
suggestions = []
|
||||
|
||||
print("Scanning for flat color textures (suggestion mode)...")
|
||||
|
||||
for image in bpy.data.images:
|
||||
if not hasattr(image, 'pixels') or len(image.pixels) == 0:
|
||||
continue
|
||||
|
||||
is_flat, color = is_flat_color_image(image)
|
||||
|
||||
if is_flat and color and not image.name.startswith('#'):
|
||||
hex_color = rgb_to_hex(*color)
|
||||
suggestions.append((image.name, hex_color, color))
|
||||
|
||||
if suggestions:
|
||||
print(f"\nFound {len(suggestions)} flat color texture(s) that could be renamed:")
|
||||
print("-" * 60)
|
||||
for original_name, hex_color, color in suggestions:
|
||||
print(f"'{original_name}' -> '{hex_color}' (RGBA{color})")
|
||||
|
||||
print("\nTo actually rename them, run this script from:")
|
||||
print("1. Blender's Python Console, or")
|
||||
print("2. Command line with: blender file.blend --python script.py")
|
||||
else:
|
||||
print("\nNo flat color textures found that need renaming.")
|
||||
|
||||
# Main execution
|
||||
if __name__ == "__main__":
|
||||
print("=" * 50)
|
||||
print("Flat Color Texture Renamer")
|
||||
print("=" * 50)
|
||||
|
||||
# Optional: Reload images to ensure pixel data is available
|
||||
# Uncomment the line below if you want to force reload all images
|
||||
# reload_image_pixels()
|
||||
|
||||
# Try to run the renaming process
|
||||
try:
|
||||
renamed_count = rename_flat_color_textures()
|
||||
|
||||
if renamed_count > 0:
|
||||
print(f"\nSuccessfully renamed {renamed_count} flat color texture(s)!")
|
||||
else:
|
||||
print("\nNo flat color textures found to rename.")
|
||||
except Exception as e:
|
||||
print(f"\nContext restriction detected. Running in suggestion mode...")
|
||||
print_rename_suggestions()
|
||||
|
||||
print("Script completed.")
|
||||
@@ -1,690 +0,0 @@
|
||||
import bpy
|
||||
|
||||
def safe_wgt_removal():
|
||||
"""Safely remove only WGT widget objects that are clearly ghosts"""
|
||||
|
||||
print("="*80)
|
||||
print("CONSERVATIVE WGT GHOST REMOVAL")
|
||||
print("="*80)
|
||||
|
||||
# Find all WGT objects
|
||||
wgt_objects = []
|
||||
for obj in bpy.data.objects:
|
||||
if obj.name.startswith('WGT-'):
|
||||
wgt_objects.append(obj)
|
||||
|
||||
print(f"Found {len(wgt_objects)} WGT objects")
|
||||
|
||||
# Check which ones are actually being used by armatures
|
||||
used_wgts = set()
|
||||
for armature in bpy.data.armatures:
|
||||
for bone in armature.bones:
|
||||
if bone.use_deform and hasattr(bone, 'custom_shape') and bone.custom_shape:
|
||||
used_wgts.add(bone.custom_shape.name)
|
||||
|
||||
print(f"Found {len(used_wgts)} WGT objects actually used by armatures")
|
||||
|
||||
# Remove unused WGT objects
|
||||
removed_wgts = 0
|
||||
for obj in wgt_objects:
|
||||
if obj.name not in used_wgts:
|
||||
try:
|
||||
# Skip linked objects (they're legitimate library content)
|
||||
if hasattr(obj, 'library') and obj.library is not None:
|
||||
print(f" Skipping linked WGT: {obj.name} (from {obj.library.name})")
|
||||
continue
|
||||
|
||||
# Check if it's in the WGTS collection (typical ghost pattern)
|
||||
in_wgts_collection = False
|
||||
for collection in bpy.data.collections:
|
||||
if 'WGTS' in collection.name and obj in collection.objects.values():
|
||||
in_wgts_collection = True
|
||||
break
|
||||
|
||||
if in_wgts_collection:
|
||||
print(f" Removing unused WGT: {obj.name}")
|
||||
bpy.data.objects.remove(obj, do_unlink=True)
|
||||
removed_wgts += 1
|
||||
except Exception as e:
|
||||
print(f" Failed to remove {obj.name}: {e}")
|
||||
|
||||
print(f"Removed {removed_wgts} unused WGT objects")
|
||||
return removed_wgts
|
||||
|
||||
def is_collection_in_scene_hierarchy(collection, scene_collection):
|
||||
"""Recursively check if a collection exists anywhere in the scene collection hierarchy"""
|
||||
if collection == scene_collection:
|
||||
return True
|
||||
|
||||
for child_collection in scene_collection.children:
|
||||
if child_collection == collection:
|
||||
return True
|
||||
if is_collection_in_scene_hierarchy(collection, child_collection):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def clean_empty_collections():
|
||||
"""Remove empty collections that are not linked to scenes"""
|
||||
|
||||
print("\n" + "="*80)
|
||||
print("CLEANING EMPTY COLLECTIONS")
|
||||
print("="*80)
|
||||
|
||||
removed_collections = 0
|
||||
collections_to_remove = []
|
||||
|
||||
for collection in bpy.data.collections:
|
||||
# Check if collection is empty
|
||||
if len(collection.objects) == 0 and len(collection.children) == 0:
|
||||
# Skip linked collections (they're legitimate library content)
|
||||
if hasattr(collection, 'library') and collection.library is not None:
|
||||
print(f" Skipping linked empty collection: {collection.name}")
|
||||
continue
|
||||
|
||||
# Check if it's anywhere in any scene's collection hierarchy
|
||||
linked_to_scene = False
|
||||
for scene in bpy.data.scenes:
|
||||
if is_collection_in_scene_hierarchy(collection, scene.collection):
|
||||
linked_to_scene = True
|
||||
print(f" Preserving empty collection: {collection.name} (in scene '{scene.name}')")
|
||||
break
|
||||
|
||||
if not linked_to_scene:
|
||||
collections_to_remove.append(collection)
|
||||
|
||||
for collection in collections_to_remove:
|
||||
try:
|
||||
print(f" Removing empty collection: {collection.name}")
|
||||
bpy.data.collections.remove(collection)
|
||||
removed_collections += 1
|
||||
except Exception as e:
|
||||
print(f" Failed to remove collection {collection.name}: {e}")
|
||||
|
||||
print(f"Removed {removed_collections} empty collections")
|
||||
return removed_collections
|
||||
|
||||
def is_object_used_by_scene_instance_collections(obj):
|
||||
"""Check if object is in a collection that's being instanced by objects in scenes"""
|
||||
|
||||
# Find all collections that contain this object
|
||||
obj_collections = []
|
||||
for collection in bpy.data.collections:
|
||||
if obj in collection.objects.values():
|
||||
obj_collections.append(collection)
|
||||
|
||||
if not obj_collections:
|
||||
return False
|
||||
|
||||
# Check if any of these collections are being instanced by objects in scenes
|
||||
for collection in obj_collections:
|
||||
# Find objects that instance this collection
|
||||
for other_obj in bpy.data.objects:
|
||||
if (other_obj.instance_type == 'COLLECTION' and
|
||||
other_obj.instance_collection == collection):
|
||||
|
||||
# Check if the instancing object is in any scene
|
||||
for scene in bpy.data.scenes:
|
||||
if other_obj in scene.objects.values():
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def is_object_legitimate_outside_scene(obj):
|
||||
"""Check if an object has legitimate reasons to exist outside scenes"""
|
||||
|
||||
# WGT objects (rig widgets) are legitimate outside scenes
|
||||
if obj.name.startswith('WGT-'):
|
||||
return True
|
||||
|
||||
# Collection instance objects (linked collection references) are legitimate
|
||||
if obj.instance_type == 'COLLECTION' and obj.instance_collection is not None:
|
||||
return True
|
||||
|
||||
# Objects that are being used by instance collections in scenes are legitimate
|
||||
if is_object_used_by_scene_instance_collections(obj):
|
||||
return True
|
||||
|
||||
# Objects used as curve modifiers, constraints targets, etc.
|
||||
# Check if object is used by modifiers on other objects that are in scenes
|
||||
for other_obj in bpy.data.objects:
|
||||
# Check if the other object is in any scene
|
||||
in_scene = False
|
||||
for scene in bpy.data.scenes:
|
||||
if other_obj in scene.objects.values():
|
||||
in_scene = True
|
||||
break
|
||||
|
||||
if in_scene:
|
||||
for modifier in other_obj.modifiers:
|
||||
if hasattr(modifier, 'object') and modifier.object == obj:
|
||||
return True
|
||||
if hasattr(modifier, 'target') and modifier.target == obj:
|
||||
return True
|
||||
|
||||
# Check if object is used by constraints on other objects that are in scenes
|
||||
for other_obj in bpy.data.objects:
|
||||
# Check if the other object is in any scene
|
||||
in_scene = False
|
||||
for scene in bpy.data.scenes:
|
||||
if other_obj in scene.objects.values():
|
||||
in_scene = True
|
||||
break
|
||||
|
||||
if in_scene:
|
||||
for constraint in other_obj.constraints:
|
||||
if hasattr(constraint, 'target') and constraint.target == obj:
|
||||
return True
|
||||
if hasattr(constraint, 'subtarget') and constraint.subtarget == obj.name:
|
||||
return True
|
||||
|
||||
# Check if object is used in particle systems on objects that are in scenes
|
||||
for other_obj in bpy.data.objects:
|
||||
# Check if the other object is in any scene
|
||||
in_scene = False
|
||||
for scene in bpy.data.scenes:
|
||||
if other_obj in scene.objects.values():
|
||||
in_scene = True
|
||||
break
|
||||
|
||||
if in_scene:
|
||||
for modifier in other_obj.modifiers:
|
||||
if modifier.type == 'PARTICLE_SYSTEM':
|
||||
settings = modifier.particle_system.settings
|
||||
if hasattr(settings, 'object') and settings.object == obj:
|
||||
return True
|
||||
if hasattr(settings, 'instance_object') and settings.instance_object == obj:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def clean_object_ghosts(delete_low_priority=False):
|
||||
"""Remove objects that are not in any scene and have no legitimate purpose (potential ghosts)"""
|
||||
|
||||
print("\n" + "="*80)
|
||||
print("OBJECT GHOST CLEANUP")
|
||||
print("="*80)
|
||||
|
||||
# Get all objects, excluding cameras and lights by default (they're often not in scenes for good reasons)
|
||||
candidate_objects = [obj for obj in bpy.data.objects if obj.type not in ['CAMERA', 'LIGHT']]
|
||||
|
||||
if not candidate_objects:
|
||||
print("No candidate objects found")
|
||||
return 0
|
||||
|
||||
print(f"Found {len(candidate_objects)} candidate objects")
|
||||
|
||||
removed_objects = 0
|
||||
ghosts_to_remove = []
|
||||
|
||||
for obj in candidate_objects:
|
||||
# Skip linked objects (they're legitimate library content)
|
||||
if hasattr(obj, 'library') and obj.library is not None:
|
||||
continue
|
||||
|
||||
# Check which scenes contain it
|
||||
in_scenes = []
|
||||
for scene in bpy.data.scenes:
|
||||
if obj in scene.objects.values():
|
||||
in_scenes.append(scene.name)
|
||||
|
||||
# If not in any scene, check if it has legitimate reasons to exist
|
||||
if len(in_scenes) == 0:
|
||||
if is_object_legitimate_outside_scene(obj):
|
||||
print(f" Preserving object: {obj.name} (legitimate use outside scene)")
|
||||
continue
|
||||
|
||||
# If not legitimate, it's a ghost - but be conservative with low user count objects
|
||||
should_remove = False
|
||||
removal_reason = ""
|
||||
|
||||
if obj.users >= 2:
|
||||
# Higher user count ghosts are definitely safe to remove
|
||||
should_remove = True
|
||||
removal_reason = "ghost (users >= 2, no legitimate use found)"
|
||||
elif obj.users < 2 and delete_low_priority:
|
||||
# Low user count ghosts only if user enables the option
|
||||
should_remove = True
|
||||
removal_reason = "low priority ghost (users < 2, no legitimate use found)"
|
||||
elif obj.users < 2:
|
||||
print(f" Skipping low priority object: {obj.name} (users < 2, enable 'Delete Low Priority' to remove)")
|
||||
|
||||
if should_remove:
|
||||
ghosts_to_remove.append(obj)
|
||||
print(f" Marking ghost for removal: {obj.name} (type: {obj.type}) - {removal_reason}")
|
||||
|
||||
# Remove the ghost objects
|
||||
for obj in ghosts_to_remove:
|
||||
try:
|
||||
print(f" Removing object ghost: {obj.name}")
|
||||
bpy.data.objects.remove(obj, do_unlink=True)
|
||||
removed_objects += 1
|
||||
except Exception as e:
|
||||
print(f" Failed to remove object {obj.name}: {e}")
|
||||
|
||||
print(f"Removed {removed_objects} ghost objects")
|
||||
return removed_objects
|
||||
|
||||
def manual_object_analysis():
|
||||
"""Manual analysis of objects - show info but don't auto-remove"""
|
||||
|
||||
print("\n" + "="*80)
|
||||
print("OBJECT GHOST ANALYSIS (MANUAL REVIEW)")
|
||||
print("="*80)
|
||||
|
||||
# Get all objects, excluding cameras and lights (they're often legitimately not in scenes)
|
||||
candidate_objects = [obj for obj in bpy.data.objects if obj.type not in ['CAMERA', 'LIGHT']]
|
||||
|
||||
# Filter to only objects not in scenes for analysis
|
||||
objects_not_in_scenes = []
|
||||
for obj in candidate_objects:
|
||||
# Skip linked objects for analysis
|
||||
if hasattr(obj, 'library') and obj.library is not None:
|
||||
continue
|
||||
|
||||
# Check which scenes contain it
|
||||
in_scenes = []
|
||||
for scene in bpy.data.scenes:
|
||||
if obj in scene.objects.values():
|
||||
in_scenes.append(scene.name)
|
||||
|
||||
if len(in_scenes) == 0:
|
||||
objects_not_in_scenes.append(obj)
|
||||
|
||||
if not objects_not_in_scenes:
|
||||
print("No local objects found outside scenes")
|
||||
return
|
||||
|
||||
print(f"Found {len(objects_not_in_scenes)} local objects not in any scene:")
|
||||
|
||||
for obj in objects_not_in_scenes:
|
||||
print(f"\n Object: {obj.name} (type: {obj.type})")
|
||||
print(f" Users: {obj.users}")
|
||||
print(f" Parent: {obj.parent.name if obj.parent else 'None'}")
|
||||
|
||||
# Check collections
|
||||
in_collections = []
|
||||
for collection in bpy.data.collections:
|
||||
if obj in collection.objects.values():
|
||||
in_collections.append(collection.name)
|
||||
print(f" In collections: {in_collections}")
|
||||
|
||||
# Show recommendation
|
||||
if is_object_legitimate_outside_scene(obj):
|
||||
print(f" -> LEGITIMATE: Has valid use outside scenes")
|
||||
elif obj.users >= 2:
|
||||
print(f" -> GHOST: No legitimate use found, users >= 2 (will be removed)")
|
||||
elif obj.users < 2:
|
||||
print(f" -> LOW PRIORITY: No legitimate use found, users < 2 (needs option enabled)")
|
||||
else:
|
||||
print(f" -> UNCLEAR: Manual review needed")
|
||||
|
||||
def main(delete_low_priority=False):
|
||||
"""Main conservative cleanup function"""
|
||||
|
||||
print("CONSERVATIVE GHOST DATA CLEANUP")
|
||||
print("="*80)
|
||||
print("This script removes:")
|
||||
print("1. Unused local WGT widget objects")
|
||||
print("2. Empty unlinked collections")
|
||||
print("3. Objects not in any scene with no legitimate use")
|
||||
if delete_low_priority:
|
||||
print(" - Including low priority ghosts (no legitimate use, users < 2)")
|
||||
else:
|
||||
print(" - Excluding low priority ghosts (no legitimate use, users < 2)")
|
||||
print("="*80)
|
||||
|
||||
initial_objects = len(list(bpy.data.objects))
|
||||
initial_collections = len(list(bpy.data.collections))
|
||||
|
||||
# Safe operations only
|
||||
wgts_removed = safe_wgt_removal()
|
||||
collections_removed = clean_empty_collections()
|
||||
object_ghosts_removed = clean_object_ghosts(delete_low_priority)
|
||||
|
||||
# Show remaining object analysis
|
||||
manual_object_analysis()
|
||||
|
||||
# Final purge
|
||||
print("\n" + "="*80)
|
||||
print("FINAL SAFE PURGE")
|
||||
print("="*80)
|
||||
|
||||
try:
|
||||
bpy.ops.outliner.orphans_purge(do_local_ids=True, do_linked_ids=True, do_recursive=True)
|
||||
print("Safe purge completed")
|
||||
except:
|
||||
print("Purge had issues")
|
||||
|
||||
final_objects = len(list(bpy.data.objects))
|
||||
final_collections = len(list(bpy.data.collections))
|
||||
|
||||
print(f"\n" + "="*80)
|
||||
print("CONSERVATIVE CLEANUP SUMMARY")
|
||||
print("="*80)
|
||||
print(f"Objects: {initial_objects} -> {final_objects} (removed {initial_objects - final_objects})")
|
||||
print(f"Collections: {initial_collections} -> {final_collections} (removed {collections_removed})")
|
||||
print(f"WGT objects removed: {wgts_removed}")
|
||||
print(f"Object ghosts removed: {object_ghosts_removed}")
|
||||
print("="*80)
|
||||
|
||||
class GhostBuster(bpy.types.Operator):
|
||||
"""Conservative cleanup of ghost data (unused WGT objects, empty collections)"""
|
||||
bl_idname = "bst.ghost_buster"
|
||||
bl_label = "Ghost Buster"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
try:
|
||||
# Get the delete low priority setting from scene properties
|
||||
delete_low_priority = getattr(context.scene, "ghost_buster_delete_low_priority", False)
|
||||
|
||||
# Call the main ghost buster function
|
||||
main(delete_low_priority)
|
||||
self.report({'INFO'}, "Ghost data cleanup completed")
|
||||
return {'FINISHED'}
|
||||
except Exception as e:
|
||||
self.report({'ERROR'}, f"Ghost buster failed: {str(e)}")
|
||||
return {'CANCELLED'}
|
||||
|
||||
class GhostDetector(bpy.types.Operator):
|
||||
"""Detect and analyze ghost data without removing it"""
|
||||
bl_idname = "bst.ghost_detector"
|
||||
bl_label = "Ghost Detector"
|
||||
bl_options = {'REGISTER', 'INTERNAL'}
|
||||
|
||||
# Properties to store analysis data
|
||||
total_wgt_objects: bpy.props.IntProperty(default=0)
|
||||
unused_wgt_objects: bpy.props.IntProperty(default=0)
|
||||
used_wgt_objects: bpy.props.IntProperty(default=0)
|
||||
empty_collections: bpy.props.IntProperty(default=0)
|
||||
ghost_objects: bpy.props.IntProperty(default=0)
|
||||
ghost_potential: bpy.props.IntProperty(default=0)
|
||||
ghost_legitimate: bpy.props.IntProperty(default=0)
|
||||
ghost_low_priority: bpy.props.IntProperty(default=0)
|
||||
wgt_details: bpy.props.StringProperty(default="")
|
||||
collection_details: bpy.props.StringProperty(default="")
|
||||
ghost_details: bpy.props.StringProperty(default="")
|
||||
|
||||
def analyze_ghost_data(self):
|
||||
"""Analyze ghost data similar to ghost_buster functions"""
|
||||
|
||||
# Analyze WGT objects
|
||||
wgt_objects = []
|
||||
for obj in bpy.data.objects:
|
||||
if obj.name.startswith('WGT-'):
|
||||
wgt_objects.append(obj)
|
||||
|
||||
self.total_wgt_objects = len(wgt_objects)
|
||||
|
||||
# Check which WGT objects are used by armatures
|
||||
used_wgts = set()
|
||||
for armature in bpy.data.armatures:
|
||||
for bone in armature.bones:
|
||||
if bone.use_deform and hasattr(bone, 'custom_shape') and bone.custom_shape:
|
||||
used_wgts.add(bone.custom_shape.name)
|
||||
|
||||
self.used_wgt_objects = len(used_wgts)
|
||||
|
||||
# Count unused WGT objects
|
||||
unused_wgts = []
|
||||
wgt_details_list = []
|
||||
for obj in wgt_objects:
|
||||
if obj.name not in used_wgts:
|
||||
# Skip linked objects (they're legitimate library content)
|
||||
if hasattr(obj, 'library') and obj.library is not None:
|
||||
continue
|
||||
|
||||
# Check if it's in the WGTS collection (typical ghost pattern)
|
||||
in_wgts_collection = False
|
||||
for collection in bpy.data.collections:
|
||||
if 'WGTS' in collection.name and obj in collection.objects.values():
|
||||
in_wgts_collection = True
|
||||
break
|
||||
|
||||
if in_wgts_collection:
|
||||
unused_wgts.append(obj)
|
||||
wgt_details_list.append(f"• {obj.name} (in WGTS collection)")
|
||||
|
||||
self.unused_wgt_objects = len(unused_wgts)
|
||||
self.wgt_details = "\n".join(wgt_details_list[:10]) # Limit to first 10
|
||||
if len(unused_wgts) > 10:
|
||||
self.wgt_details += f"\n... and {len(unused_wgts) - 10} more"
|
||||
|
||||
# Analyze empty collections
|
||||
empty_collections = []
|
||||
collection_details_list = []
|
||||
for collection in bpy.data.collections:
|
||||
if len(collection.objects) == 0 and len(collection.children) == 0:
|
||||
# Skip linked collections (they're legitimate library content)
|
||||
if hasattr(collection, 'library') and collection.library is not None:
|
||||
continue
|
||||
|
||||
# Check if it's anywhere in any scene's collection hierarchy
|
||||
linked_to_scene = False
|
||||
for scene in bpy.data.scenes:
|
||||
if is_collection_in_scene_hierarchy(collection, scene.collection):
|
||||
linked_to_scene = True
|
||||
break
|
||||
|
||||
if not linked_to_scene:
|
||||
empty_collections.append(collection)
|
||||
collection_details_list.append(f"• {collection.name}")
|
||||
|
||||
self.empty_collections = len(empty_collections)
|
||||
self.collection_details = "\n".join(collection_details_list[:10]) # Limit to first 10
|
||||
if len(empty_collections) > 10:
|
||||
self.collection_details += f"\n... and {len(empty_collections) - 10} more"
|
||||
|
||||
# Analyze ghost objects (objects not in scenes)
|
||||
candidate_objects = [obj for obj in bpy.data.objects if obj.type not in ['CAMERA', 'LIGHT']]
|
||||
|
||||
potential_ghosts = 0
|
||||
legitimate = 0
|
||||
low_priority = 0
|
||||
ghost_details_list = []
|
||||
|
||||
for obj in candidate_objects:
|
||||
# Skip linked objects (they're legitimate library content)
|
||||
if hasattr(obj, 'library') and obj.library is not None:
|
||||
continue
|
||||
|
||||
# Check which scenes contain it
|
||||
in_scenes = []
|
||||
for scene in bpy.data.scenes:
|
||||
if obj in scene.objects.values():
|
||||
in_scenes.append(scene.name)
|
||||
|
||||
# Only analyze objects not in scenes
|
||||
if len(in_scenes) == 0:
|
||||
# Classify object
|
||||
status = ""
|
||||
if is_object_legitimate_outside_scene(obj):
|
||||
legitimate += 1
|
||||
status = "LEGITIMATE (has valid use outside scenes)"
|
||||
elif obj.users >= 2:
|
||||
potential_ghosts += 1
|
||||
status = "GHOST (no legitimate use found, users >= 2)"
|
||||
elif obj.users < 2:
|
||||
low_priority += 1
|
||||
status = "LOW PRIORITY (no legitimate use found, users < 2)"
|
||||
else:
|
||||
status = "UNCLEAR"
|
||||
|
||||
ghost_details_list.append(f"• {obj.name} ({obj.type}): {status}")
|
||||
|
||||
self.ghost_objects = len([obj for obj in candidate_objects if len([s for s in bpy.data.scenes if obj in s.objects.values()]) == 0 and not (hasattr(obj, 'library') and obj.library is not None)])
|
||||
self.ghost_potential = potential_ghosts
|
||||
self.ghost_legitimate = legitimate
|
||||
self.ghost_low_priority = low_priority
|
||||
self.ghost_details = "\n".join(ghost_details_list[:10]) # Limit to first 10
|
||||
if len(ghost_details_list) > 10:
|
||||
self.ghost_details += f"\n... and {len(ghost_details_list) - 10} more"
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Title
|
||||
layout.label(text="Ghost Data Analysis", icon='GHOST_ENABLED')
|
||||
layout.separator()
|
||||
|
||||
# WGT Objects section
|
||||
box = layout.box()
|
||||
box.label(text="WGT Widget Objects", icon='ARMATURE_DATA')
|
||||
col = box.column(align=True)
|
||||
col.label(text=f"Total WGT objects: {self.total_wgt_objects}")
|
||||
col.label(text=f"Used by armatures: {self.used_wgt_objects}", icon='CHECKMARK')
|
||||
if self.unused_wgt_objects > 0:
|
||||
col.label(text=f"Unused (potential ghosts): {self.unused_wgt_objects}", icon='ERROR')
|
||||
if self.wgt_details:
|
||||
box.separator()
|
||||
details_col = box.column(align=True)
|
||||
for line in self.wgt_details.split('\n'):
|
||||
if line.strip():
|
||||
details_col.label(text=line)
|
||||
else:
|
||||
col.label(text="No unused WGT objects found", icon='CHECKMARK')
|
||||
|
||||
# Empty Collections section
|
||||
box = layout.box()
|
||||
box.label(text="Empty Collections", icon='OUTLINER_COLLECTION')
|
||||
col = box.column(align=True)
|
||||
if self.empty_collections > 0:
|
||||
col.label(text=f"Empty unlinked collections: {self.empty_collections}", icon='ERROR')
|
||||
if self.collection_details:
|
||||
box.separator()
|
||||
details_col = box.column(align=True)
|
||||
for line in self.collection_details.split('\n'):
|
||||
if line.strip():
|
||||
details_col.label(text=line)
|
||||
else:
|
||||
col.label(text="No empty unlinked collections found", icon='CHECKMARK')
|
||||
|
||||
# Ghost Objects section
|
||||
box = layout.box()
|
||||
box.label(text="Ghost Objects Analysis", icon='OBJECT_DATA')
|
||||
col = box.column(align=True)
|
||||
col.label(text=f"Objects not in scenes: {self.ghost_objects}")
|
||||
if self.ghost_objects > 0:
|
||||
if self.ghost_potential > 0:
|
||||
col.label(text=f"Ghosts (users >= 2): {self.ghost_potential}", icon='ERROR')
|
||||
if self.ghost_legitimate > 0:
|
||||
col.label(text=f"Legitimate objects: {self.ghost_legitimate}", icon='CHECKMARK')
|
||||
if self.ghost_low_priority > 0:
|
||||
col.label(text=f"Low priority (users < 2): {self.ghost_low_priority}", icon='QUESTION')
|
||||
|
||||
if self.ghost_details:
|
||||
box.separator()
|
||||
details_col = box.column(align=True)
|
||||
for line in self.ghost_details.split('\n'):
|
||||
if line.strip():
|
||||
details_col.label(text=line)
|
||||
else:
|
||||
col.label(text="No ghost objects found", icon='CHECKMARK')
|
||||
|
||||
# Summary
|
||||
layout.separator()
|
||||
summary_box = layout.box()
|
||||
summary_box.label(text="Summary", icon='INFO')
|
||||
total_issues = self.unused_wgt_objects + self.empty_collections + self.ghost_potential
|
||||
if total_issues > 0:
|
||||
summary_box.label(text=f"Found {total_issues} ghost data issues that will be removed", icon='ERROR')
|
||||
if self.ghost_low_priority > 0:
|
||||
summary_box.label(text=f"+ {self.ghost_low_priority} low priority issues (optional)", icon='QUESTION')
|
||||
summary_box.label(text="Use Ghost Buster to clean up safely")
|
||||
else:
|
||||
summary_box.label(text="No ghost data issues detected!", icon='CHECKMARK')
|
||||
if self.ghost_low_priority > 0:
|
||||
summary_box.label(text=f"({self.ghost_low_priority} low priority issues available)", icon='INFO')
|
||||
|
||||
def execute(self, context):
|
||||
return {'FINISHED'}
|
||||
|
||||
def invoke(self, context, event):
|
||||
# Analyze the ghost data before showing the dialog
|
||||
self.analyze_ghost_data()
|
||||
return context.window_manager.invoke_popup(self, width=500)
|
||||
|
||||
class ResyncEnforce(bpy.types.Operator):
|
||||
"""Resync Enforce: Fix broken library override hierarchies by rebuilding from linked references"""
|
||||
bl_idname = "bst.resync_enforce"
|
||||
bl_label = "Resync Enforce"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
@classmethod
|
||||
def poll(cls, context):
|
||||
# Only available if there are selected objects
|
||||
return context.selected_objects
|
||||
|
||||
def execute(self, context):
|
||||
# Get selected objects
|
||||
selected_objects = context.selected_objects.copy()
|
||||
|
||||
if not selected_objects:
|
||||
self.report({'WARNING'}, "No objects selected for resync enforce")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# Count library override objects
|
||||
override_objects = []
|
||||
for obj in selected_objects:
|
||||
if obj.override_library:
|
||||
override_objects.append(obj)
|
||||
|
||||
if not override_objects:
|
||||
self.report({'WARNING'}, "No library override objects found in selection")
|
||||
return {'CANCELLED'}
|
||||
|
||||
try:
|
||||
# Store the current selection
|
||||
original_selection = set(context.selected_objects)
|
||||
|
||||
# Select only the override objects
|
||||
bpy.ops.object.select_all(action='DESELECT')
|
||||
for obj in override_objects:
|
||||
obj.select_set(True)
|
||||
|
||||
# Call Blender's resync enforce operation
|
||||
result = bpy.ops.object.library_override_operation(
|
||||
'INVOKE_DEFAULT',
|
||||
type='OVERRIDE_LIBRARY_RESYNC_HIERARCHY_ENFORCE',
|
||||
selection_set='SELECTED'
|
||||
)
|
||||
|
||||
if result == {'FINISHED'}:
|
||||
self.report({'INFO'}, f"Resync enforce completed on {len(override_objects)} override objects")
|
||||
return_code = {'FINISHED'}
|
||||
else:
|
||||
self.report({'WARNING'}, "Resync enforce operation was cancelled or failed")
|
||||
return_code = {'CANCELLED'}
|
||||
|
||||
# Restore original selection
|
||||
bpy.ops.object.select_all(action='DESELECT')
|
||||
for obj in original_selection:
|
||||
if obj.name in bpy.data.objects: # Check if object still exists
|
||||
obj.select_set(True)
|
||||
|
||||
return return_code
|
||||
|
||||
except Exception as e:
|
||||
self.report({'ERROR'}, f"Resync enforce failed: {str(e)}")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# Note: main() is called by the operator, not automatically
|
||||
|
||||
# List of classes to register
|
||||
classes = (
|
||||
GhostBuster,
|
||||
GhostDetector,
|
||||
ResyncEnforce,
|
||||
)
|
||||
|
||||
def register():
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
|
||||
def unregister():
|
||||
for cls in reversed(classes):
|
||||
try:
|
||||
bpy.utils.unregister_class(cls)
|
||||
except RuntimeError:
|
||||
pass
|
||||
@@ -1,63 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class RemoveCustomSplitNormals(bpy.types.Operator):
|
||||
"""Remove custom split normals and apply smooth shading to all accessible mesh objects"""
|
||||
bl_idname = "bst.remove_custom_split_normals"
|
||||
bl_label = "Remove Custom Split Normals"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
only_selected: bpy.props.BoolProperty(
|
||||
name="Only Selected Objects",
|
||||
description="Apply only to selected objects",
|
||||
default=True
|
||||
)
|
||||
|
||||
def execute(self, context):
|
||||
# Store the current context
|
||||
original_active = context.active_object
|
||||
original_selected = context.selected_objects.copy()
|
||||
original_mode = context.mode
|
||||
|
||||
# Get object names that are in the current view layer
|
||||
view_layer_object_names = set(context.view_layer.objects.keys())
|
||||
|
||||
# Choose objects based on the property
|
||||
if self.only_selected:
|
||||
objects = [obj for obj in context.selected_objects if obj.type == 'MESH' and obj.name in view_layer_object_names]
|
||||
else:
|
||||
objects = [obj for obj in bpy.data.objects if obj.type == 'MESH' and obj.name in view_layer_object_names]
|
||||
|
||||
processed_count = 0
|
||||
for obj in objects:
|
||||
mesh = obj.data
|
||||
if mesh.has_custom_normals:
|
||||
# Select and make active
|
||||
obj.select_set(True)
|
||||
context.view_layer.objects.active = obj
|
||||
bpy.ops.object.mode_set(mode='EDIT')
|
||||
bpy.ops.mesh.customdata_custom_splitnormals_clear()
|
||||
bpy.ops.object.mode_set(mode='OBJECT')
|
||||
bpy.ops.object.shade_smooth()
|
||||
obj.select_set(False)
|
||||
processed_count += 1
|
||||
self.report({'INFO'}, f"Removed custom split normals and applied smooth shading to: {obj.name}")
|
||||
|
||||
# Restore original selection and active object
|
||||
context.view_layer.objects.active = original_active
|
||||
for obj in original_selected:
|
||||
if obj.name in view_layer_object_names:
|
||||
obj.select_set(True)
|
||||
|
||||
self.report({'INFO'}, f"Done: custom split normals removed and smooth shading applied to {'selected' if self.only_selected else 'all'} mesh objects. ({processed_count} processed)")
|
||||
return {'FINISHED'}
|
||||
|
||||
# Registration
|
||||
def register():
|
||||
bpy.utils.register_class(MESH_OT_RemoveCustomSplitNormals)
|
||||
|
||||
def unregister():
|
||||
bpy.utils.unregister_class(MESH_OT_RemoveCustomSplitNormals)
|
||||
|
||||
# Only run if this script is run directly
|
||||
if __name__ == "__main__":
|
||||
register()
|
||||
@@ -1,57 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class RemoveUnusedMaterialSlots(bpy.types.Operator):
|
||||
"""Remove unused material slots from all mesh objects"""
|
||||
bl_idname = "bst.remove_unused_material_slots"
|
||||
bl_label = "Remove Unused Material Slots"
|
||||
bl_description = "Remove unused material slots from all mesh objects in the scene"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def execute(self, context):
|
||||
processed_objects = 0
|
||||
|
||||
# Store original active object and selection
|
||||
original_active = context.view_layer.objects.active
|
||||
original_selection = [obj for obj in context.selected_objects]
|
||||
|
||||
try:
|
||||
# Remove unused material slots from all mesh objects
|
||||
for obj in bpy.data.objects:
|
||||
if obj.type == 'MESH' and obj.material_slots and obj.library is None:
|
||||
# Temporarily ensure object is in view layer by linking to master collection
|
||||
was_linked = False
|
||||
if obj.name not in context.view_layer.objects:
|
||||
context.scene.collection.objects.link(obj)
|
||||
was_linked = True
|
||||
|
||||
# Store original selection state
|
||||
original_obj_selection = obj.select_get()
|
||||
|
||||
# Select the object and make it active
|
||||
obj.select_set(True)
|
||||
context.view_layer.objects.active = obj
|
||||
|
||||
# Remove unused material slots
|
||||
bpy.ops.object.material_slot_remove_unused()
|
||||
processed_objects += 1
|
||||
|
||||
# Restore original selection state
|
||||
obj.select_set(original_obj_selection)
|
||||
|
||||
# Unlink if we linked it
|
||||
if was_linked:
|
||||
context.scene.collection.objects.unlink(obj)
|
||||
|
||||
finally:
|
||||
# Restore original active object and selection
|
||||
context.view_layer.objects.active = original_active
|
||||
# Clear all selections first
|
||||
for obj in context.selected_objects:
|
||||
obj.select_set(False)
|
||||
# Restore original selection
|
||||
for obj in original_selection:
|
||||
if obj.name in context.view_layer.objects:
|
||||
obj.select_set(True)
|
||||
|
||||
self.report({'INFO'}, f"Removed unused material slots from {processed_objects} mesh objects")
|
||||
return {'FINISHED'}
|
||||
@@ -1,100 +0,0 @@
|
||||
import bpy
|
||||
|
||||
def find_node_distance_to_basecolor(node, visited=None):
|
||||
"""Find the shortest path distance from a node to any Base Color input"""
|
||||
if visited is None:
|
||||
visited = set()
|
||||
|
||||
if node in visited:
|
||||
return float('inf')
|
||||
|
||||
visited.add(node)
|
||||
|
||||
# If this is a Principled BSDF node, check if it has a Base Color input
|
||||
if node.type == 'BSDF_PRINCIPLED':
|
||||
for input in node.inputs:
|
||||
if input.name == 'Base Color':
|
||||
# If this input is connected, return 0 (we found our target)
|
||||
if input.links:
|
||||
return 0
|
||||
return float('inf')
|
||||
|
||||
# Check all outputs of this node
|
||||
min_distance = float('inf')
|
||||
for output in node.outputs:
|
||||
for link in output.links:
|
||||
# Recursively check connected nodes
|
||||
distance = find_node_distance_to_basecolor(link.to_node, visited.copy())
|
||||
if distance is not None and distance < min_distance:
|
||||
min_distance = distance + 1
|
||||
|
||||
return min_distance if min_distance != float('inf') else None
|
||||
|
||||
def find_connected_basecolor_texture(node_tree):
|
||||
"""Find any image texture directly connected to a Base Color input"""
|
||||
for node in node_tree.nodes:
|
||||
if node.type == 'BSDF_PRINCIPLED':
|
||||
base_color_input = node.inputs.get('Base Color')
|
||||
if base_color_input and base_color_input.links:
|
||||
# Get the node connected to Base Color
|
||||
connected_node = base_color_input.links[0].from_node
|
||||
# If it's an image texture, return it
|
||||
if connected_node.type == 'TEX_IMAGE' and connected_node.image:
|
||||
return connected_node
|
||||
return None
|
||||
|
||||
def select_diffuse_nodes():
|
||||
# Get all materials in the blend file
|
||||
materials = bpy.data.materials
|
||||
|
||||
# Counter for found nodes
|
||||
found_nodes = 0
|
||||
|
||||
# Keywords to look for in image names (case insensitive)
|
||||
keywords = ['diffuse', 'basecolor', 'base_color', 'albedo', 'color']
|
||||
|
||||
# Iterate through all materials
|
||||
for material in materials:
|
||||
# Skip materials without node trees
|
||||
if not material.use_nodes:
|
||||
continue
|
||||
|
||||
node_tree = material.node_tree
|
||||
|
||||
# First, try to find any image texture connected to Base Color
|
||||
base_color_texture = find_connected_basecolor_texture(node_tree)
|
||||
if base_color_texture:
|
||||
node_tree.nodes.active = base_color_texture
|
||||
base_color_texture.select = True
|
||||
found_nodes += 1
|
||||
print(f"Selected Base Color connected texture '{base_color_texture.image.name}' in material: {material.name}")
|
||||
continue
|
||||
|
||||
# If no direct connection found, fall back to name-based search
|
||||
matching_nodes = []
|
||||
for node in node_tree.nodes:
|
||||
if node.type == 'TEX_IMAGE' and node.image:
|
||||
# Check if the image name contains any of our keywords
|
||||
image_name = node.image.name.lower()
|
||||
if any(keyword in image_name for keyword in keywords):
|
||||
# Calculate distance to Base Color input
|
||||
distance = find_node_distance_to_basecolor(node)
|
||||
if distance is not None:
|
||||
matching_nodes.append((node, distance))
|
||||
|
||||
# If we found any matching nodes, select the one with the shortest distance
|
||||
if matching_nodes:
|
||||
# Sort by distance (closest to Base Color first)
|
||||
matching_nodes.sort(key=lambda x: x[1])
|
||||
selected_node = matching_nodes[0][0]
|
||||
|
||||
node_tree.nodes.active = selected_node
|
||||
selected_node.select = True
|
||||
found_nodes += 1
|
||||
print(f"Selected named texture '{selected_node.image.name}' in material: {material.name} (distance to Base Color: {matching_nodes[0][1]})")
|
||||
|
||||
print(f"\nTotal texture nodes selected: {found_nodes}")
|
||||
|
||||
# Only run if this script is run directly
|
||||
if __name__ == "__main__":
|
||||
select_diffuse_nodes()
|
||||
@@ -1,100 +0,0 @@
|
||||
import bpy
|
||||
|
||||
class SpawnSceneStructure(bpy.types.Operator):
|
||||
"""Create a standard scene collection structure: Env, Animation, Lgt with subcollections"""
|
||||
bl_idname = "bst.spawn_scene_structure"
|
||||
bl_label = "Spawn Scene Structure"
|
||||
bl_options = {'REGISTER', 'UNDO'}
|
||||
|
||||
def find_layer_collection(self, layer_collection, collection_name):
|
||||
"""Recursively find a layer collection by name"""
|
||||
if layer_collection.collection.name == collection_name:
|
||||
return layer_collection
|
||||
|
||||
for child in layer_collection.children:
|
||||
result = self.find_layer_collection(child, collection_name)
|
||||
if result:
|
||||
return result
|
||||
return None
|
||||
|
||||
def execute(self, context):
|
||||
scene = context.scene
|
||||
scene_collection = scene.collection
|
||||
|
||||
# Define the structure to create
|
||||
structure = {
|
||||
"Env": ["ROOTS", "Dressing"],
|
||||
"Animation": ["Cam", "Char"],
|
||||
"Lgt": []
|
||||
}
|
||||
|
||||
created_collections = []
|
||||
skipped_collections = []
|
||||
|
||||
try:
|
||||
for main_collection_name, subcollections in structure.items():
|
||||
# Check if main collection already exists
|
||||
main_collection = None
|
||||
for existing_collection in scene_collection.children:
|
||||
if existing_collection.name == main_collection_name:
|
||||
main_collection = existing_collection
|
||||
skipped_collections.append(main_collection_name)
|
||||
break
|
||||
|
||||
# Create main collection if it doesn't exist
|
||||
if main_collection is None:
|
||||
main_collection = bpy.data.collections.new(main_collection_name)
|
||||
scene_collection.children.link(main_collection)
|
||||
created_collections.append(main_collection_name)
|
||||
|
||||
# Create subcollections
|
||||
for subcollection_name in subcollections:
|
||||
# Check if subcollection already exists
|
||||
subcollection_exists = False
|
||||
existing_subcollection = None
|
||||
for sub in main_collection.children:
|
||||
if sub.name == subcollection_name:
|
||||
subcollection_exists = True
|
||||
existing_subcollection = sub
|
||||
skipped_collections.append(f"{main_collection_name}/{subcollection_name}")
|
||||
break
|
||||
|
||||
# Create subcollection if it doesn't exist
|
||||
if not subcollection_exists:
|
||||
subcollection = bpy.data.collections.new(subcollection_name)
|
||||
main_collection.children.link(subcollection)
|
||||
created_collections.append(f"{main_collection_name}/{subcollection_name}")
|
||||
|
||||
# Apply special settings to ROOTS collection
|
||||
if subcollection_name == "ROOTS":
|
||||
subcollection.hide_viewport = True # Hide in all viewports
|
||||
# Exclude from view layer
|
||||
view_layer = context.view_layer
|
||||
layer_collection = self.find_layer_collection(view_layer.layer_collection, subcollection_name)
|
||||
if layer_collection:
|
||||
layer_collection.exclude = True
|
||||
else:
|
||||
# Apply settings to existing ROOTS collection if it wasn't properly configured
|
||||
if subcollection_name == "ROOTS" and existing_subcollection:
|
||||
existing_subcollection.hide_viewport = True
|
||||
view_layer = context.view_layer
|
||||
layer_collection = self.find_layer_collection(view_layer.layer_collection, subcollection_name)
|
||||
if layer_collection:
|
||||
layer_collection.exclude = True
|
||||
|
||||
# Report results
|
||||
if created_collections:
|
||||
created_list = ", ".join(created_collections)
|
||||
if skipped_collections:
|
||||
skipped_list = ", ".join(skipped_collections)
|
||||
self.report({'INFO'}, f"Created: {created_list}. Skipped existing: {skipped_list}")
|
||||
else:
|
||||
self.report({'INFO'}, f"Created scene structure: {created_list}")
|
||||
else:
|
||||
self.report({'INFO'}, "Scene structure already exists - no collections created")
|
||||
|
||||
return {'FINISHED'}
|
||||
|
||||
except Exception as e:
|
||||
self.report({'ERROR'}, f"Failed to create scene structure: {str(e)}")
|
||||
return {'CANCELLED'}
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -1,104 +0,0 @@
|
||||
import bpy
|
||||
from ..ops.NoSubdiv import NoSubdiv
|
||||
from ..ops.remove_custom_split_normals import RemoveCustomSplitNormals
|
||||
from ..ops.create_ortho_camera import CreateOrthoCamera
|
||||
from ..ops.spawn_scene_structure import SpawnSceneStructure
|
||||
from ..ops.delete_single_keyframe_actions import DeleteSingleKeyframeActions
|
||||
from ..ops.find_material_users import FindMaterialUsers, MATERIAL_USERS_OT_summary_dialog
|
||||
from ..ops.remove_unused_material_slots import RemoveUnusedMaterialSlots
|
||||
from ..ops.convert_relations_to_constraint import ConvertRelationsToConstraint
|
||||
|
||||
class BulkSceneGeneral(bpy.types.Panel):
|
||||
"""Bulk Scene General Panel"""
|
||||
bl_label = "Scene General"
|
||||
bl_idname = "VIEW3D_PT_bulk_scene_general"
|
||||
bl_space_type = 'VIEW_3D'
|
||||
bl_region_type = 'UI'
|
||||
bl_category = 'Edit'
|
||||
bl_parent_id = "VIEW3D_PT_bulk_scene_tools"
|
||||
bl_order = 0 # This will make it appear at the very top of the main panel
|
||||
|
||||
def draw(self, context):
|
||||
layout = self.layout
|
||||
|
||||
# Scene Structure section
|
||||
box = layout.box()
|
||||
box.label(text="Scene Structure")
|
||||
row = box.row()
|
||||
row.scale_y = 1.2
|
||||
row.operator("bst.spawn_scene_structure", text="Spawn Scene Structure", icon='OUTLINER_COLLECTION')
|
||||
|
||||
# Mesh section
|
||||
box = layout.box()
|
||||
box.label(text="Mesh")
|
||||
# Add checkbox for only_selected property
|
||||
row = box.row()
|
||||
row.prop(context.window_manager, "bst_no_subdiv_only_selected", text="Selected Only")
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.no_subdiv", text="No Subdiv", icon='MOD_SUBSURF').only_selected = context.window_manager.bst_no_subdiv_only_selected
|
||||
row.operator("bst.remove_custom_split_normals", text="Remove Custom Split Normals", icon='X').only_selected = context.window_manager.bst_no_subdiv_only_selected
|
||||
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.create_ortho_camera", text="Create Ortho Camera", icon='OUTLINER_DATA_CAMERA')
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.free_gpu", text="Free GPU", icon='MEMORY')
|
||||
|
||||
# Materials section
|
||||
box = layout.box()
|
||||
box.label(text="Materials")
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.remove_unused_material_slots", text="Remove Unused Material Slots", icon='MATERIAL')
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.find_material_users", text="Find Material Users", icon='VIEWZOOM')
|
||||
|
||||
# Animation Data section
|
||||
box = layout.box()
|
||||
box.label(text="Animation Data")
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.delete_single_keyframe_actions", text="Delete Single Keyframe Actions", icon='ANIM_DATA')
|
||||
row = box.row(align=True)
|
||||
row.operator("bst.convert_relations_to_constraint", text="Convert Relations to Constraint", icon_value=405)
|
||||
|
||||
# List of all classes in this module
|
||||
classes = (
|
||||
BulkSceneGeneral,
|
||||
NoSubdiv, # Add NoSubdiv operator class
|
||||
RemoveCustomSplitNormals,
|
||||
CreateOrthoCamera,
|
||||
SpawnSceneStructure,
|
||||
DeleteSingleKeyframeActions,
|
||||
FindMaterialUsers,
|
||||
MATERIAL_USERS_OT_summary_dialog,
|
||||
RemoveUnusedMaterialSlots,
|
||||
ConvertRelationsToConstraint,
|
||||
)
|
||||
|
||||
# Registration
|
||||
def register():
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
# Register the window manager property for the checkbox
|
||||
bpy.types.WindowManager.bst_no_subdiv_only_selected = bpy.props.BoolProperty(
|
||||
name="Selected Only",
|
||||
description="Apply only to selected objects",
|
||||
default=True
|
||||
)
|
||||
# Register temporary material property for Find Material Users operator
|
||||
bpy.types.Scene.bst_temp_material = bpy.props.PointerProperty(
|
||||
name="Temporary Material",
|
||||
description="Temporary material selection for Find Material Users operator",
|
||||
type=bpy.types.Material
|
||||
)
|
||||
|
||||
def unregister():
|
||||
for cls in reversed(classes):
|
||||
try:
|
||||
bpy.utils.unregister_class(cls)
|
||||
except RuntimeError:
|
||||
pass
|
||||
# Unregister the window manager property
|
||||
if hasattr(bpy.types.WindowManager, "bst_no_subdiv_only_selected"):
|
||||
del bpy.types.WindowManager.bst_no_subdiv_only_selected
|
||||
# Unregister temporary material property
|
||||
if hasattr(bpy.types.Scene, "bst_temp_material"):
|
||||
del bpy.types.Scene.bst_temp_material
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,51 +0,0 @@
|
||||
# Raincloud's Bulk Scene Tools
|
||||
|
||||
A couple Blender tools to help me automate some tedious tasks in scene optimization.
|
||||
|
||||
## Features
|
||||
|
||||
- Bulk Data Remap
|
||||
- Bulk Viewport Display
|
||||
- Automatic update checking and one-click updates from GitHub releases
|
||||
|
||||
Officially supports Blender 4.4.1, but may still work on older versions.
|
||||
|
||||
## Installation
|
||||
|
||||
1. Download the addon (zip file)
|
||||
2. In Blender, go to Edit > Preferences > Add-ons
|
||||
3. Click "Install..." and select the downloaded zip file, or click and drag if it allows.
|
||||
4. Ensure addon is enabled.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Open blender file/scene to optimize
|
||||
2. Open side panel > Edit tab > Bulk Scene Tools
|
||||
3. Data remapper: Select data types to remap. Currently supports Images, Materials, and Fonts. Select to exclude data type from remapping.
|
||||
4. View amount of duplicates and use the dropdown menus to select which duplicate groups to exclude from remapping.
|
||||
5. Remap. This action is undo-able!
|
||||
6. If remapping has successfully remapped to your liking, Purge Unused Data so that the Viewport Display function has less materials to calculate, unless you are applying it only to selected objects.
|
||||
7. Recommend activating Solid viewport shading mode so you can see what the Material Viewport function is doing. Change color from Material to Texture if you prefer; the function should find the diffuse texture if one exists.
|
||||
8. Apply material calculation to selected objects if preferred.
|
||||
9. Manually set display color for objects that couldn't be calculated, or weren't calculated to your preference.
|
||||
|
||||
## Workflow for unpacking and organizing all textures
|
||||
|
||||
1. Pack all images (File > external data > pack resources, or BST > Bulk Path Management > Workflow > Pack)
|
||||
2. Rename all image (datablocks) as preferred (can be easily done within the Bulk Operations dropdown, but I also recommend the Simple Renaming extension available from the Blender community)
|
||||
3. Remap all image paths as preferred (Bulk Operations)
|
||||
4. Bulk Path Management > Save All (If selected, will save selected, if none are selected, will save all images in file)
|
||||
5. Remove pack
|
||||
|
||||
### Updating the addon
|
||||
|
||||
The addon will automatically check for updates when Blender starts. You can also:
|
||||
|
||||
1. Go to Edit > Preferences > Add-ons
|
||||
2. Find "Raincloud's Bulk Scene Tools" in the list
|
||||
3. In the addon preferences, click "Check Now" to check for updates
|
||||
4. If an update is available, click "Install Update" to download and install it
|
||||
|
||||
## Author
|
||||
|
||||
- **RaincloudTheDragon**
|
||||
@@ -1 +0,0 @@
|
||||
requests>=2.25.0
|
||||
@@ -1,236 +0,0 @@
|
||||
import bpy # type: ignore
|
||||
import requests # type: ignore
|
||||
import zipfile
|
||||
import tempfile
|
||||
import os
|
||||
import shutil
|
||||
import json
|
||||
from bpy.app.handlers import persistent # type: ignore
|
||||
import threading
|
||||
import time
|
||||
|
||||
# Updater configuration
|
||||
GITHUB_REPO = "RaincloudTheDragon/Rainys-Bulk-Scene-Tools"
|
||||
GITHUB_API_URL = f"https://api.github.com/repos/{GITHUB_REPO}/releases/latest"
|
||||
UPDATE_CHECK_INTERVAL = 86400 # 24 hours in seconds
|
||||
|
||||
# Updater state tracking
|
||||
class UpdaterState:
|
||||
checking_for_updates = False
|
||||
update_available = False
|
||||
update_version = ""
|
||||
update_download_url = ""
|
||||
error_message = ""
|
||||
last_check_time = 0
|
||||
|
||||
def get_current_version():
|
||||
"""Get the current addon version as a string"""
|
||||
from .. import bl_info
|
||||
version = bl_info["version"]
|
||||
return ".".join(str(v) for v in version)
|
||||
|
||||
def version_tuple_from_string(version_str):
|
||||
"""Convert a version string to a tuple for comparison"""
|
||||
try:
|
||||
return tuple(int(n) for n in version_str.split('.'))
|
||||
except:
|
||||
return (0, 0, 0)
|
||||
|
||||
def check_for_updates(async_check=True):
|
||||
"""Check for updates on GitHub"""
|
||||
if async_check:
|
||||
thread = threading.Thread(target=_check_for_updates_async)
|
||||
thread.daemon = True
|
||||
thread.start()
|
||||
else:
|
||||
return _check_for_updates_async()
|
||||
|
||||
def _check_for_updates_async():
|
||||
"""Check for updates asynchronously"""
|
||||
UpdaterState.checking_for_updates = True
|
||||
UpdaterState.error_message = ""
|
||||
|
||||
try:
|
||||
current_version = get_current_version()
|
||||
current_version_tuple = version_tuple_from_string(current_version)
|
||||
|
||||
# Request the latest release info from GitHub
|
||||
headers = {}
|
||||
response = requests.get(GITHUB_API_URL, headers=headers, timeout=10)
|
||||
response.raise_for_status()
|
||||
|
||||
release_data = response.json()
|
||||
latest_version = release_data["tag_name"].lstrip('v')
|
||||
latest_version_tuple = version_tuple_from_string(latest_version)
|
||||
|
||||
# Check if update is available
|
||||
if latest_version_tuple > current_version_tuple:
|
||||
UpdaterState.update_available = True
|
||||
UpdaterState.update_version = latest_version
|
||||
|
||||
# Get the zip file URL
|
||||
for asset in release_data["assets"]:
|
||||
if asset["name"].endswith(".zip"):
|
||||
UpdaterState.update_download_url = asset["browser_download_url"]
|
||||
break
|
||||
|
||||
if not UpdaterState.update_download_url:
|
||||
UpdaterState.update_download_url = release_data["zipball_url"]
|
||||
else:
|
||||
UpdaterState.update_available = False
|
||||
|
||||
UpdaterState.last_check_time = time.time()
|
||||
result = True
|
||||
|
||||
except Exception as e:
|
||||
UpdaterState.error_message = str(e)
|
||||
result = False
|
||||
|
||||
UpdaterState.checking_for_updates = False
|
||||
return result
|
||||
|
||||
def download_and_install_update():
|
||||
"""Download and install the addon update"""
|
||||
if not UpdaterState.update_available or not UpdaterState.update_download_url:
|
||||
return False
|
||||
|
||||
try:
|
||||
# Create a temporary directory
|
||||
temp_dir = tempfile.mkdtemp()
|
||||
temp_zip_path = os.path.join(temp_dir, "addon_update.zip")
|
||||
|
||||
# Download the zip file
|
||||
response = requests.get(UpdaterState.update_download_url, stream=True, timeout=60)
|
||||
response.raise_for_status()
|
||||
|
||||
with open(temp_zip_path, 'wb') as f:
|
||||
for chunk in response.iter_content(chunk_size=8192):
|
||||
f.write(chunk)
|
||||
|
||||
# Get the addon directory
|
||||
addon_dir = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
|
||||
|
||||
# Extract to temporary location
|
||||
extract_dir = os.path.join(temp_dir, "extracted")
|
||||
with zipfile.ZipFile(temp_zip_path, 'r') as zip_ref:
|
||||
zip_ref.extractall(extract_dir)
|
||||
|
||||
# Find the addon root in the extracted files
|
||||
addon_root = None
|
||||
for root, dirs, files in os.walk(extract_dir):
|
||||
if "__init__.py" in files:
|
||||
# Found potential addon root
|
||||
with open(os.path.join(root, "__init__.py"), 'r') as f:
|
||||
content = f.read()
|
||||
if "bl_info" in content:
|
||||
addon_root = root
|
||||
break
|
||||
|
||||
if not addon_root:
|
||||
# Try with the first directory if no clear addon root was found
|
||||
for item in os.listdir(extract_dir):
|
||||
if os.path.isdir(os.path.join(extract_dir, item)):
|
||||
addon_root = os.path.join(extract_dir, item)
|
||||
break
|
||||
|
||||
if not addon_root:
|
||||
raise Exception("Could not find addon root in the downloaded files")
|
||||
|
||||
# Copy files to addon directory
|
||||
# First, remove all old files except user settings
|
||||
for item in os.listdir(addon_dir):
|
||||
if item == "__pycache__":
|
||||
continue # Skip pycache
|
||||
item_path = os.path.join(addon_dir, item)
|
||||
if os.path.isfile(item_path):
|
||||
os.remove(item_path)
|
||||
elif os.path.isdir(item_path) and item != "user_settings":
|
||||
shutil.rmtree(item_path)
|
||||
|
||||
# Copy new files
|
||||
for item in os.listdir(addon_root):
|
||||
s = os.path.join(addon_root, item)
|
||||
d = os.path.join(addon_dir, item)
|
||||
if os.path.isfile(s):
|
||||
shutil.copy2(s, d)
|
||||
elif os.path.isdir(s):
|
||||
shutil.copytree(s, d)
|
||||
|
||||
# Clean up
|
||||
shutil.rmtree(temp_dir)
|
||||
|
||||
# Mark for reload
|
||||
bpy.ops.script.reload()
|
||||
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
UpdaterState.error_message = str(e)
|
||||
if 'temp_dir' in locals() and os.path.exists(temp_dir):
|
||||
shutil.rmtree(temp_dir)
|
||||
return False
|
||||
|
||||
@persistent
|
||||
def check_for_updates_handler(dummy):
|
||||
"""Handler to check for updates when Blender starts"""
|
||||
# Wait a bit to let Blender start up properly
|
||||
def delayed_check():
|
||||
time.sleep(2) # Wait 2 seconds after startup
|
||||
if time.time() - UpdaterState.last_check_time > UPDATE_CHECK_INTERVAL:
|
||||
check_for_updates()
|
||||
|
||||
thread = threading.Thread(target=delayed_check)
|
||||
thread.daemon = True
|
||||
thread.start()
|
||||
|
||||
# Add handler to check for updates on Blender startup
|
||||
if check_for_updates_handler not in bpy.app.handlers.load_post:
|
||||
bpy.app.handlers.load_post.append(check_for_updates_handler)
|
||||
|
||||
# Updater operators
|
||||
class BST_OT_CheckForUpdates(bpy.types.Operator):
|
||||
"""Check for updates for Raincloud's Bulk Scene Tools"""
|
||||
bl_idname = "bst.check_for_updates"
|
||||
bl_label = "Check for Updates"
|
||||
bl_description = "Check for new versions of the addon"
|
||||
|
||||
def execute(self, context):
|
||||
# Run synchronously for direct feedback
|
||||
if check_for_updates(async_check=False):
|
||||
if UpdaterState.update_available:
|
||||
self.report({'INFO'}, f"Update available: v{UpdaterState.update_version}")
|
||||
else:
|
||||
self.report({'INFO'}, "No updates available")
|
||||
else:
|
||||
self.report({'ERROR'}, f"Error checking for updates: {UpdaterState.error_message}")
|
||||
return {'FINISHED'}
|
||||
|
||||
class BST_OT_InstallUpdate(bpy.types.Operator):
|
||||
"""Install available update for Raincloud's Bulk Scene Tools"""
|
||||
bl_idname = "bst.install_update"
|
||||
bl_label = "Install Update"
|
||||
bl_description = "Download and install the latest version"
|
||||
|
||||
def execute(self, context):
|
||||
if download_and_install_update():
|
||||
self.report({'INFO'}, "Update installed successfully. Restart Blender to complete update.")
|
||||
return {'FINISHED'}
|
||||
else:
|
||||
self.report({'ERROR'}, f"Error installing update: {UpdaterState.error_message}")
|
||||
return {'CANCELLED'}
|
||||
|
||||
# List of classes in this module
|
||||
classes = (
|
||||
BST_OT_CheckForUpdates,
|
||||
BST_OT_InstallUpdate,
|
||||
)
|
||||
|
||||
def register():
|
||||
"""Register all classes in this module"""
|
||||
for cls in classes:
|
||||
bpy.utils.register_class(cls)
|
||||
|
||||
def unregister():
|
||||
"""Unregister all classes in this module"""
|
||||
for cls in reversed(classes):
|
||||
bpy.utils.unregister_class(cls)
|
||||
Reference in New Issue
Block a user